환경 : ColabPro
!git clone https://github.com/BM-K/KoSimCSE.git
%cd KoSimCSE
!git clone https://github.com/SKTBrain/KoBERT.git
%cd KoBERT
!pip install -r requirements.txt
!pip install .
%cd ..
!pip install -r requirements.txt
!pip install transformers==4.8.1
!pip install folium==0.2.1
!pip install tensorboardX
호환 문제 때문에 해당 패키지들의 버전을 맞추었습니다.
!chmod +x
!/content/KoSimCSE/run_example.sh!/content/KoSimCSE/run_example.sh
해당 코드로 돌렸을 때 output console 입니다.
Start Training
argparse{
opt_level : O1
fp16 : True
train : True
test : False
device : cuda
patient : 10
dropout : 0.1
max_len : 50
batch_size : 256
epochs : 3
eval_steps : 250
seed : 1234
lr : 0.0001
weight_decay : 0.0
warmup_ratio : 0.05
temperature : 0.05
train_data : train_nli_sample.tsv
valid_data : valid_sts_sample.tsv
test_data : test_sts.tsv
task : NLU
path_to_data : ./data/
path_to_save : ./output/
path_to_saved_model : ./output/
ckpt : best_checkpoint.pt
}
using cached model
using cached model
using cached model
Selected optimization level O1: Insert automatic casts around Pytorch functions and Tensor methods.
Defaults for this optimization level are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Warning: multi_tensor_applier fused unscale kernel is unavailable, possibly because apex was installed without --cuda_ext --cpp_ext. Using Python fallback. Original ImportError was: ModuleNotFoundError("No module named 'amp_C'")
[INFO] 2021-12-23 05:32:45,674 [ Model Setting Complete ] | file::main.py | line::8
[INFO] 2021-12-23 05:32:45,674 [ Start Training ] | file::main.py | line::11
0% 0/1 [00:00<?, ?it/s]
Traceback (most recent call last):
File "main.py", line 28, in <module>
main(args, logger)
File "main.py", line 15, in main
processor.train(epoch+1)
File "/content/KoSimCSE/model/simcse/processor.py", line 118, in train
train_loss = self.run(inputs, type='train')
File "/content/KoSimCSE/model/simcse/processor.py", line 36, in run
anchor_embeddings, positive_embeddings, negative_embeddings = self.config['model'](inputs, type)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/content/KoSimCSE/model/simcse/bert.py", line 28, in forward
attention_mask=positive_attention_mask)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/models/bert/modeling_bert.py", line 1001, in forward
return_dict=return_dict,
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/models/bert/modeling_bert.py", line 589, in forward
output_attentions,
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/models/bert/modeling_bert.py", line 475, in forward
past_key_value=self_attn_past_key_value,
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/models/bert/modeling_bert.py", line 408, in forward
output_attentions,
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/models/bert/modeling_bert.py", line 267, in forward
mixed_query_layer = self.query(hidden_states)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/linear.py", line 103, in forward
return F.linear(input, self.weight, self.bias)
File "/content/KoSimCSE/apex/amp/wrap.py", line 21, in wrapper
args[i] = utils.cached_cast(cast_fn, args[i], handle.cache)
File "/content/KoSimCSE/apex/amp/utils.py", line 97, in cached_cast
if cached_x.grad_fn.next_functions[1][0].variable is not x:
**IndexError: tuple index out of range**
Start Testing
argparse{
opt_level : O1
fp16 : True
train : False
test : True
device : cuda
patient : 10
dropout : 0.1
max_len : 50
batch_size : 256
epochs : 3
eval_steps : 250
seed : 1234
lr : 5e-05
weight_decay : 0.0
warmup_ratio : 0.05
temperature : 0.05
train_data : train_nli.tsv
valid_data : valid_sts.tsv
test_data : test_sts_sample.tsv
task : NLU
path_to_data : ./data/
path_to_save : ./output/
path_to_saved_model : ./output/best_checkpoint.pt
ckpt : best_checkpoint.pt
}
using cached model
using cached model
using cached model
Selected optimization level O1: Insert automatic casts around Pytorch functions and Tensor methods.
Defaults for this optimization level are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Processing user overrides (additional kwargs that are not None)...
