Light Field Networks
Project Page | Paper | Data | Pretrained Models
Vincent Sitzmann*, Semon Rezchikov*, William Freeman, Joshua Tenenbaum, Frédo Durand
MIT, *denotes equal contribution
This is the official implementation of the paper "Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering".
Get started
You can set up a conda environment with all dependencies like so:
conda env create -f environment.yml
conda activate siren
High-Level structure
The code is organized as follows:
- multiclass_dataio.py and dataio.py contain the dataio for mutliclass- and single-class experiments respectively.
- models.py contains the code for light field networks.
- training.py contains a generic training routine.
- ./experiment_scripts/ contains scripts to reproduce experiments in the paper.
Reproducing experiments
The directory experiment_scripts contains one script per experiment in the paper.
train_single_class.py trains a model on classes in the Scene Representation Networks format, such as cars or chairs. Note that since these datasets have a resolution of 128, this model starts with a lower resolution (64) and then increases the resolution to 128 (see line 43 in the script).
train_nmr.py trains a model on the NMR dataset. An example call is:
python experiment_scripts/train_nmr.py --data_root=path_to_nmr_dataset
python experiment_scripts/train_single_class.py --data_root=path_to_single_class
To reconstruct test objects, use the scripts "rec_single_class.py" and "rec_nmr.py". In addition to the data root, you have to point these scripts to the checkpoint from the training run. Note that the rec_nmr.py script uses the viewlist under ./experiment_scripts/viewlists/src_dvr.txt to pick which views to reconstruct the objects from, while rec_single_class.py per default reconstructs from the view with index 64.
python experiment_scripts/rec_nmr.py --data_root=path_to_nmr_dataset --checkpoint=path_to_training_checkpoint
python experiment_scripts/rec_single_class.py --data_root=path_to_single_class_TEST_SET --checkpoint=path_to_training_checkpoint
Finally, you may test the models on the test set with the test.py script. This script is used for testing all the models. You have to pass it as a parameter which dataset you are reconstructing ("NMR" or no). For the NMR dataset, you need to pass the "viewlist" again to make sure that the model is not evaluated on the context view.
python experiment_scripts/test.py --data_root=path_to_nmr_dataset --dataset=NMR --checkpoint=path_to_rec_checkpoint
python experiment_scripts/test.py --data_root=path_to_single_class_TEST_SET --dataset=single --checkpoint=path_to_rec_checkpoint
To monitor progress, both the training and reconstruction scripts write tensorboard summaries into a "summaries" subdirectory in the logging_root.
Bells & whistles
This code has a bunch of options that were not discussed in the paper.
- switch between a ReLU network and a SIREN to better fit high-frequency content with the flag --network (see the init of model.py for options).
- switch between a hypernetwork, conditioning via concatenation, and low-rank concditioning with the flag --conditioning
- there is an implementation of encoder-based inference in models.py (LFEncoder) which uses a ResNet18 with global conditioning to generate the latent codes z.
Data
We use two types of datasets: class-specific ones and multi-class ones.
- The class-specific ones are loaded via dataio.py, and we provide them in a fast-to-load hdf5 format in our google drive.
- For the multiclass experiment, we use the ShapeNet 64x64 dataset from NMR https://s3.eu-central-1.amazonaws.com/avg-projects/differentiable_volumetric_rendering/data/NMR_Dataset.zip (Hosted by DVR authors). Additionally, you will need to place the intrinsics.txt file that you can find in the google drive in the nmr root directory.
Coordinate and camera parameter conventions
This code uses an "OpenCV" style camera coordinate system, where the Y-axis points downwards (the up-vector points in the negative Y-direction), the X-axis points right, and the Z-axis points into the image plane. Camera poses are assumed to be in a "camera2world" format, i.e., they denote the matrix transform that transforms camera coordinates to world coordinates.
Misc
Citation
If you find our work useful in your research, please cite:
@inproceedings{sitzmann2021lfns,
author = {Sitzmann, Vincent
and Rezchikov, Semon
and Freeman, William T.
and Tenenbaum, Joshua B.
and Durand, Fredo},
title = {Light Field Networks: Neural Scene Representations
with Single-Evaluation Rendering},
booktitle = {Proc. NeurIPS},
year={2021}
}
Contact
If you have any questions, please email Vincent Sitzmann at [email protected].



 and the camera position (t) should be:
and the camera position (t) should be:
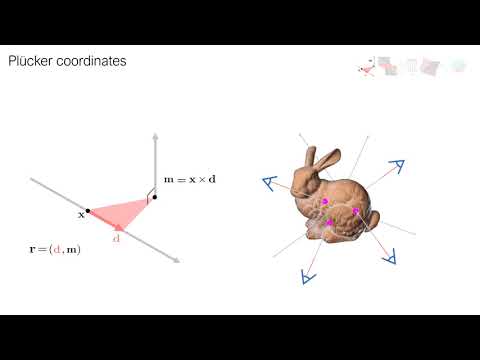
 so the Plücker coordinates is (d, d x t)?
so the Plücker coordinates is (d, d x t)?



 49 Nov 23, 2022
49 Nov 23, 2022
 272 Dec 28, 2022
272 Dec 28, 2022
 201 Dec 21, 2022
201 Dec 21, 2022
 364 Dec 14, 2022
364 Dec 14, 2022
 111 Dec 31, 2022
111 Dec 31, 2022
 35 Dec 6, 2022
35 Dec 6, 2022
 59 Dec 17, 2022
59 Dec 17, 2022
 307 Jan 3, 2023
307 Jan 3, 2023
 243 Dec 26, 2022
243 Dec 26, 2022
 153 Dec 14, 2022
153 Dec 14, 2022
 367 Dec 27, 2022
367 Dec 27, 2022
 1k Dec 31, 2022
1k Dec 31, 2022
 59 Sep 25, 2022
59 Sep 25, 2022
 29 Sep 2, 2022
29 Sep 2, 2022
 109 Dec 23, 2022
109 Dec 23, 2022
 574 Jan 2, 2023
574 Jan 2, 2023
 115 Dec 28, 2022
115 Dec 28, 2022
 49 Dec 1, 2022
49 Dec 1, 2022