<<<<<<< HEAD 更新2021.08.16
**添加图片和视频保存功能:
1.图片和视频按照当前系统时间进行命名
2.各自检测结果存放入output文件夹
3.摄像头检测的默认设备序号更改为0,减少调试报错
温馨提示:
1.项目放置在全英文路径下,防止项目报错
2.默认使用cpu进行检测,自己可以在init中手动切换GPU(因为我的笔记本太老了)
3.当前的摄像头检测的存储有一点点问题,播放速度比较快,不知道是不是我用cpu检测,导致的帧率不匹配的问题(后面有时间在捣鼓捣鼓,我现在强制调慢了FPS
一、项目简介
使用PyQt5为YoloV5添加一个可视化检测界面,并实现简单的界面跳转,具体情况如下:
博客与B站:
博客地址:https://blog.csdn.net/wrh975373911/article/details/119322059?spm=1001.2014.3001.5501
B站视频:https://www.bilibili.com/video/BV1ZU4y1E7at
特点:
- UI界面与逻辑代码分离
- 支持自选定模型
- 同时输出检测结果与相应相关信息
- 支持图片,视频,摄像头检测
- 支持视频暂停与继续检测
目的:
- 熟悉QtDesign的使用
- 了解PyQt5基础控件与布局方法
- 了解界面跳转
- 了解信号与槽
- 熟悉视频在PyQt中的处理方法
项目图片:
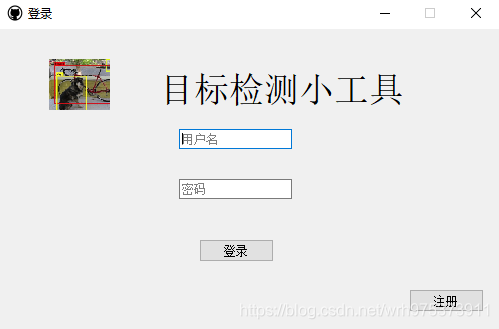
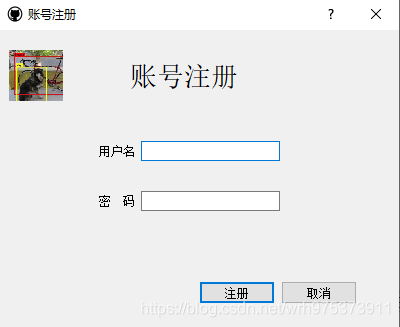

二、快速开始
环境与相关文件配置:
- 按照 ult-yolov5 中requirement的要求配置环境,自行安装PyQt5,注意都需要在一个evn环境中进行安装与配置
- 下载或训练一个模型,将“.pt”文件放到weights文件夹,(权重文件可以自己选,程序默认打开weights文件夹)
- 设置init中的opt
两种程序使用方式:
- 直接运行detect_logical.py,进入检测界面
- 运行main_logical.py,先登录,在进入检测界面
三、 参考与致谢
- 《PyQt5快速开发与实践》
- www.python3.vip
- B站白月黑羽的PyQt教程 https://www.bilibili.com/video/BV1cJ411R7bP?from=search&seid=7706040462590056686
- https://xugaoxiang.blog.csdn.net/article/details/118384430 从这个博主的博客中学到了很多知识,感觉博主,博主的代码框架也很好,也是本文代码是在其基础上进行学习和修改的
- Github项目:YOLOv3GUI_Pytorch_PyQt5
 20 Nov 14, 2022
20 Nov 14, 2022
 5 Nov 28, 2022
5 Nov 28, 2022
 22 Nov 3, 2022
22 Nov 3, 2022

 183 Jan 9, 2023
183 Jan 9, 2023
 813 Dec 31, 2022
813 Dec 31, 2022

 554 Dec 30, 2022
554 Dec 30, 2022
 34.1k Dec 31, 2022
34.1k Dec 31, 2022

 202 Jan 6, 2023
202 Jan 6, 2023

 477 Jan 6, 2023
477 Jan 6, 2023




 487 Dec 27, 2022
487 Dec 27, 2022
 1.5k Jan 5, 2023
1.5k Jan 5, 2023
 439 Dec 22, 2022
439 Dec 22, 2022
 150 Dec 30, 2022
150 Dec 30, 2022
 57 Nov 28, 2022
57 Nov 28, 2022
 12 Dec 28, 2022
12 Dec 28, 2022
 4 Feb 5, 2022
4 Feb 5, 2022
 82 Nov 29, 2022
82 Nov 29, 2022
 27 Dec 20, 2022
27 Dec 20, 2022
 30 Jan 6, 2023
30 Jan 6, 2023