ocr-fileformat



Validate and transform between OCR file formats (hOCR, ALTO, PAGE, FineReader)
Installation
Docker
You can run the command line scripts and web interface as a Docker container, you only need Docker installed.
To start the web interface on http://localhost:8080:
docker run --rm -it -p 8080:8080 ubma/ocr-fileformat
To run the command line scripts, mount the directory containing your input files into the container's /data directory:
docker run --rm -it -v "$PWD":/data ubma/ocr-fileformat ocr-transform alto2.0 hocr somefile.alto
System-wide
To install system-wide to /usr/local:
sudo make install
To install without sudo to your home directory:
make install PREFIX=$HOME/.local
If $HOME/.local/bin is not in your PATH, add this to your shell startup file (e.g. ~/.bashrc or ~/.zshrc):
export PATH="$HOME/.local/bin $PATH"
The web application has a PHP backed. You can deploy it on any PHP-capable server by copying the web folder somewhere below the document root of your server, e.g. /var/www/html for Apache on Debian/Ubuntu:
sudo -u www-data cp -r web /var/www/html/ocr-fileformat
In this example the GUI would be available under http://localhost/ocr-fileformat/.
Usage
The project offers two functionalities, which can be accessd via a command line script (CLI), using a web interface (GUI) or in you own tools (API)
CLI
ocr-transform: Transformation of OCR output between OCR formatsocr-validate: Validation of OCR output against OCR format schemas
GUI
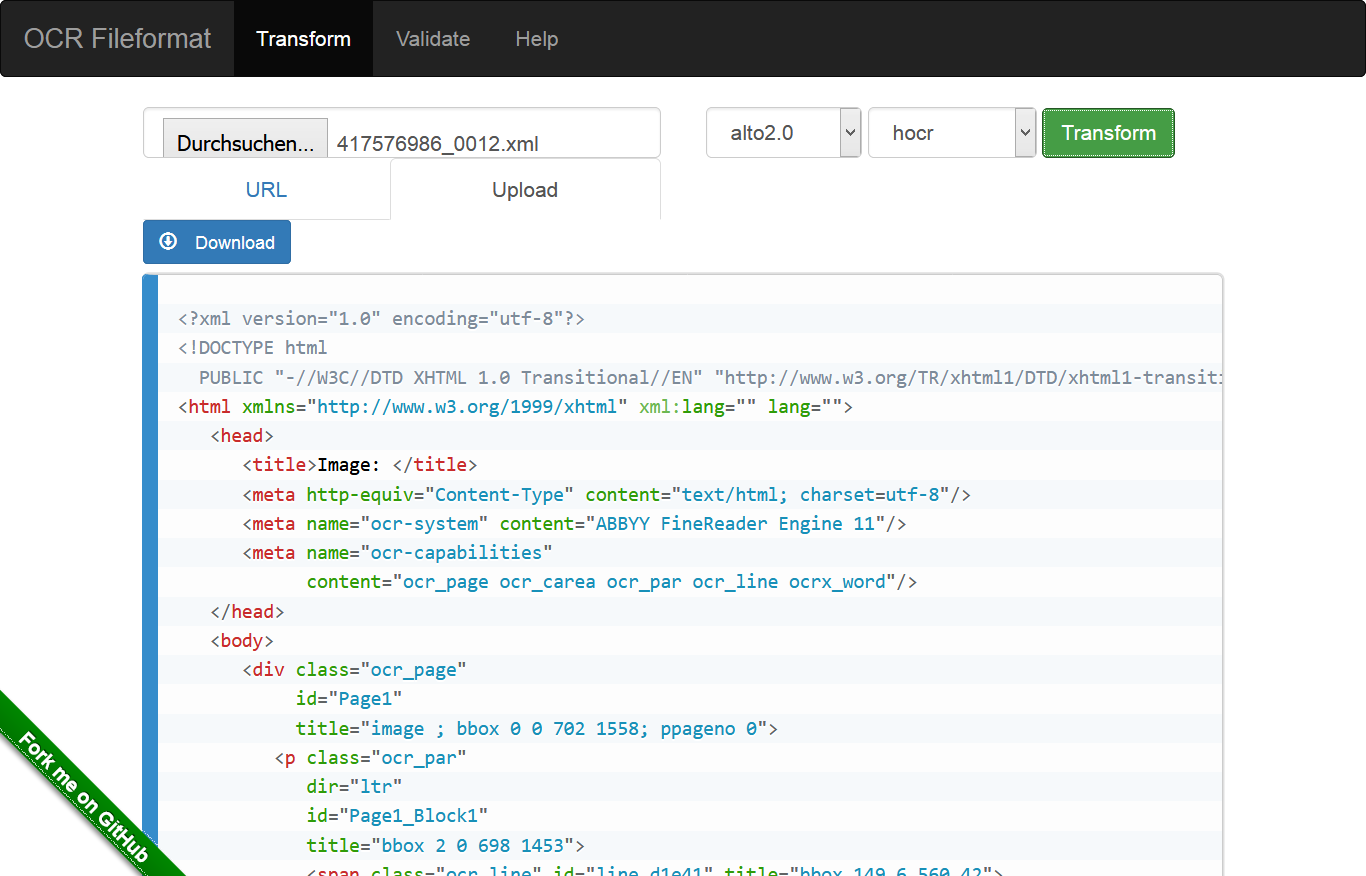
The web interface is for testing validation and transformations. You can upload a file or select an input file by URL.
API
$PREFIX/share/ocr-fileformat/xslt- XSLT stylesheets$PREFIX/share/ocr-fileformat/xsd- XSD schemas$PREFIX/share/ocr-fileformat/script/transform- Transformation scripts$PREFIX/share/ocr-fileformat/script/validate- Validation scripts
