17 Repositories
Python diarization Libraries

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
 281 Dec 15, 2022
281 Dec 15, 2022
This repo contains simple to use, pretrained/training-less models for speaker diarization.
PyDiar This repo contains simple to use, pretrained/training-less models for speaker diarization. Supported Models Binary Key Speaker Modeling Based o
 12 Jan 20, 2022
12 Jan 20, 2022

The project is associated with the recently-launched ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge (M2MeT) to provide participants with baseline systems for speech recognition and speaker diarization in conference scenario.
M2MeT challenge baseline -- AliMeeting This project provides the baseline system recipes for the ICASSP 2020 Multi-channel Multi-party Meeting Transcr
 81 Dec 8, 2022
81 Dec 8, 2022
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
The SpeechBrain Toolkit SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch. The goal is to create a single, flexible, and us
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition Identify the emotion of multiple speakers in a Audio Segment Report Bug · Request Feature Try the Demo Here Table
 110 Dec 3, 2022
110 Dec 3, 2022
UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
33 Oct 14, 2021

Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
 187 Jan 6, 2023
187 Jan 6, 2023
Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
185 Jan 1, 2023
This repository contains a set of codes to run (i.e., train, perform inference with, evaluate) a diarization method called EEND-vector-clustering.
EEND-vector clustering The EEND-vector clustering (End-to-End-Neural-Diarization-vector clustering) is a speaker diarization framework that integrates
 45 Dec 26, 2022
45 Dec 26, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
 20 Dec 29, 2022
20 Dec 29, 2022

PyTorch implementation of Densely Connected Time Delay Neural Network
Densely Connected Time Delay Neural Network PyTorch implementation of Densely Connected Time Delay Neural Network (D-TDNN) in our paper "Densely Conne
 64 Oct 11, 2022
64 Oct 11, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition
111 Jan 7, 2023
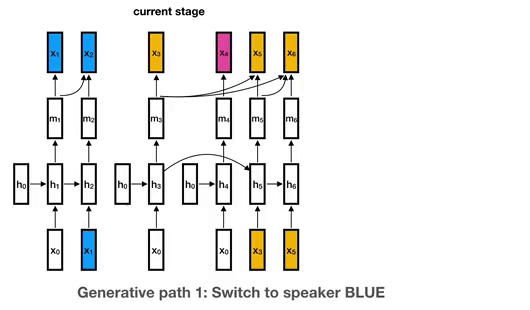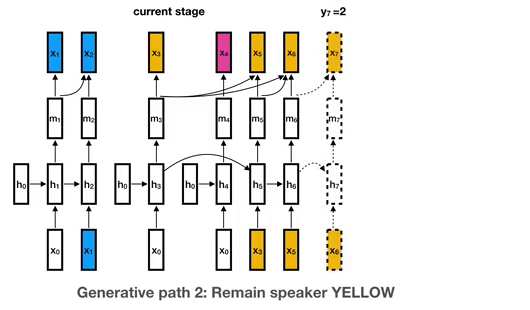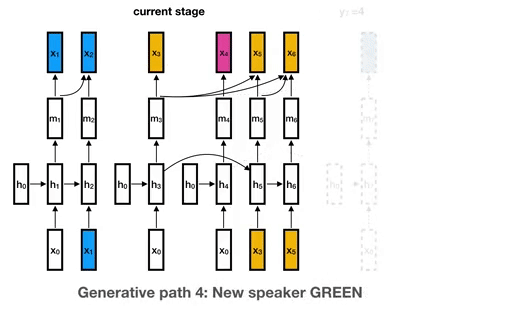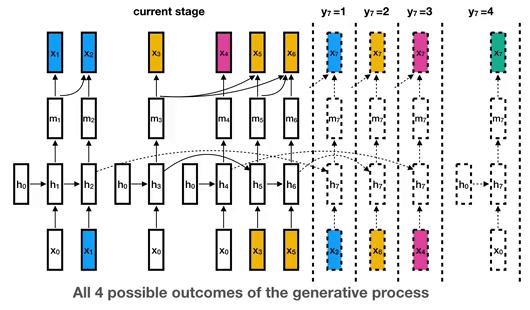
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
2.1k Dec 31, 2022