![]()
ClearML - Auto-Magical Suite of tools to streamline your ML workflow
Experiment Manager, MLOps and Data-Management



ClearML
Formerly known as Allegro Trains
ClearML is a ML/DL development and production suite, it contains three main modules:
- Experiment Manager - Automagical experiment tracking, environments and results
- ML-Ops - Automation, Pipelines & Orchestration solution for ML/DL jobs (K8s / Cloud / bare-metal)
- Data-Management - Fully differentiable data management & version control solution on top of object-storage (S3/GS/Azure/NAS)
Instrumenting these components is the ClearML-server, see Self-Hosting & Free tier Hosting
Sign up & Start using in under 2 minutes

ClearML Experiment Manager
Adding only 2 lines to your code gets you the following
- Complete experiment setup log
- Full source control info including non-committed local changes
- Execution environment (including specific packages & versions)
- Hyper-parameters
- Initial model weights file
- Full experiment output automatic capture
- stdout and stderr
- Resource Monitoring (CPU/GPU utilization, temperature, IO, network, etc.)
- Model snapshots (With optional automatic upload to central storage: Shared folder, S3, GS, Azure, Http)
- Artifacts log & store (Shared folder, S3, GS, Azure, Http)
- Tensorboard/TensorboardX scalars, metrics, histograms, images, audio and video samples
- Matplotlib & Seaborn
- ClearML Logger interface for complete flexibility.
- Extensive platform support and integrations
- Supported ML/DL frameworks: PyTorch (incl' ignite / lightning), Tensorflow, Keras, AutoKeras, FastAI, XGBoost, LightGBM, MegEngine and Scikit-Learn
- Seamless integration (including version control) with Jupyter Notebook and PyCharm remote debugging
Start using ClearML
-
Sign up for free to the ClearML Hosted Service (alternatively, you can set up your own server, see here).
ClearML Demo Server: ClearML no longer uses the demo server by default. To enable the demo server, set the
CLEARML_NO_DEFAULT_SERVER=0environment variable. Credentials aren't needed, but experiments launched to the demo server are public, so make sure not to launch sensitive experiments if using the demo server. -
Install the
clearmlpython package:pip install clearml
-
Connect the ClearML SDK to the server by creating credentials, then execute the command below and follow the instructions:
clearml-init
-
Add two lines to your code:
from clearml import Task task = Task.init(project_name='examples', task_name='hello world')
You are done, everything your process outputs is now automagically logged into ClearML.
Next step, automation! Learn more about ClearML's two-click automation here.
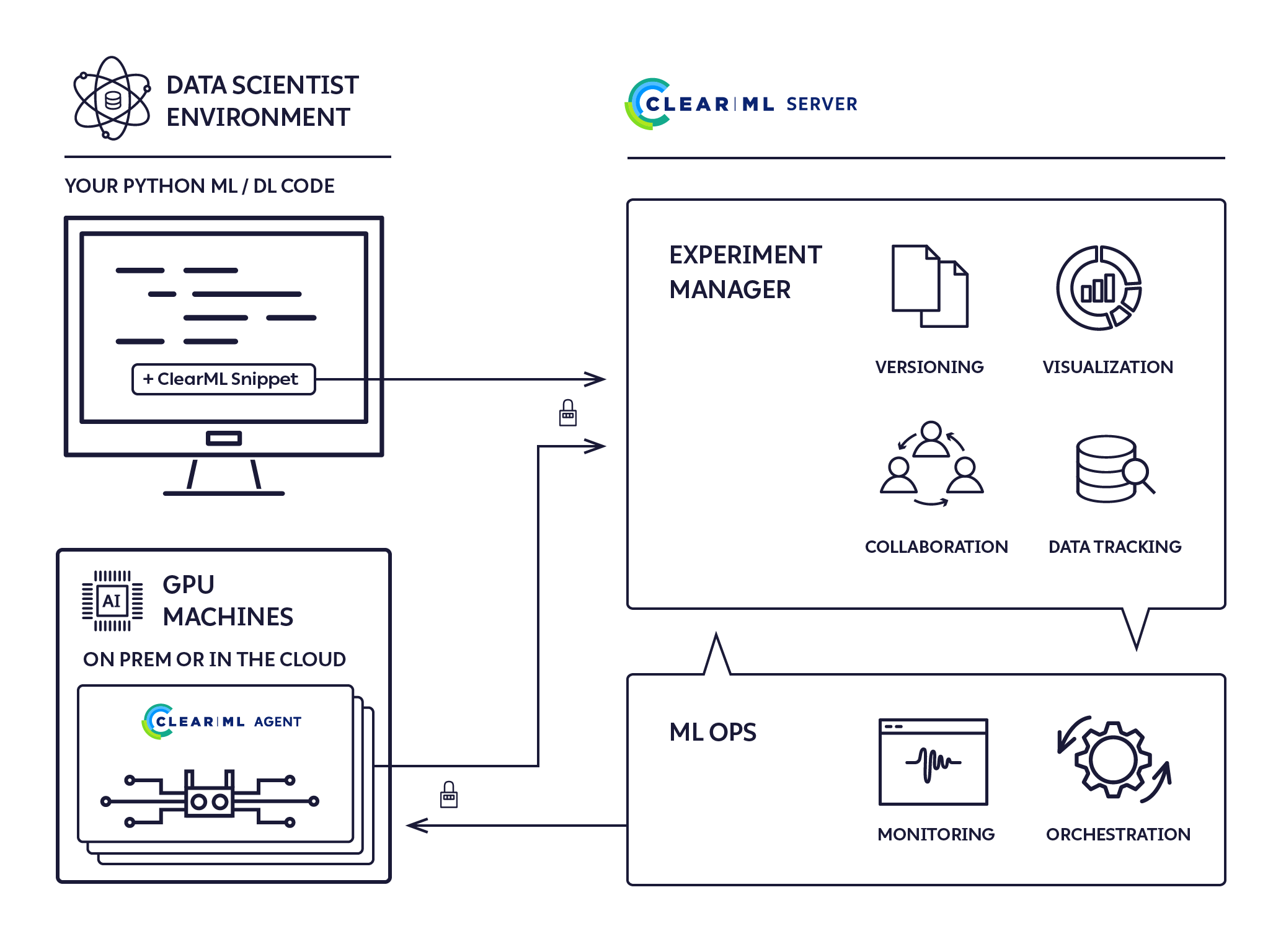
ClearML Architecture
The ClearML run-time components:
- The ClearML Python Package for integrating ClearML into your existing scripts by adding just two lines of code, and optionally extending your experiments and other workflows with ClearML powerful and versatile set of classes and methods.
- The ClearML Server storing experiment, model, and workflow data, and supporting the Web UI experiment manager, and ML-Ops automation for reproducibility and tuning. It is available as a hosted service and open source for you to deploy your own ClearML Server.
- The ClearML Agent for ML-Ops orchestration, experiment and workflow reproducibility, and scalability.
Additional Modules
- clearml-session - Launch remote JupyterLab / VSCode-server inside any docker, on Cloud/On-Prem machines
- clearml-task - Run any codebase on remote machines with full remote logging of Tensorboard, Matplotlib & Console outputs
- clearml-data - CLI for managing and versioning your datasets, including creating / uploading / downloading of data from S3/GS/Azure/NAS
- AWS Auto-Scaler - Automatically spin EC2 instances based on your workloads with preconfigured budget! No need for K8s!
- Hyper-Parameter Optimization - Optimize any code with black-box approach and state of the art Bayesian optimization algorithms
- Automation Pipeline - Build pipelines based on existing experiments / jobs, supports building pipelines of pipelines!
- Slack Integration - Report experiments progress / failure directly to Slack (fully customizable!)
Why ClearML?
ClearML is our solution to a problem we share with countless other researchers and developers in the machine learning/deep learning universe: Training production-grade deep learning models is a glorious but messy process. ClearML tracks and controls the process by associating code version control, research projects, performance metrics, and model provenance.
We designed ClearML specifically to require effortless integration so that teams can preserve their existing methods and practices.
- Use it on a daily basis to boost collaboration and visibility in your team
- Create a remote job from any experiment with a click of a button
- Automate processes and create pipelines to collect your experimentation logs, outputs, and data
- Store all you data on any object-storage solution, with the simplest interface possible
- Make you data transparent by cataloging it all on the ClearML platform
We believe ClearML is ground-breaking. We wish to establish new standards of true seamless integration between experiment management,ML-Ops and data management.
Who We Are
ClearML is supported by the team behind allegro.ai, where we build deep learning pipelines and infrastructure for enterprise companies.
We built ClearML to track and control the glorious but messy process of training production-grade deep learning models. We are committed to vigorously supporting and expanding the capabilities of ClearML.
We promise to always be backwardly compatible, making sure all your logs, data and pipelines will always upgrade with you.
License
Apache License, Version 2.0 (see the LICENSE for more information)
Documentation, Community & Support
More information in the official documentation and on YouTube.
For examples and use cases, check the examples folder and corresponding documentation.
If you have any questions: post on our Slack Channel, or tag your questions on stackoverflow with 'clearml' tag (previously trains tag).
For feature requests or bug reports, please use GitHub issues.
Additionally, you can always find us at [email protected]
Contributing
PRs are always welcomed
May the force (and the goddess of learning rates) be with you!