Transformation
Transformation CLI
Usage: ocr-transform [-dl] <input-fmt> <output-fmt> [<input> [<output>]] [-- <saxon_opts>]
For example, you can transform an ALTO XML to a hOCR file with:
ocr-transform alto hocr sample.xml sample.hocr
Or convert from ALTO XML (version 2.1) to hOCR with:
ocr-transform alto2.1 hocr sample.alto sample.hocr
You can also pass arguments directly to the Saxon CLI by passing them after a double dash (--). For example, to set the foo parameter to bar:
ocr-transform alto hocr sample.xml sample.hocr -- foo=bar
Try ocr-transform -h to get an overview:
Usage: ocr-transform [-dhLv] [ []] [-- ]
Options:
--help -h Show this help
--version -v Show version
--debug -d Increase debug level by 1, can be repeated
--list -L List transformations
Transformations:
abbyy hocr
abbyy page
alto2.0 alto3.0
alto2.0 alto3.1
alto2.0 hocr
alto2.1 alto3.0
alto2.1 alto3.1
alto2.1 hocr
alto page
alto text
gcv hocr
gcv page
hocr alto2.0
hocr alto2.1
hocr page
hocr text
page alto
page hocr
page page2019
page text
tei hocr
Saxon options:
Usage: see http://www.saxonica.com/documentation/index.html#!using-xsl/commandline
Options available: -? -a -catalog -config -cr -diag -dtd -ea -expand -explain -export -ext -im -init -it -jit -l -lib -license -m -nogo -now -o -opt -or -outval -p -quit -r -relocate -repeat -s -sa -scmin -strip -t -T -target -threads -TJ -Tlevel -Tout -TP -traceout -tree -u -val -versionmsg -warnings -x -xi -xmlversion -xsd -xsdversion -xsiloc -xsl -y
Use -XYZ:? for details of option XYZ
Params:
param=value Set stylesheet string parameter
+param=filename Set stylesheet document parameter
?param=expression Set stylesheet parameter using XPath
!param=value Set serialization parameter
Transformation GUI
Select the Transform menu option. Choose a URL, an input and an output format. Click Transform.
