30 Repositories
Python etl Libraries
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022

Airflow ETL With EKS EFS Sagemaker
Airflow ETL With EKS EFS & Sagemaker (en desarrollo) Diagrama de la solución Imp
 1 Feb 14, 2022
1 Feb 14, 2022

Processo de ETL (extração, transformação, carregamento) realizado pela equipe no projeto final do curso da Soul Code Academy.
Processo de ETL (extração, transformação, carregamento) realizado pela equipe no projeto final do curso da Soul Code Academy.
 1 Feb 3, 2022
1 Feb 3, 2022
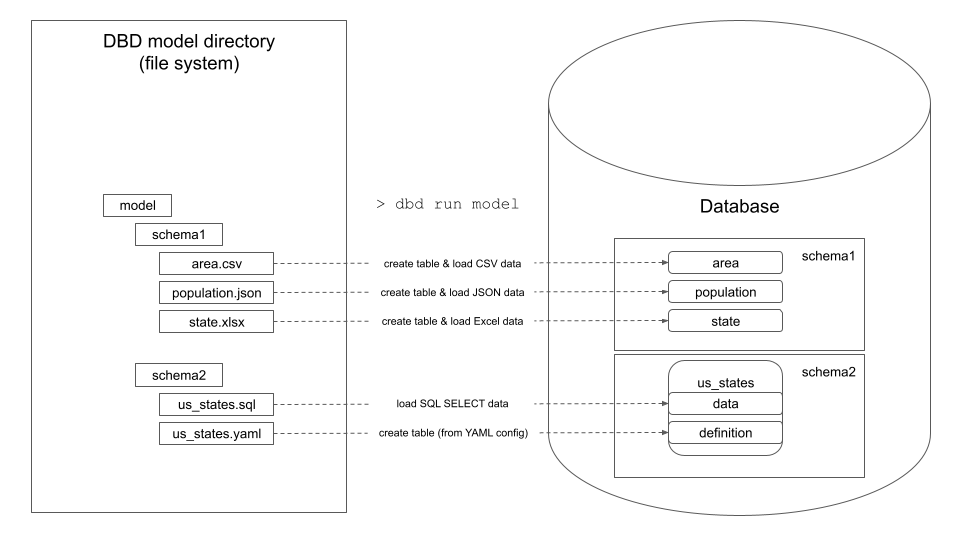
dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL databases.
dbd: database prototyping tool dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL d
 47 Dec 7, 2022
47 Dec 7, 2022

PrimaryBid - Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift
Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift This project is composed of two parts: Part1 and Part2
 1 Jan 19, 2022
1 Jan 19, 2022

songplays datamart provide details about the musical taste of our customers and can help us to improve our recomendation system
Songplays User activity datamart The following document describes the model used to build the songplays datamart table and the respective ETL process.
 1 Jul 13, 2021
1 Jul 13, 2021

ETL pipeline on movie data using Python and postgreSQL
Movies-ETL ETL pipeline on movie data using Python and postgreSQL Overview This project consisted on a automated Extraction, Transformation and Load p
 0 Jul 7, 2021
0 Jul 7, 2021
ETL for tononkira.serasera.org
python-tononkiramalagasy-api Api Endpoints: ### get artists - /artists/int:page [page_offset = 20] ### get artist's songs, index was given by
 1 Dec 24, 2021
1 Dec 24, 2021

AWS Glue ETL Code Samples
AWS Glue ETL Code Samples This repository has samples that demonstrate various aspects of the new AWS Glue service, as well as various AWS Glue utilit
 1.2k Jan 3, 2023
1.2k Jan 3, 2023
Singer is an open source standard for moving data between databases, web APIs, files, queues, and just about anything else you can think of.
Singer is an open source standard for moving data between databases, web APIs, files, queues, and just about anything else you can think of. Th
 1.1k Jan 5, 2023
1.1k Jan 5, 2023
An ETL framework + Monitoring UI/API (experimental project for learning purposes)
Fastlane An ETL framework for building pipelines, and Flask based web API/UI for monitoring pipelines. Project structure fastlane |- fastlane: (ETL fr
 2 Jan 6, 2022
2 Jan 6, 2022