![[Feature] Support individual scalar reporting without plots](https://avatars.githubusercontent.com/u/12184618?v=4)











 36 Jun 20, 2021
36 Jun 20, 2021
 421 Dec 31, 2022
421 Dec 31, 2022
 2.6k Jan 8, 2023
2.6k Jan 8, 2023
 6 Feb 6, 2022
6 Feb 6, 2022
 3 Sep 16, 2022
3 Sep 16, 2022
 233 Jan 1, 2023
233 Jan 1, 2023
 107 Jan 3, 2023
107 Jan 3, 2023
 152 Jan 2, 2023
152 Jan 2, 2023
 65 Dec 8, 2022
65 Dec 8, 2022
 73 Oct 17, 2022
73 Oct 17, 2022
 1.3k Dec 22, 2022
1.3k Dec 22, 2022
 1 Nov 3, 2021
1 Nov 3, 2021
 6 Dec 27, 2022
6 Dec 27, 2022
 131 Dec 12, 2022
131 Dec 12, 2022
 366 Jan 3, 2023
366 Jan 3, 2023
 0 Mar 30, 2022
0 Mar 30, 2022
 17 Nov 20, 2022
17 Nov 20, 2022
 25 Dec 28, 2022
25 Dec 28, 2022
 35 Dec 29, 2022
35 Dec 29, 2022