neural waveshaping synthesis
real-time neural audio synthesis in the waveform domain
This repository is the official implementation of Neural Waveshaping Synthesis.
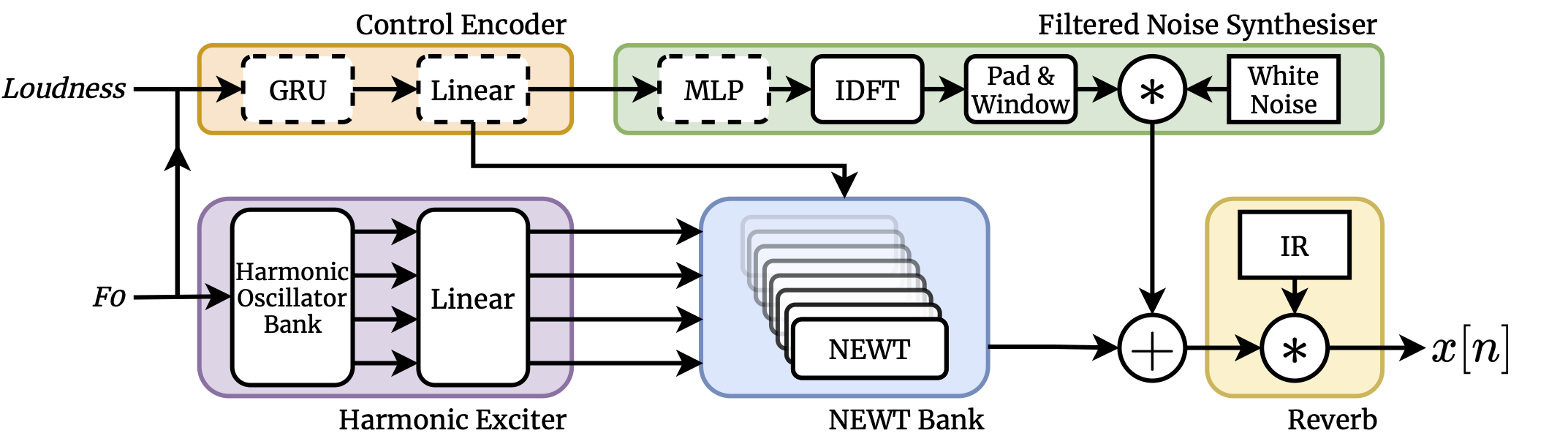
Model Architecture
Requirements
To install:
pip install -r requirements.txt
pip install -e .
We recommend installing in a virtual environment.
Data
We trained our checkpoints on the URMP dataset. Once downloaded, the dataset can be preprocessed using scripts/create_urmp_dataset.py. This will consolidate recordings of each instrument within the dataset and preprocess them according to the pipeline in the paper.
python scripts/create_urmp_dataset.py \
--gin-file gin/data/urmp_4second_crepe.gin \
--data-directory /path/to/urmp \
--output-directory /path/to/output \
--device cuda:0 # torch device string for CREPE model
Alternatively, you can supply your own dataset and use the general create_dataset.py script:
python scripts/create_dataset.py \
--gin-file gin/data/urmp_4second_crepe.gin \
--data-directory /path/to/dataset \
--output-directory /path/to/output \
--device cuda:0 # torch device string for CREPE model
Training
To train a model on the URMP dataset, use this command:
python scripts/train.py \
--gin-file gin/train/train_newt.gin \
--dataset-path /path/to/processed/urmp \
--urmp \
--instrument vn \ # select URMP instrument with abbreviated string
--load-data-to-memory
Or to use a non-URMP dataset:
python scripts/train.py \
--gin-file gin/train/train_newt.gin \
--dataset-path /path/to/processed/data \
--load-data-to-memory


![[bug] Training stopped at 1000 epoch](https://avatars.githubusercontent.com/u/16425753?v=4)





 96 Jan 3, 2023
96 Jan 3, 2023
 55 Dec 26, 2022
55 Dec 26, 2022
 170 Jan 4, 2023
170 Jan 4, 2023
 551 Dec 29, 2022
551 Dec 29, 2022
 94 Dec 29, 2022
94 Dec 29, 2022
 160 Jan 4, 2023
160 Jan 4, 2023
 22 Jul 7, 2022
22 Jul 7, 2022
 165 Dec 26, 2022
165 Dec 26, 2022
 80 Dec 25, 2022
80 Dec 25, 2022
 84 Dec 26, 2022
84 Dec 26, 2022
 22 Sep 22, 2022
22 Sep 22, 2022
 19 Oct 14, 2022
19 Oct 14, 2022
 238 Dec 22, 2022
238 Dec 22, 2022
 569 Dec 30, 2022
569 Dec 30, 2022
 7 Jan 5, 2023
7 Jan 5, 2023
 1 Dec 25, 2021
1 Dec 25, 2021