Hello ,
I am facing some issues with Preprocessing. When I a running the section with preprocessing this is what I get:
AttributeError: module 'sklearn.preprocessing' has no attribute 'new_dataset'
Here is the code of yours. Am I missing any steps?
#Edit Author: Ray
IMPORTING IMPORTANT LIBRARIES
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import math
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers import LSTM
from sklearn import preprocessing # how to import preprocessing
import sklearn.preprocessing
import numpy as np
FOR REPRODUCIBILITY
np.random.seed(7)
IMPORTING DATASET
dataset = pd.read_csv('C:/Users/ray/Documents/Python Scripts/LSTM-Stock-prediction-master/apple_share_price.csv', usecols=[1,2,3,4])
dataset = dataset.reindex(index = dataset.index[::-1])
CREATING OWN INDEX FOR FLEXIBILITY
obs = np.arange(1, len(dataset) + 1, 1)
TAKING DIFFERENT INDICATORS FOR PREDICTION
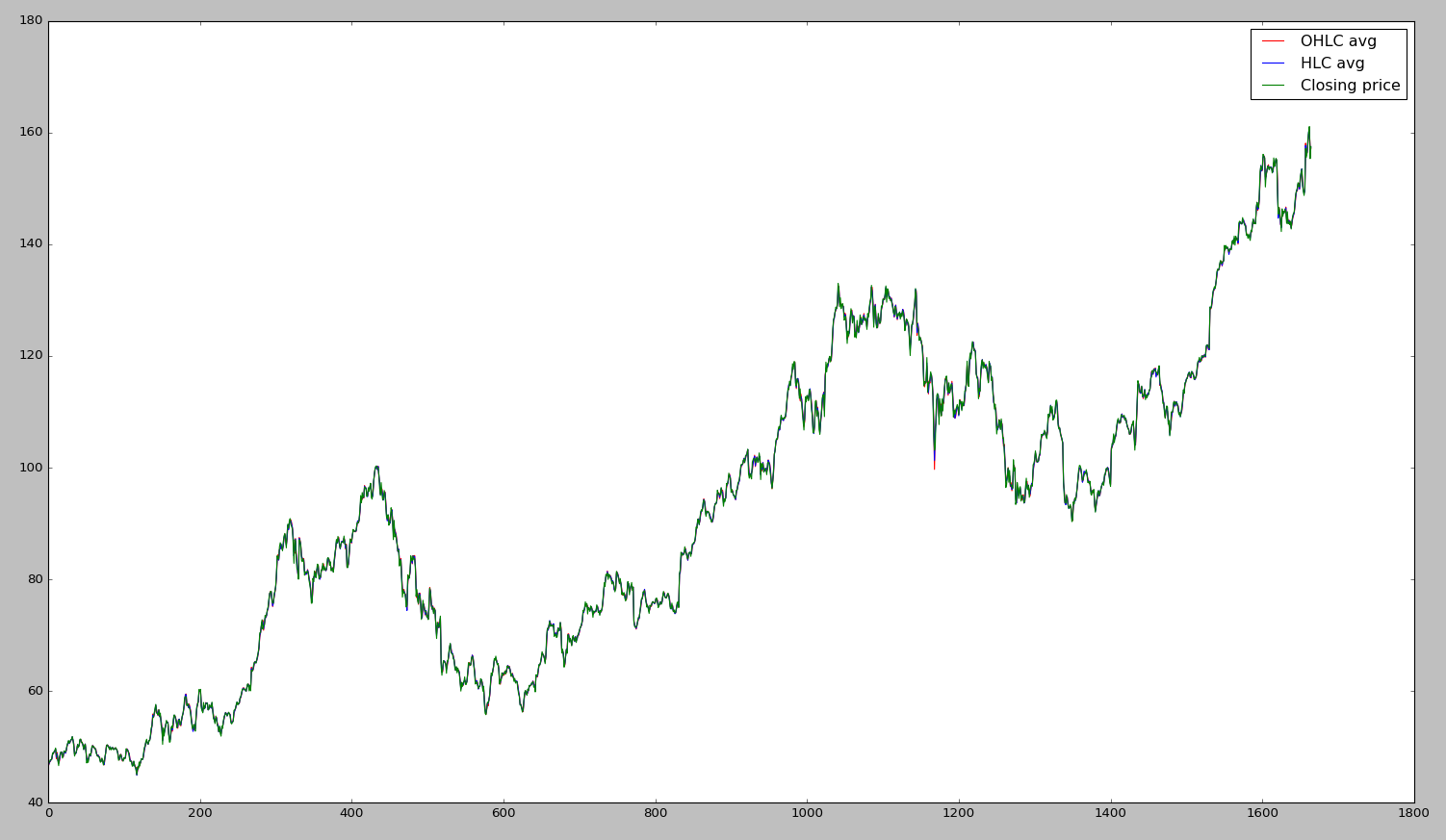
OHLC_avg = dataset.mean(axis = 1)
HLC_avg = dataset[['High', 'Low', 'Close']].mean(axis = 1)
close_val = dataset[['Close']]
PLOTTING ALL INDICATORS IN ONE PLOT
plt.plot(obs, OHLC_avg, 'r', label = 'OHLC avg')
plt.plot(obs, HLC_avg, 'b', label = 'HLC avg')
plt.plot(obs, close_val, 'g', label = 'Closing price')
plt.legend(loc = 'upper right')
plt.show()
PREPARATION OF TIME SERIES DATASET
OHLC_avg = np.reshape(OHLC_avg.values, (len(OHLC_avg),1)) # 1664
scaler = MinMaxScaler(feature_range=(0, 1))
OHLC_avg = scaler.fit_transform(OHLC_avg)
TRAIN-TEST SPLIT
train_OHLC = int(len(OHLC_avg) * 0.75)
test_OHLC = len(OHLC_avg) - train_OHLC
train_OHLC, test_OHLC = OHLC_avg[0:train_OHLC,:], OHLC_avg[train_OHLC:len(OHLC_avg),:]
