11 Repositories
Python webpage Libraries

A webpage that utilizes machine learning to extract sentiments from tweets.
Tweets_Classification_Webpage The goal of this project is to be able to predict what rating customers on social media platforms would give to products
 1 Dec 30, 2021
1 Dec 30, 2021
urlwatch is intended to help you watch changes in webpages and get notified of any changes.
urlwatch is intended to help you watch changes in webpages and get notified (via e-mail, in your terminal or through various third party services) of any changes.
 2.5k Jan 8, 2023
2.5k Jan 8, 2023

Cross-Encoder-with-Bi-Encoder를 활용한 WebPage 데모
Retrieval_Streamlit_Demo Cross-Encoder-with-Bi-Encoder를 활용한
 5 Dec 29, 2021
5 Dec 29, 2021
ESP32 recording button presses, and serving webpage that graphs the numbers over time.
ESP32-IoT-button-graph-test ESP32 recording button presses, and serving webpage via webSockets in order to graph the responses. The objective was to t
 1 Nov 30, 2021
1 Nov 30, 2021
Code for database and frontend of webpage for Neural Fields in Visual Computing and Beyond.
Neural Fields in Visual Computing—Complementary Webpage This is based on the amazing MiniConf project from Hendrik Strobelt and Sasha Rush—thank you!
 29 Nov 30, 2022
29 Nov 30, 2022
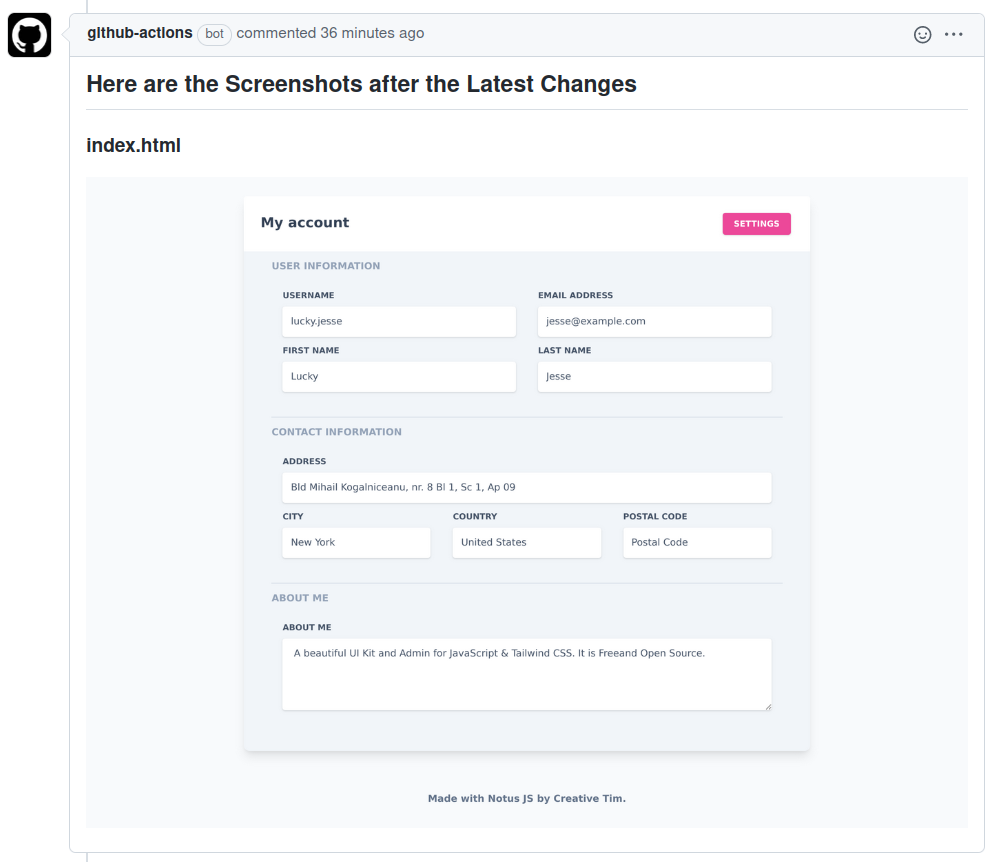
Comment Webpage Screenshot is a GitHub Action that captures screenshots of web pages and HTML files located in the repository
Comment Webpage Screenshot is a GitHub Action that helps maintainers visually review HTML file changes introduced on a Pull Request by adding comments with the screenshots of the latest HTML file changes on the Pull Request
 21 Sep 29, 2022
21 Sep 29, 2022

A Context-aware Visual Attention-based training pipeline for Object Detection from a Webpage screenshot!
CoVA: Context-aware Visual Attention for Webpage Information Extraction Abstract Webpage information extraction (WIE) is an important step to create k
 41 Jan 1, 2023
41 Jan 1, 2023

This is a webpage that contains login and signup page by which the password is stored using elliptic curve cryptography
LoginPage_using_Elliptic_curve_cryptography- This is a webpage that contains login and signup page by which the password is stored using elliptic curv
 1 Oct 15, 2021
1 Oct 15, 2021
Implemented page rank program
Page Rank Implemented page rank program based on fact that a website is more important if it is linked to by other important websites using recursive
 6 Aug 24, 2022
6 Aug 24, 2022

One webpage for every book ever published!
Open Library Open Library is an open, editable library catalog, building towards a web page for every book ever published. Are you looking to get star
 4k Jan 8, 2023
4k Jan 8, 2023

HTTP(s) "monitoring" webpage via FastAPI+Jinja2. Inspired by https://github.com/RaymiiOrg/bash-http-monitoring
python-http-monitoring HTTP(s) "monitoring" powered by FastAPI+Jinja2+aiohttp. Inspired by bash-http-monitoring. Installation can be done with pipenv
 39 Aug 26, 2022
39 Aug 26, 2022