12 Repositories
Python linguistics Libraries
WikiPron - a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary
WikiPron WikiPron is a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary, as well as a database of pronuncia
 213 Jan 1, 2023
213 Jan 1, 2023
ChirpText is a collection of text processing tools for Python 3.
ChirpText is a collection of text processing tools for Python 3. It is not meant to be a powerful tank like the popular NTLK but a small package which
 5 Nov 30, 2022
5 Nov 30, 2022
This repository details the steps in creating a Part of Speech tagger using Trigram Hidden Markov Models and the Viterbi Algorithm without using external libraries.
POS-Tagger This repository details the creation of a Part-of-Speech tagger using Trigram Hidden Markov Models to predict word tags in a word sequence.
 1 Dec 9, 2021
1 Dec 9, 2021
LILLIE: Information Extraction and Database Integration Using Linguistics and Learning-Based Algorithms
LILLIE: Information Extraction and Database Integration Using Linguistics and Learning-Based Algorithms Based on the work by Smith et al. (2021) Query
 5 Aug 6, 2022
5 Aug 6, 2022
PsychoPy is an open-source package for creating experiments in behavioral science.
PsychoPy is an open-source package for creating experiments in behavioral science. It aims to provide a single package that is: precise enoug
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Multimodal Descriptions of Social Concepts: Automatic Modeling and Detection of (Highly Abstract) Social Concepts evoked by Art Images
MUSCO - Multimodal Descriptions of Social Concepts Automatic Modeling of (Highly Abstract) Social Concepts evoked by Art Images This project aims to i
 0 Aug 22, 2021
0 Aug 22, 2021
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023
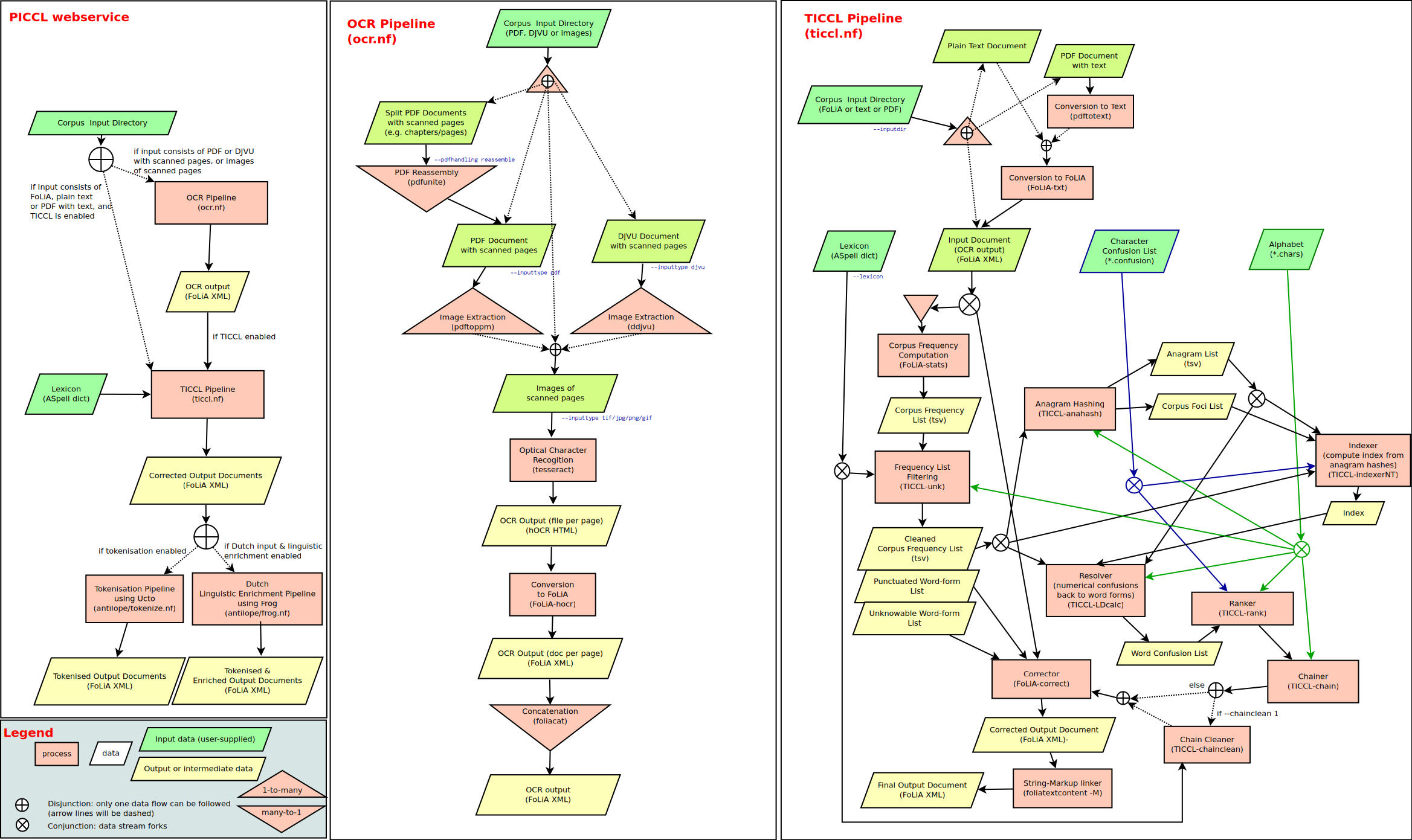
A set of workflows for corpus building through OCR, post-correction and normalisation
PICCL: Philosophical Integrator of Computational and Corpus Libraries PICCL offers a workflow for corpus building and builds on a variety of tools. Th
 41 Dec 27, 2022
41 Dec 27, 2022
The Classical Language Toolkit
Notice: This Git branch (dev) contains the CLTK's upcoming major release (v. 1.0.0). See https://github.com/cltk/cltk/tree/master and https://docs.clt
 629 Feb 17, 2021
629 Feb 17, 2021
Colibri core is an NLP tool as well as a C++ and Python library for working with basic linguistic constructions such as n-grams and skipgrams (i.e patterns with one or more gaps, either of fixed or dynamic size) in a quick and memory-efficient way. At the core is the tool ``colibri-patternmodeller`` whi ch allows you to build, view, manipulate and query pattern models.
Colibri Core by Maarten van Gompel, [email protected], Radboud University Nijmegen Licensed under GPLv3 (See http://www.gnu.org/licenses/gpl-3.0.html
 122 Nov 17, 2022
122 Nov 17, 2022
This is a Python binding to the tokenizer Ucto. Tokenisation is one of the first step in almost any Natural Language Processing task, yet it is not always as trivial a task as it appears to be. This binding makes the power of the ucto tokeniser available to Python. Ucto itself is regular-expression based, extensible, and advanced tokeniser written in C++ (http://ilk.uvt.nl/ucto).
Ucto for Python This is a Python binding to the tokeniser Ucto. Tokenisation is one of the first step in almost any Natural Language Processing task,
27 Dec 14, 2022