8 Repositories
Python multiband-hifigan Libraries
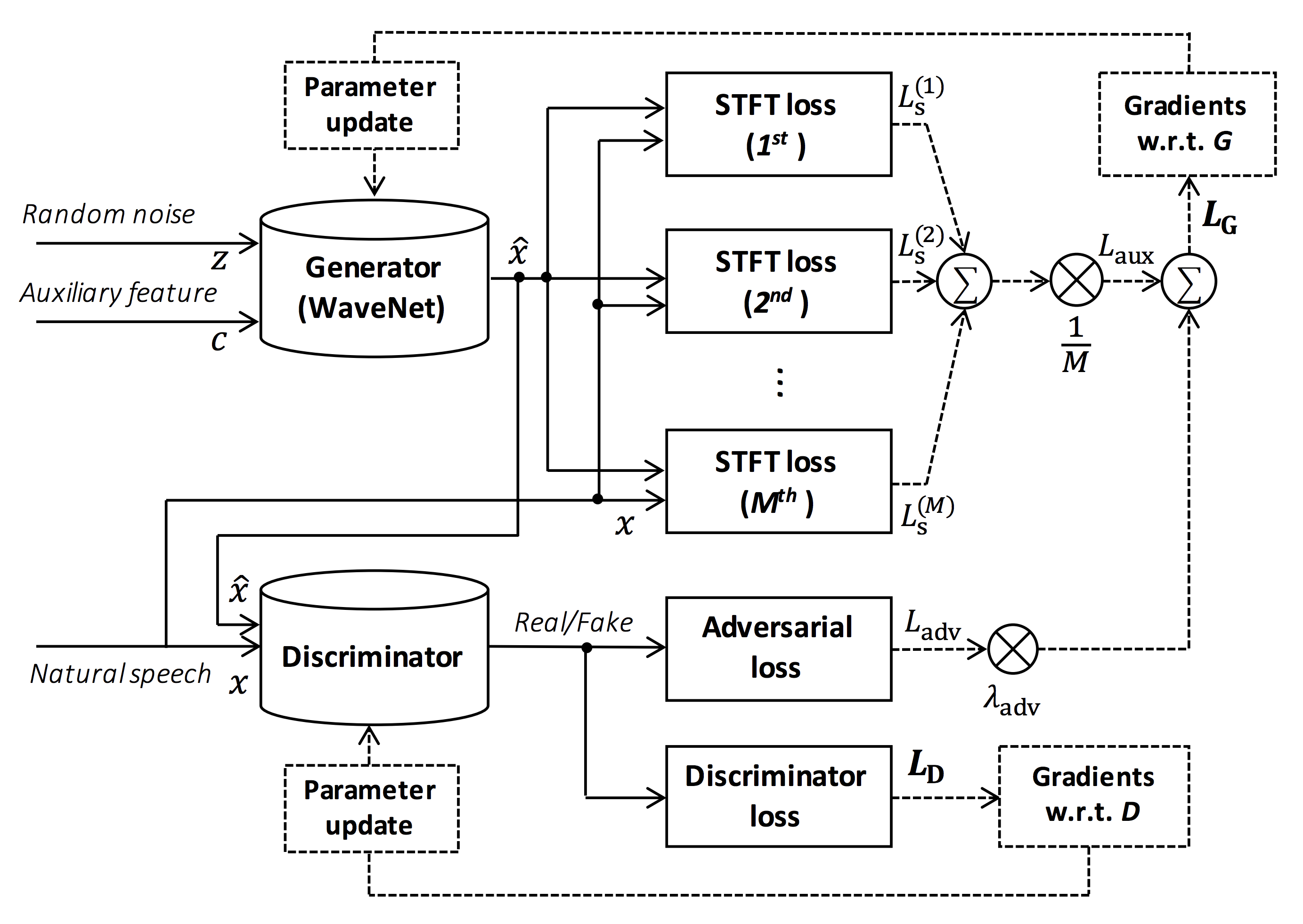
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022
Fast and Simple Neural Vocoder, the Multiband RNNMS
Multiband RNN_MS Fast and Simple vocoder, Multiband RNN_MS. Demo Quick training How to Use System Details Results References Demo ToDO: Link super gre
 5 Jan 11, 2022
5 Jan 11, 2022
Multiband spectro-radiometric satellite image analysis with K-means cluster algorithm
Multi-band Spectro Radiomertric Image Analysis with K-means Cluster Algorithm Overview Multi-band Spectro Radiomertric images are images comprising of
 6 Mar 16, 2022
6 Mar 16, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 31 Dec 8, 2022
31 Dec 8, 2022
Include MelGAN, HifiGAN and Multiband-HifiGAN, maybe NHV in the future.
Fast (GAN Based Neural) Vocoder Chinese README Todo Submit demo Support NHV Discription Include MelGAN, HifiGAN and Multiband-HifiGAN, maybe include N
 134 Dec 16, 2022
134 Dec 16, 2022

HiFi-GAN: High Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
HiFiGAN Denoiser This is a Unofficial Pytorch implementation of the paper HiFi-GAN: High Fidelity Denoising and Dereverberation Based on Speech Deep F
134 Dec 27, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
 6.5k Jan 8, 2023
6.5k Jan 8, 2023
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we can speed-up training/inference progress, optimizer further by using fake-quantize aware and pruning, make TTS models can be run faster than real-time and be able to deploy on mobile devices or embedded systems.
 3k Jan 4, 2023
3k Jan 4, 2023