Transformation API
The stylesheets are installed in $PREFIX/share/ocr-fileformat/xslt and can be used directly in your scripts and software. You will need to use an XSLT 2.0 capable stylesheet transformer.
Supported Transformations
| From ╲ To | hOCR | ALTO | PAGEXML |
|---|---|---|---|
| hOCR | = | ✓ | ✓ |
| ALTO | ✓ | = | ✓ |
| PAGEXML | ✓ | ✓ | = |
| FineReader | ✓ | - | ✓ |
| Google Cloud Vision | ✓ | - | ✓ |
| TEI | ✓ | - | - |
Validation
Usage: ocr-validate [-dhL] []
Options:
--help -h Show this help
--version -v Show version
--debug -d Increase debug level by 1, can be repeated
--list -L List available schemas
Schemas:
hocr
alto-1-0 alto-1-1 alto-1-2 alto-1-3 alto-1-4 alto-2-0 alto-2-1 alto-2-2-draft alto-3-0 alto-3-1 alto-3-2-draft alto-4-0 alto-4-1
abbyy-6-schema-v1 abbyy-8-schema-v2 abbyy-9-schema-v1 abbyy-10-schema-v1
page-2009-03-16 page-2010-01-12 page-2010-03-19 page-2013-07-15 page-2016-07-15 page-2017-07-15 page-2018-07-15 page-2019-07-15
Validation CLI
For example, to validate an XML file againt the ALTO 3.1 schema:
ocr-validate alto-3-1 myFile.alto
Validation GUI
Select the Validate menu option. Choose a URL and an schema. Click Validate.
Validation API
The XSD files are installed under $PREFIX/share/ocr-fileformat/xsd
Supported Validation Formats
| hOCR | ALTO | PAGEXML | FineReader | Google Cloud Vision | |
|---|---|---|---|---|---|
| Validation | ✓ | ✓ | ✓ | ✓ | - |
License
This is free software. You may use it under the terms of the MIT License.
During the installation process several projects are included (in ./vendor). These projects have different licenses:
- Saxon HE 9.7,
MPL. - ALTOXML schema, "Open Source" for ALTO <= 3.1,
CC BY SA 4.0since ALTO 4.0 - PAGE schemas,
? - xsd-validator by Adrian Mouat @amouat,
Apache 2.0 - ABBYY FineReader XSD,
? - hOCR-to-ALTO by Filip Kriz @filak,
MIT - hocr-spec by Konstantin Baierer @kba,
MIT - gcv2hocr by Endo Michiaki,
CC BY 4.0 - format-converters by OCR-D,
Apache 2.0 - prima-page-converter by PRImA Research Lab ,
Apache 2.0













 285 Dec 8, 2022
285 Dec 8, 2022
 46 Nov 14, 2022
46 Nov 14, 2022
 180 Nov 24, 2022
180 Nov 24, 2022
 27.5k Jan 8, 2023
27.5k Jan 8, 2023
 59 Sep 10, 2022
59 Sep 10, 2022
 4 Jul 11, 2022
4 Jul 11, 2022
 5 Dec 6, 2021
5 Dec 6, 2021
 7 Jan 4, 2023
7 Jan 4, 2023
 127 Dec 3, 2022
127 Dec 3, 2022
 16.7k Jan 3, 2023
16.7k Jan 3, 2023
 684 Jan 6, 2023
684 Jan 6, 2023
 1.2k Dec 29, 2022
1.2k Dec 29, 2022
 186 Dec 29, 2022
186 Dec 29, 2022
 71 Dec 6, 2022
71 Dec 6, 2022
 99 Dec 12, 2022
99 Dec 12, 2022
 422 Jan 3, 2023
422 Jan 3, 2023
 27 Jun 20, 2022
27 Jun 20, 2022
 45 Dec 6, 2022
45 Dec 6, 2022
 311 Dec 24, 2022
311 Dec 24, 2022