23 Repositories
Python vqa Libraries
Code and Experiments for ACL-IJCNLP 2021 Paper Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering.
Code and Experiments for ACL-IJCNLP 2021 Paper Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering.
 50 Nov 16, 2022
50 Nov 16, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023

An easy-to-use app to visualise attentions of various VQA models.
Ask Me Anything: A tool for visualising Visual Question Answering (AMA) An easy-to-use app to visualise attentions of various VQA models. Please click
 37 Nov 13, 2022
37 Nov 13, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
 938 Dec 26, 2022
938 Dec 26, 2022

PyTorch implementation of "Debiased Visual Question Answering from Feature and Sample Perspectives" (NeurIPS 2021)
D-VQA We provide the PyTorch implementation for Debiased Visual Question Answering from Feature and Sample Perspectives (NeurIPS 2021). Dependencies P
 19 Dec 22, 2022
19 Dec 22, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
 87 Jan 5, 2023
87 Jan 5, 2023
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
 5.1k Jan 4, 2023
5.1k Jan 4, 2023
New approach to benchmark VQA models
VQA Benchmarking This repository contains the web application & the python interface to evaluate VQA models. Documentation Please see the documentatio
 4 Jul 25, 2022
4 Jul 25, 2022

This is the official pytorch implementation for our ICCV 2021 paper "TRAR: Routing the Attention Spans in Transformers for Visual Question Answering" on VQA Task
🌈 ERASOR (RA-L'21 with ICRA Option) Official page of "ERASOR: Egocentric Ratio of Pseudo Occupancy-based Dynamic Object Removal for Static 3D Point C
 225 Dec 29, 2022
225 Dec 29, 2022
CVPR2020 Counterfactual Samples Synthesizing for Robust VQA
CVPR2020 Counterfactual Samples Synthesizing for Robust VQA This repo contains code for our paper "Counterfactual Samples Synthesizing for Robust Visu
 72 Dec 22, 2022
72 Dec 22, 2022
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
 166 Dec 11, 2022
166 Dec 11, 2022
In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset.
Med-VQA In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset. Two of these are made on top of Facebook AI Reasearch's Multi-Mo
 8 Apr 14, 2022
8 Apr 14, 2022
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
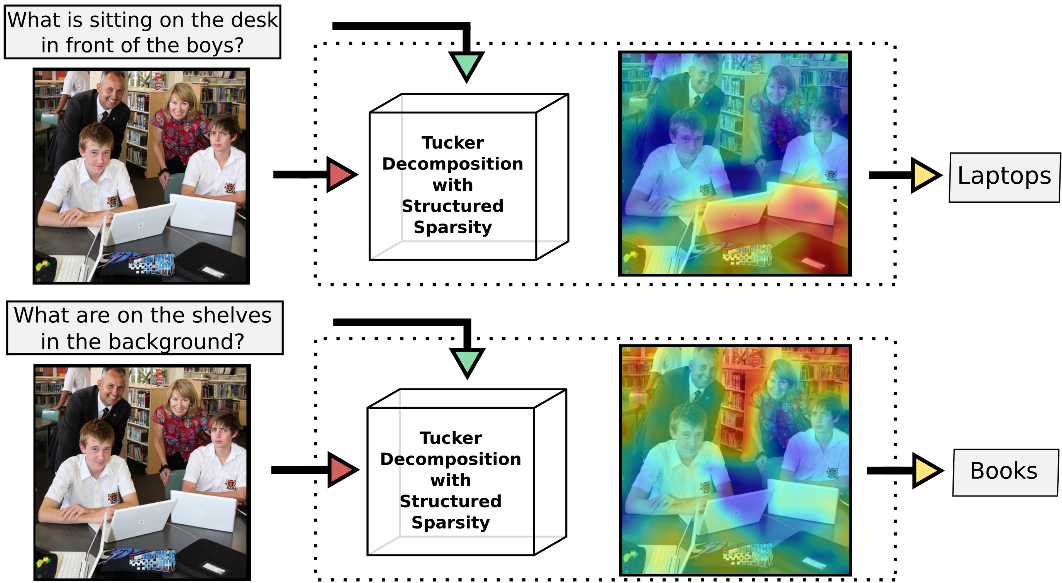
Visual Question Answering in Pytorch
Visual Question Answering in pytorch /!\ New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch This repo wa
 672 Jan 1, 2023
672 Jan 1, 2023
Pytorch implementation of winner from VQA Chllange Workshop in CVPR'17
2017 VQA Challenge Winner (CVPR'17 Workshop) pytorch implementation of Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challeng
166 Dec 11, 2022

Neural Module Network for VQA in Pytorch
Neural Module Network (NMN) for VQA in Pytorch Note: This is NOT an official repository for Neural Module Networks. NMN is a network that is assembled
 111 Nov 24, 2022
111 Nov 24, 2022
An efficient PyTorch implementation of the winning entry of the 2017 VQA Challenge.
Bottom-Up and Top-Down Attention for Visual Question Answering An efficient PyTorch implementation of the winning entry of the 2017 VQA Challenge. The
 731 Jan 3, 2023
731 Jan 3, 2023

PyTorch implementation of "Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning"
Transparency-by-Design networks (TbD-nets) This repository contains code for replicating the experiments and visualizations from the paper Transparenc
 351 Nov 18, 2022
351 Nov 18, 2022
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption, CVPR 2021 (Oral)
TAP: Text-Aware Pre-training TAP: Text-Aware Pre-training for Text-VQA and Text-Caption by Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Flo
61 Nov 14, 2022
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
5.1k Dec 26, 2022

Official PyTorch implementation for Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers, a novel method to visualize any Transformer-based network. Including examples for DETR, VQA.
PyTorch Implementation of Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers 1 Using Colab Please notic
 489 Jan 7, 2023
489 Jan 7, 2023
![[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias](https://github.com/yuleiniu/cfvqa/raw/main/assets/cfvqa.png)
[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias
Counterfactual VQA (CF-VQA) This repository is the Pytorch implementation of our paper "Counterfactual VQA: A Cause-Effect Look at Language Bias" in C
 94 Dec 3, 2022
94 Dec 3, 2022
Official PyTorch code for ClipBERT, an efficient framework for end-to-end learning on image-text and video-text tasks
Official PyTorch code for ClipBERT, an efficient framework for end-to-end learning on image-text and video-text tasks. It takes raw videos/images + text as inputs, and outputs task predictions. ClipBERT is designed based on 2D CNNs and transformers, and uses a sparse sampling strategy to enable efficient end-to-end video-and-language learning.
 612 Jan 4, 2023
612 Jan 4, 2023