StreamYOLO
Real-time Object Detection for Streaming Perception

Jinrong Yang, Songtao Liu, Zeming Li, Xiaoping Li, Sun Jian
Real-time Object Detection for Streaming Perception, CVPR 2022 (Oral)
Paper
Benchmark
| Model | size | velocity | sAP 0.5:0.95 |
sAP50 | sAP75 | weights | COCO pretrained weights |
|---|---|---|---|---|---|---|---|
| StreamYOLO-s | 600×960 | 1x | 29.8 | 50.3 | 29.8 | github | github |
| StreamYOLO-m | 600×960 | 1x | 33.7 | 54.5 | 34.0 | github | github |
| StreamYOLO-l | 600×960 | 1x | 36.9 | 58.1 | 37.5 | github | github |
| StreamYOLO-l | 600×960 | 2x | 34.6 | 56.3 | 34.7 | github | github |
| StreamYOLO-l | 600×960 | still | 39.4 | 60.0 | 40.2 | github | github |
Quick Start
Dataset preparation
You can download Argoverse-1.1 full dataset and annotation from HERE and unzip it.
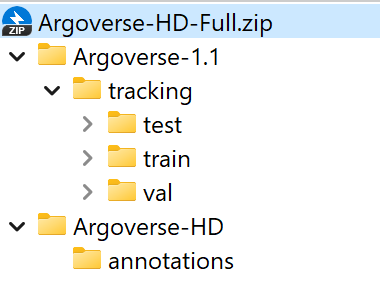
The folder structure should be organized as follows before our processing.
StreamYOLO
├── exps
├── tools
├── yolox
├── data
│ ├── Argoverse-1.1
│ │ ├── annotations
│ │ ├── tracking
│ │ ├── train
│ │ ├── val
│ │ ├── test
│ ├── Argoverse-HD
│ │ ├── annotations
│ │ ├── test-meta.json
│ │ ├── train.json
│ │ ├── val.json
The hash strings represent different video sequences in Argoverse, and ring_front_center is one of the sensors for that sequence. Argoverse-HD annotations correspond to images from this sensor. Information from other sensors (other ring cameras or LiDAR) is not used, but our framework can be also extended to these modalities or to a multi-modality setting.
Installation
# basic python libraries
conda create --name streamyolo python=3.7
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
pip3 install yolox==0.3
git clone [email protected]:yancie-yjr/StreamYOLO.git
cd StreamYOLO/
# add StreamYOLO to PYTHONPATH and add this line to ~/.bashrc or ~/.zshrc (change the file accordingly)
ADDPATH=$(pwd)
echo export PYTHONPATH=$PYTHONPATH:$ADDPATH >> ~/.bashrc
source ~/.bashrc
# Installing `mmcv` for the official sAP evaluation:
# Please replace `{cu_version}` and ``{torch_version}`` with the versions you are currently using.
# You will get import or runtime errors if the versions are incorrect.
pip install mmcv-full==1.1.5 -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html
Reproduce our results on Argoverse-HD
Step1. Prepare COCO dataset
cd <StreamYOLO_HOME>
ln -s /path/to/your/Argoverse-1.1 ./data/Argoverse-1.1
ln -s /path/to/your/Argoverse-HD ./data/Argoverse-HD
Step2. Reproduce our results on Argoverse:
python tools/train.py -f cfgs/m_s50_onex_dfp_tal_flip.py -d 8 -b 32 -c [/path/to/your/coco_pretrained_path] -o --fp16
- -d: number of gpu devices.
- -b: total batch size, the recommended number for -b is num-gpu * 8.
- --fp16: mixed precision training.
- -c: model checkpoint path.
Offline Evaluation
We support batch testing for fast evaluation:
python tools/eval.py -f cfgs/l_s50_onex_dfp_tal_flip.py -c [/path/to/your/model_path] -b 64 -d 8 --conf 0.01 [--fp16] [--fuse]
- --fuse: fuse conv and bn.
- -d: number of GPUs used for evaluation. DEFAULT: All GPUs available will be used.
- -b: total batch size across on all GPUs.
- -c: model checkpoint path.
- --conf: NMS threshold. If using 0.001, the performance will further improve by 0.2~0.3 sAP.
Online Evaluation
We modify the online evaluation from sAP
Please use 1 V100 GPU to test the performance since other GPUs with low computing power will trigger non-real-time results!!!!!!!!
cd sAP/streamyolo
bash streamyolo.sh
Citation
Please cite the following paper if this repo helps your research:
@InProceedings{streamyolo,
author = {Yang, Jinrong and Liu, Songtao and Li, Zeming and Li, Xiaoping and Sun, Jian},
title = {Real-time Object Detection for Streaming Perception},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2022}
}
License
This repo is released under the Apache 2.0 license. Please see the LICENSE file for more information.






 87 Jan 8, 2023
87 Jan 8, 2023
 300 Dec 15, 2022
300 Dec 15, 2022
 96 Jan 3, 2023
96 Jan 3, 2023
 85 Dec 22, 2022
85 Dec 22, 2022
 1 Dec 29, 2021
1 Dec 29, 2021
 147 Dec 3, 2022
147 Dec 3, 2022
 2 Feb 18, 2022
2 Feb 18, 2022
 294 Jan 1, 2023
294 Jan 1, 2023
 1 Feb 15, 2022
1 Feb 15, 2022
 156 Dec 28, 2022
156 Dec 28, 2022
 34 Nov 9, 2022
34 Nov 9, 2022
 21 Dec 22, 2022
21 Dec 22, 2022
 7 Oct 30, 2022
7 Oct 30, 2022
 13 Nov 29, 2022
13 Nov 29, 2022
 64 Jan 7, 2023
64 Jan 7, 2023
 141 Dec 30, 2022
141 Dec 30, 2022
 280 Jan 7, 2023
280 Jan 7, 2023
 107 Dec 20, 2022
107 Dec 20, 2022
 69 Oct 19, 2022
69 Oct 19, 2022