One-Stage Visual Grounding
***** New: Our recent work on One-stage VG is available at ReSC.*****
A Fast and Accurate One-Stage Approach to Visual Grounding
by Zhengyuan Yang, Boqing Gong, Liwei Wang, Wenbing Huang, Dong Yu, and Jiebo Luo
IEEE International Conference on Computer Vision (ICCV), 2019, Oral
Introduction
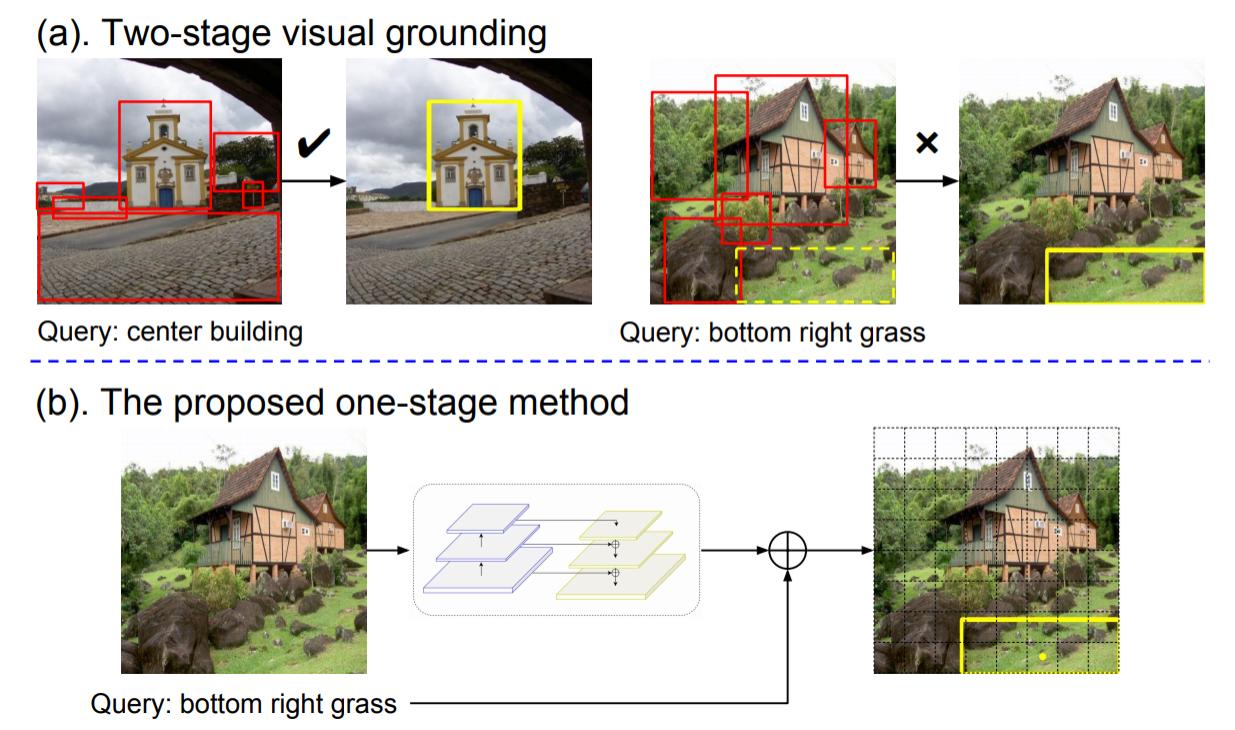
We propose a simple, fast, and accurate one-stage approach to visual grounding. For more details, please refer to our paper.
Citation
@inproceedings{yang2019fast,
title={A Fast and Accurate One-Stage Approach to Visual Grounding},
author={Yang, Zhengyuan and Gong, Boqing and Wang, Liwei and Huang
, Wenbing and Yu, Dong and Luo, Jiebo},
booktitle={ICCV},
year={2019}
}
Prerequisites
- Python 3.5 (3.6 tested)
- Pytorch 0.4.1
- Others (Pytorch-Bert, OpenCV, Matplotlib, scipy, etc.)
Installation
-
Clone the repository
git clone https://github.com/zyang-ur/onestage_grounding.git -
Prepare the submodules and associated data
- RefCOCO & ReferItGame Dataset: place the data or the soft link of dataset folder under
./ln_data/. We follow dataset structure DMS. To accomplish this, thedownload_dataset.shbash script from DMS can be used.bash ln_data/download_data.sh --path ./ln_data
-
Flickr30K Entities Dataset: please download the images for the dataset on the website for the Flickr30K Entities Dataset and the original Flickr30k Dataset. Images should be placed under
./ln_data/Flickr30k/flickr30k_images. -
Data index: download the generated index files and place them as the
./datafolder. Availble at [Gdrive], [One Drive].rm -r data tar xf data.tar -
Model weights: download the pretrained model of Yolov3 and place the file in
./saved_models.sh saved_models/yolov3_weights.sh
More pretrained models are availble in the performance table [Gdrive], [One Drive] and should also be placed in ./saved_models.
Training
-
Train the model, run the code under main folder. Using flag
--lstmto access lstm encoder, Bert is used as the default. Using flag--lightto access the light model.python train_yolo.py --data_root ./ln_data/ --dataset referit \ --gpu gpu_id --batch_size 32 --resume saved_models/lstm_referit_model.pth.tar \ --lr 1e-4 --nb_epoch 100 --lstm -
Evaluate the model, run the code under main folder. Using flag
--testto access test mode.python train_yolo.py --data_root ./ln_data/ --dataset referit \ --gpu gpu_id --resume saved_models/lstm_referit_model.pth.tar \ --lstm --test -
Visulizations. Flag
--save_plotwill save visulizations.
Performance and Pre-trained Models
Please check the detailed experiment settings in our paper.
| Dataset | Ours-LSTM | Performance ([email protected]) | Ours-Bert | Performance ([email protected]) |
|---|---|---|---|---|
| ReferItGame | Gdrive | 58.76 | Gdrive | 59.30 |
| Flickr30K Entities | One Drive | 67.62 | One Drive | 68.69 |
| RefCOCO | val: 73.66 | val: 72.05 | ||
| testA: 75.78 | testA: 74.81 | |||
| testB: 71.32 | testB: 67.59 |
Credits
Part of the code or models are from DMS, MAttNet, Yolov3 and Pytorch-yolov3.











 52 Dec 19, 2022
52 Dec 19, 2022
 71 Dec 14, 2022
71 Dec 14, 2022
 33 Dec 15, 2022
33 Dec 15, 2022
 264 Jan 9, 2023
264 Jan 9, 2023
 677 Dec 25, 2022
677 Dec 25, 2022
 108 Dec 27, 2022
108 Dec 27, 2022
 42 Jan 7, 2023
42 Jan 7, 2023
 87 Dec 16, 2022
87 Dec 16, 2022
 534 Dec 25, 2022
534 Dec 25, 2022
 291 Dec 24, 2022
291 Dec 24, 2022
 9 Nov 14, 2022
9 Nov 14, 2022
 22 Dec 11, 2022
22 Dec 11, 2022
 76 Dec 24, 2022
76 Dec 24, 2022
 44 Dec 12, 2022
44 Dec 12, 2022
 1 Jan 18, 2022
1 Jan 18, 2022
 833 Dec 28, 2022
833 Dec 28, 2022
 49 Dec 22, 2022
49 Dec 22, 2022
 1 Oct 5, 2022
1 Oct 5, 2022
 4 Aug 28, 2022
4 Aug 28, 2022