"# bpe_algorithm_can_finetune_tokenizer"
this is an implyment for https://github.com/huggingface/transformers/issues/15153
I just add tens of lines of code into the py_bpe algorithm. function finetune_tokenizer is main function added.
Details can be see in example.py , actuctally it is very simple. the official python library tokenizer is written is rust. I am learning hoping to give a rust version of this code.
ps: the_factor_of_new_added_token_divided_unk_number is the only param you should set. hoping can find a auto algorithm to set it.
 325 Jan 5, 2023
325 Jan 5, 2023
 1 Aug 15, 2022
1 Aug 15, 2022
 34 Dec 18, 2022
34 Dec 18, 2022

 3 Mar 2, 2022
3 Mar 2, 2022

 9 Dec 8, 2022
9 Dec 8, 2022
 763 Dec 27, 2022
763 Dec 27, 2022

 2.4k Jan 6, 2023
2.4k Jan 6, 2023
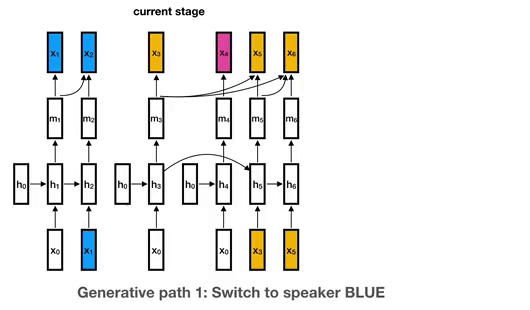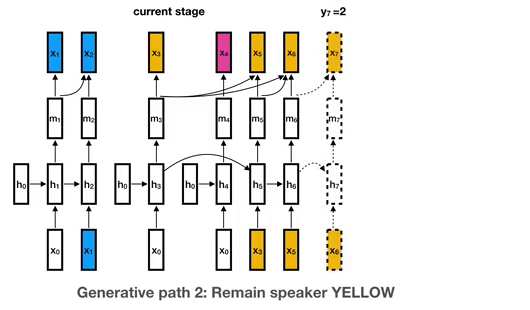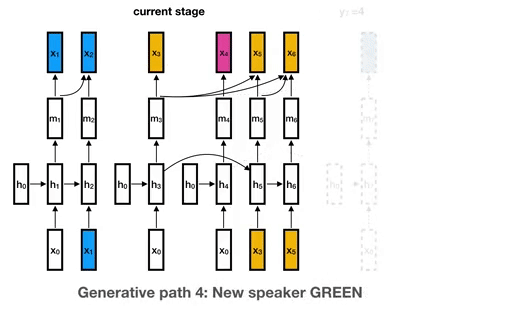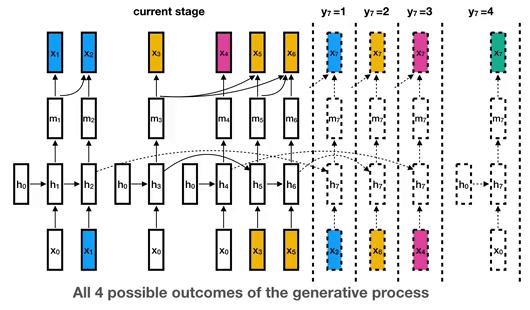
 1.4k Dec 28, 2022
1.4k Dec 28, 2022

 1.1k Jan 3, 2023
1.1k Jan 3, 2023
 289 Jan 6, 2023
289 Jan 6, 2023
 29 Oct 23, 2022
29 Oct 23, 2022
 27 Dec 14, 2022
27 Dec 14, 2022
 6.4k Jan 1, 2023
6.4k Jan 1, 2023
 847 Dec 19, 2022
847 Dec 19, 2022
 3 Dec 22, 2021
3 Dec 22, 2021
 435 Jan 6, 2023
435 Jan 6, 2023