After processing overrides, optimization options are:
enabled : True
opt_level : O1
cast_model_type : None
patch_torch_functions : True
keep_batchnorm_fp32 : None
master_weights : None
loss_scale : dynamic
Warning: multi_tensor_applier fused unscale kernel is unavailable, possibly because apex was installed without --cuda_ext --cpp_ext. Using Python fallback. Original ImportError was: ModuleNotFoundError("No module named 'amp_C'")
[INFO] 2021-12-23 05:33:01,197 [ Model Setting Complete ] | file::main.py | line::8
[INFO] 2021-12-23 05:33:01,197 [ Start Test ] | file::main.py | line::18
Traceback (most recent call last):
File "main.py", line 28, in <module>
main(args, logger)
File "main.py", line 20, in main
processor.test()
File "/content/KoSimCSE/model/simcse/processor.py", line 163, in test
self.config['model'].load_state_dict(torch.load(self.args.path_to_saved_model)['model'], strict=False)
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 594, in load
with _open_file_like(f, 'rb') as opened_file:
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 230, in _open_file_like
return _open_file(name_or_buffer, mode)
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 211, in __init__
super(_open_file, self).__init__(open(name, mode))
FileNotFoundError: [Errno 2] No such file or directory: './output/best_checkpoint.pt'
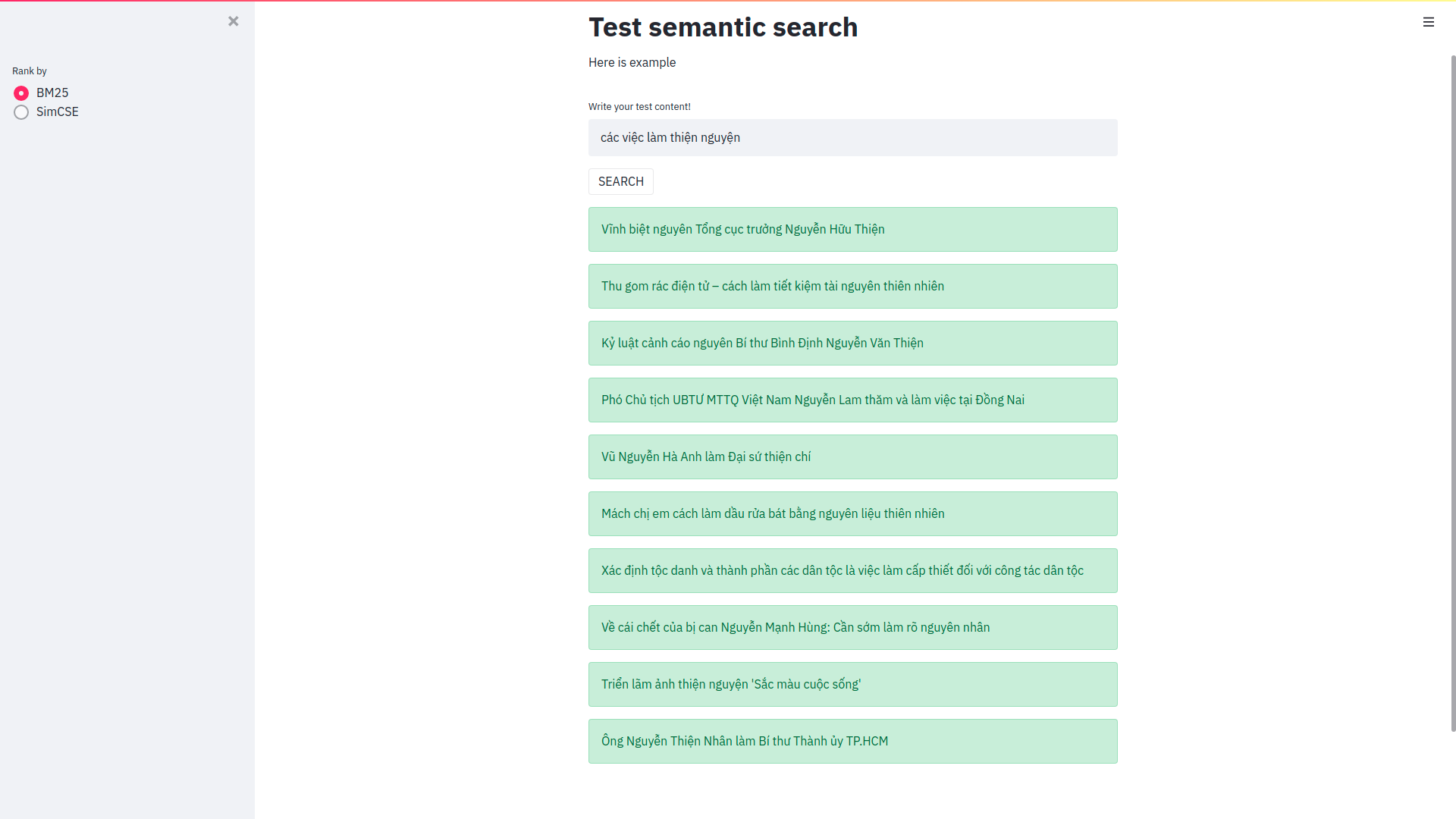
Semantic Search
using cached model
using cached model
using cached model
/content/KoSimCSE/data/dataloader.py:178: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ../torch/csrc/utils/tensor_new.cpp:201.)