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
step_size = 1
FUNCTION TO CREATE 1D DATA INTO TIME SERIES DATASET
def new_dataset(dataset, step_size):
trainX, trainY = [], []
for i in range(len(dataset)-step_size-1):
a = dataset[i:(i+step_size), 0]
trainX.append(a)
trainY.append(dataset[i + step_size, 0])
return np.array(trainX), np.array(trainY)
TIME-SERIES DATASET (FOR TIME T, VALUES FOR TIME T+1)
trainX, trainY = sklearn.preprocessing.new_dataset(train_OHLC, 1)
testX, testY = sklearn.preprocessing.new_dataset(test_OHLC, 1)
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
RESHAPING TRAIN AND TEST DATA
trainX = np.reshape(train_OHLC, (train_OHLC.shape[0], 1, train_OHLC.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
step_size = 1
LSTM MODEL
model = Sequential()
model.add(LSTM(32, input_shape=(1, step_size), return_sequences = True))
model.add(LSTM(16))
model.add(Dense(1))
model.add(Activation('linear'))
MODEL COMPILING AND TRAINING
model.compile(loss='mean_squared_error', optimizer='adagrad') # Try SGD, adam, adagrad and compare!!!
model.fit(trainX, trainY, epochs=5, batch_size=1, verbose=2)
PREDICTION
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
DE-NORMALIZING FOR PLOTTING
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
TRAINING RMSE
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train RMSE: %.2f' % (trainScore))
TEST RMSE
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test RMSE: %.2f' % (testScore))
CREATING SIMILAR DATASET TO PLOT TRAINING PREDICTIONS
trainPredictPlot = np.empty_like(OHLC_avg)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[step_size:len(trainPredict)+step_size, :] = trainPredict