APIlocal_dbAWS_RDS - Disclaimer! All data used is for educational purposes only.
APIlocal_dbAWS_RDS Disclaimer! All data used is for educational purposes only. ETL pipeline diagram. Aim of project By creating a fully working pipe
 0 Apr 25, 2022
0 Apr 25, 2022
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis.
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis. It is distributed under the MIT License.
 720 Dec 25, 2022
720 Dec 25, 2022
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
An orchestration platform for the development, production, and observation of data assets.
Dagster An orchestration platform for the development, production, and observation of data assets. Dagster lets you define jobs in terms of the data f
 6.2k Jan 8, 2023
6.2k Jan 8, 2023
In this project, ETL pipeline is build on data warehouse hosted on AWS Redshift.
ETL Pipeline for AWS Project Description In this project, ETL pipeline is build on data warehouse hosted on AWS Redshift. The data is loaded from S3 t
 1 Nov 1, 2021
1 Nov 1, 2021
A Big Data ETL project in PySpark on the historical NYC Taxi Rides data
Processing NYC Taxi Data using PySpark ETL pipeline Description This is an project to extract, transform, and load large amount of data from NYC Taxi
 2 Dec 12, 2021
2 Dec 12, 2021
wikirepo is a Python package that provides a framework to easily source and leverage standardized Wikidata information
Python based Wikidata framework for easy dataframe extraction wikirepo is a Python package that provides a framework to easily source and leverage sta
 35 Jan 4, 2023
35 Jan 4, 2023

ETL flow framework based on Yaml configs in Python
ETL framework based on Yaml configs in Python A light framework for creating data streams. Setting up streams through configuration in the Yaml file.
 18 Jul 6, 2022
18 Jul 6, 2022

A web scraping pipeline project that retrieves TV and movie data from two sources, then transforms and stores data in a MySQL database.
New to Streaming Scraper An in-progress web scraping project built with Python, R, and SQL. The scraped data are movie and TV show information. The go
 1 Mar 28, 2022
1 Mar 28, 2022
Eland is a Python Elasticsearch client for exploring and analyzing data in Elasticsearch with a familiar Pandas-compatible API.
Python Client and Toolkit for DataFrames, Big Data, Machine Learning and ETL in Elasticsearch
 463 Dec 30, 2022
463 Dec 30, 2022

Python ELT Studio, an application for building ELT (and ETL) data flows.
The Python Extract, Load, Transform Studio is an application for performing ELT (and ETL) tasks. Under the hood the application consists of a two parts.
 55 Nov 18, 2022
55 Nov 18, 2022
Pyspark Spotify ETL
This is my first Data Engineering project, it extracts data from the user's recently played tracks using Spotify's API, transforms data and then loads it into Postgresql using SQLAlchemy engine. Data is shown as a Spark Dataframe before loading and the whole ETL job is scheduled with crontab. Token never expires since an HTTP POST method with Spotify's token API is used in the beginning of the script.
 16 Jun 9, 2022
16 Jun 9, 2022
ETL python utilizando API do Spotify
Processo de ETL com Python e Airflow usando API do Spotify Sobre Projeto de ETL(Extract, Transform e Load) utilizando Python com API do Spotify e Airf
 10 Mar 16, 2022
10 Mar 16, 2022
Ethereum ETL lets you convert blockchain data into convenient formats like CSVs and relational databases.
Python scripts for ETL (extract, transform and load) jobs for Ethereum blocks, transactions, ERC20 / ERC721 tokens, transfers, receipts, logs, contracts, internal transactions.
 2.3k Jan 1, 2023
2.3k Jan 1, 2023

Educational project on how to build an ETL (Extract, Transform, Load) data pipeline, orchestrated with Airflow.
ETL Pipeline with Airflow, Spark, s3, MongoDB and Amazon Redshift
 214 Jan 2, 2023
214 Jan 2, 2023
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023
Pandas on AWS - Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
AWS Data Wrangler Pandas on AWS Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretMana
 3.3k Dec 31, 2022
3.3k Dec 31, 2022
Pandas on AWS - Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
AWS Data Wrangler Pandas on AWS Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretMana
3.3k Jan 4, 2023