inputs = {'source': torch.LongTensor(tensor_corpus),
======================
Query: 한 남자가 파스타를 먹는다.
Top 5 most similar sentences in corpus:
한 남자가 음식을 먹는다. (Score: 0.6002)
한 남자가 빵 한 조각을 먹는다. (Score: 0.5940)
치타 한 마리가 먹이 뒤에서 달리고 있다. (Score: 0.0694)
한 남자가 말을 탄다. (Score: 0.0327)
원숭이 한 마리가 드럼을 연주한다. (Score: -0.0050)
======================
Query: 고릴라 의상을 입은 누군가가 드럼을 연주하고 있다.
Top 5 most similar sentences in corpus:
원숭이 한 마리가 드럼을 연주한다. (Score: 0.6490)
한 여자가 바이올린을 연주한다. (Score: 0.3669)
한 남자가 말을 탄다. (Score: 0.2322)
그 여자가 아이를 돌본다. (Score: 0.1980)
한 남자가 담으로 싸인 땅에서 백마를 타고 있다. (Score: 0.1627)
======================
Query: 치타가 들판을 가로 질러 먹이를 쫓는다.
Top 5 most similar sentences in corpus:
치타 한 마리가 먹이 뒤에서 달리고 있다. (Score: 0.7756)
두 남자가 수레를 숲 속으로 밀었다. (Score: 0.1812)
한 남자가 말을 탄다. (Score: 0.1667)
원숭이 한 마리가 드럼을 연주한다. (Score: 0.1530)
한 남자가 담으로 싸인 땅에서 백마를 타고 있다. (Score: 0.1269)
Processor에서 train 함수 anchor_embeddings, positive_embeddings, negative_embeddings = self.config['model'](inputs, type)
해당 라인에서 문제가 생기는 것은 확인은 했는데 config 생성 당시 문제가 생기는 건지 의문입니다.

 2.2k Dec 27, 2022
2.2k Dec 27, 2022
 18 Nov 25, 2022
18 Nov 25, 2022
 23 Dec 30, 2022
23 Dec 30, 2022
 478 Dec 25, 2022
478 Dec 25, 2022
 20 Jul 11, 2022
20 Jul 11, 2022
 161 Dec 19, 2022
161 Dec 19, 2022

 11 Feb 18, 2022
11 Feb 18, 2022

 3 May 23, 2022
3 May 23, 2022
 37 Sep 5, 2022
37 Sep 5, 2022
![[IndexError] tuple index out of range](https://avatars.githubusercontent.com/u/57978619?v=4)


 2.5k Jan 7, 2023
2.5k Jan 7, 2023
 39 Nov 15, 2022
39 Nov 15, 2022
 3 Apr 18, 2022
3 Apr 18, 2022
 80 Jan 2, 2023
80 Jan 2, 2023
 40 Dec 20, 2022
40 Dec 20, 2022
 47 Sep 5, 2022
47 Sep 5, 2022
 549 Jan 6, 2023
549 Jan 6, 2023
 9.1k Jan 2, 2023
9.1k Jan 2, 2023