CREATING SIMILAR DATASSET TO PLOT TEST PREDICTIONS
testPredictPlot = np.empty_like(OHLC_avg)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(trainPredict)+(step_size*2)+1:len(OHLC_avg)-1, :] = testPredict
DE-NORMALIZING MAIN DATASET
OHLC_avg = scaler.inverse_transform(OHLC_avg)
PLOT OF MAIN OHLC VALUES, TRAIN PREDICTIONS AND TEST PREDICTIONS
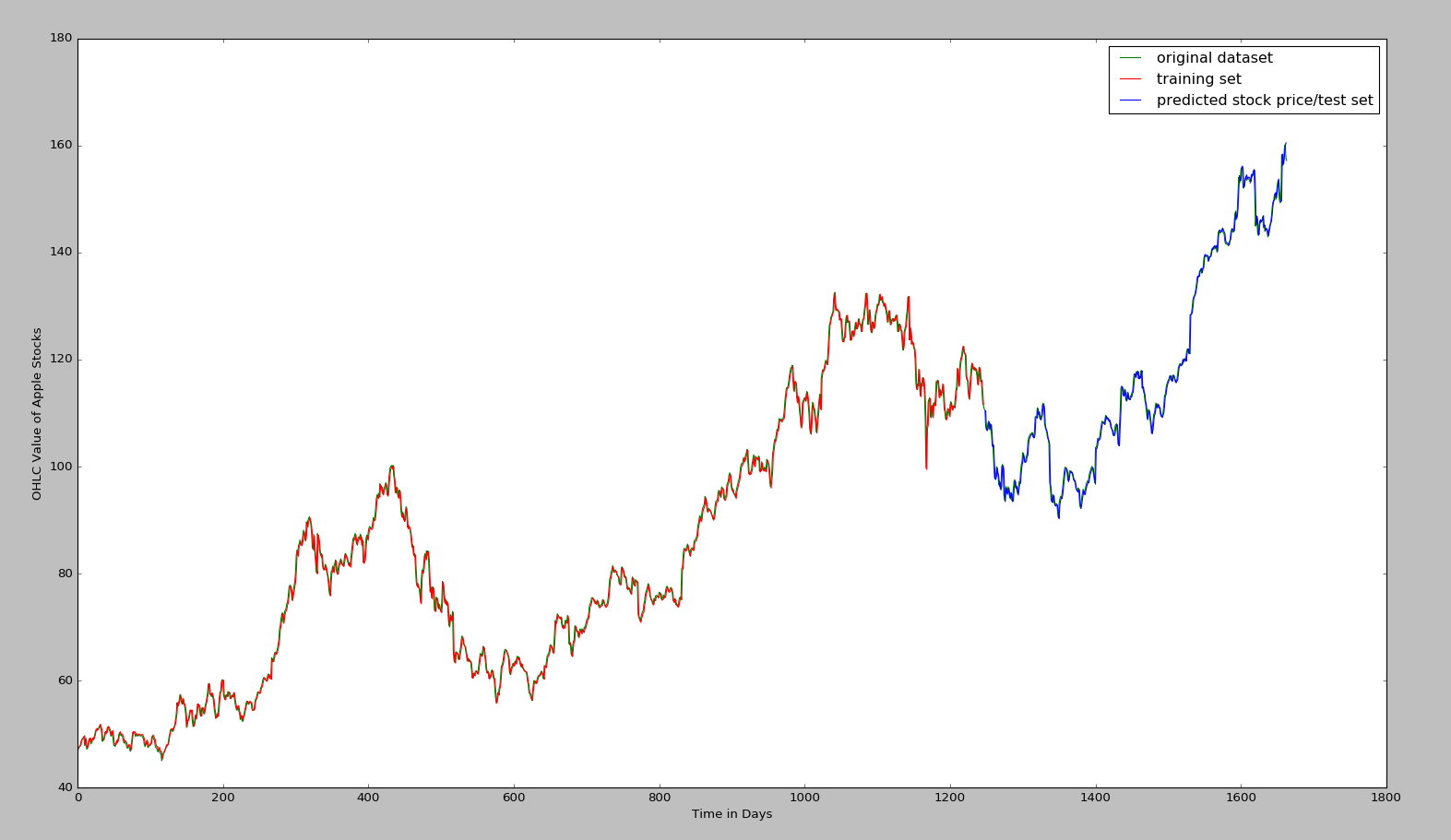
plt.plot(OHLC_avg, 'g', label = 'original dataset')
plt.plot(trainPredictPlot, 'r', label = 'training set')
plt.plot(testPredictPlot, 'b', label = 'predicted stock price/test set')
plt.legend(loc = 'upper right')
plt.xlabel('Time in Days')
plt.ylabel('OHLC Value of Apple Stocks')
plt.show()
PREDICT FUTURE VALUES
last_val = testPredict[-1]
last_val_scaled = last_val/last_val
next_val = model.predict(np.reshape(last_val_scaled, (1,1,1)))
print "Last Day Value:", np.asscalar(last_val)
print "Next Day Value:", np.asscalar(last_val*next_val)
print np.append(last_val, next_val)

 please fix me if i wrong
please fix me if i wrong












 1.3k Dec 28, 2022
1.3k Dec 28, 2022
 26 May 26, 2022
26 May 26, 2022
 39 Nov 21, 2022
39 Nov 21, 2022
 15 Aug 20, 2022
15 Aug 20, 2022
 2 Dec 13, 2022
2 Dec 13, 2022
 116 Nov 9, 2022
116 Nov 9, 2022
 69 Dec 26, 2022
69 Dec 26, 2022
 1 Jun 13, 2022
1 Jun 13, 2022
 84 Jan 1, 2023
84 Jan 1, 2023
 251 Dec 17, 2022
251 Dec 17, 2022
 194 Dec 28, 2022
194 Dec 28, 2022
 2 Jan 30, 2022
2 Jan 30, 2022
 1 Nov 20, 2021
1 Nov 20, 2021
 318 Dec 14, 2022
318 Dec 14, 2022
 1 Oct 29, 2021
1 Oct 29, 2021
 3 Sep 30, 2021
3 Sep 30, 2021
 10 Dec 10, 2021
10 Dec 10, 2021
 1 Jan 15, 2022
1 Jan 15, 2022
 243 Dec 26, 2022
243 Dec 26, 2022