PP-Tracking GUI界面测试版
本项目是基于飞桨开源的实时跟踪系统PP-Tracking开发的可视化界面
在PaddlePaddle中加入pyqt进行GUI页面研发,可使得整个训练过程可视化,并通过GUI界面进行调参,模型预测,视频输出等,通过多种类型的识别,简化整体预测流程。
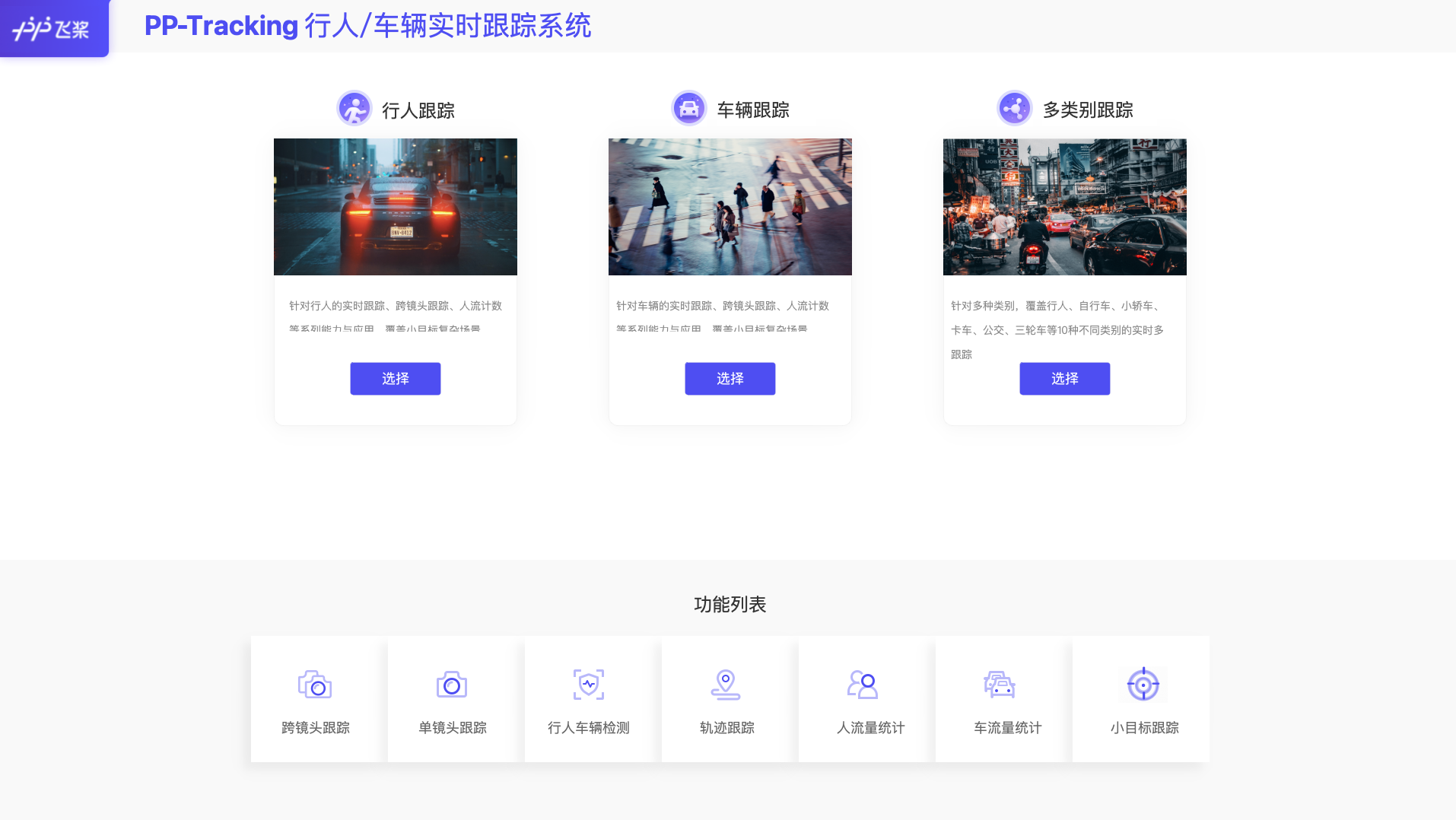
GUI界面基于PyQT和PP-Tracking python部署代码开发;当前覆盖单镜头的全部功能,如行人跟踪,车辆跟踪,流量统计等
推荐使用Windows环境
主要包含两个步骤:
- 导入训练模型,修改模型名称
- 安装必要的依赖库
- 启动前端界面
1. 下载预测模型
PP-Tracking 提供了覆盖多种场景的预测模型,用户可以根据自己的实际使用场景在链接中直接下载表格最后一列的预测部署模型
如果您想自己训练得到更符合您场景需求的模型,可以参考快速开始文档训练并导出预测模型
模型导出放在./output_inference目录下
2. 必要的依赖库安装
pyqt5
moviepy
opencv-python
PySide2
matplotlib
scipy
cython_bbox
paddlepaddle
注:
- Windows环境下,需要手动下载安装cython_bbox,然后将setup.py中的找到steup.py, 修改
extra_compile_args=[’-Wno-cpp’],替换为extra_compile_args = {'gcc': ['/Qstd=c99']}, 然后运行python setup.py build_ext install - numpy版本需要大于1.20
3. 启动前端界面
执行python main.py启动前端界面
参数说明如下:
| 参数 | 是否必须 | 含义 |
|---|---|---|
| 模型运行 | Option | 点击后进行模型训练 |
| 结果显示 | Option | 在运行状态为检测完成的时候进行结果视频显示 |
| 停止运行 | Option | 停止整个视频输出 |
| 取消轨迹 | Option | 在一开始时取消轨迹 |
| 阈值调试 | Option | 预测得分的阈值,默认为0.5 |
| 输入FPS | Option | 输入视频的FPS |
| 检测用时 | Option | 视频的检测时间 |
| 人流量检测 | Option | 每隔一段帧数内的人流量统计图表 |
| 时间长度 | Option | 人流量时间统计长度 |
| 开启出入口 | Option | 导入视频后可自行选择是否开启出入口训练 |
| 导出文件 | Option | 可视化结果保存的根目录,默认为output/ |
说明:
- 如果安装的PaddlePaddle不支持基于TensorRT进行预测,需要自行编译,详细可参考预测库编译教程。
- 建议使用windows环境进行运行

 13 Aug 18, 2022
13 Aug 18, 2022
 65 Dec 22, 2022
65 Dec 22, 2022

 1 Nov 22, 2021
1 Nov 22, 2021

 432 Dec 17, 2022
432 Dec 17, 2022

 105 Dec 23, 2022
105 Dec 23, 2022
 3.2k Jan 5, 2023
3.2k Jan 5, 2023
 27 Jul 7, 2022
27 Jul 7, 2022

 401 Jan 2, 2023
401 Jan 2, 2023

 148 Dec 21, 2022
148 Dec 21, 2022






 3 Jan 26, 2022
3 Jan 26, 2022
 41 Nov 23, 2022
41 Nov 23, 2022
 7 Jan 8, 2023
7 Jan 8, 2023
 305 Dec 16, 2022
305 Dec 16, 2022
 4 Feb 5, 2022
4 Feb 5, 2022
 443 Dec 6, 2022
443 Dec 6, 2022
 254 Dec 16, 2022
254 Dec 16, 2022
 1.6k Jan 4, 2023
1.6k Jan 4, 2023
 1 Dec 29, 2021
1 Dec 29, 2021
 44 Dec 9, 2022
44 Dec 9, 2022