Unsupervised Learning of Visual 3D Keypoints for Control
[Project Website] [Paper]
Boyuan Chen1, Pieter Abbeel1, Deepak Pathak2
1UC Berkeley 2Carnegie Mellon University
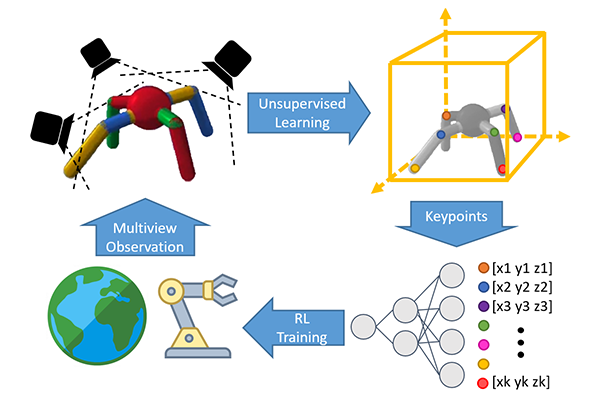
This is the code base for our paper on unsupervised learning of visual 3d keypoints for control. We propose an unsupervised learning method that learns temporally-consistent 3d keypoints via interaction. We jointly train an RL policy with the keypoint detector and shows 3d keypoints improve the sample efficiency of task learning in a variety of environments. If you find this work helpful to your research, please cite us as:
@inproceedings{chen2021unsupervised,
title={Unsupervised Learning of Visual 3D Keypoints for Control},
author={Boyuan Chen and Pieter Abbeel and Deepak Pathak},
year={2021},
Booktitle={ICML}
}
Environment Setup
If you hope to run meta-world experiments, make sure you have your mujoco binaries and valid license key in ~/.mujoco. Otherwise, you should edit the requirements.txt to remove metaworld and mujoco-py accordingly to avoid errors.
# clone this repo
git clone https://github.com/buoyancy99/unsup-3d-keypoints
cd unsup-3d-keypoints
# setup conda environment
conda create -n keypoint3d python=3.7.5
conda activate keypoint3d
pip3 install -r requirements.txt
Run Experiments
When training, all logs will be stored at data/, visualizations will be stored in images/ and all check points at ckpts/. You may use tensorboard to visualize training log or plotting the monitor files.
Quick start with pre-trained weights
# Visualize metaworld-hammer environment
python3 visualize.py --algo ppokeypoint -t hammer -v 1 -m 3d -j --offset_crop --decode_first_frame --num_keypoint 6 --decode_attention --seed 99 -u -e 0007
# Visualize metaworld-close-box environment
python3 visualize.py --algo ppokeypoint -t bc -v 1 -m 3d -j --offset_crop --decode_first_frame --num_keypoint 6 --decode_attention --seed 99 -u -e 0008
Reproduce the keypoints similiar to the two pre-trained checkpoints
# To reproduce keypoints visualization similiar to the above two checkpoints, use these commands
# Feel free to try any seed using [--seed]. Seeding makes training deterministic on each machine but has no guarantee across devices if using GPU. Thus you might not get the exact checkpoints as me if GPU models differ but resulted keypoints should look similiar.
python3 train.py --algo ppokeypoint -t hammer -v 1 -e 0007 -m 3d -j --total_timesteps 6000000 --offset_crop --decode_first_frame --num_keypoint 6 --decode_attention --seed 200 -u
python3 train.py --algo ppokeypoint -t bc -v 1 -e 0008 -m 3d -j --total_timesteps 6000000 --offset_crop --decode_first_frame --num_keypoint 6 --decode_attention --seed 200 -u
Train & Visualize Pybullet Ant with Keypoint3D(Ours)
# use -t antnc to train ant with no color
python3 train.py --algo ppokeypoint -t ant -v 1 -e 0001 -m 3d --frame_stack 2 -j --total_timesteps 5000000 --num_keypoint 16 --latent_stack --decode_first_frame --offset_crop --mean_depth 1.7 --decode_attention --separation_coef 0.005 --seed 99 -u
# After checkpoint is saved, visualize
python3 visualize.py --algo ppokeypoint -t ant -v 1 -e 0001 -m 3d --frame_stack 2 -j --total_timesteps 5000000 --num_keypoint 16 --latent_stack --decode_first_frame --offset_crop --mean_depth 1.7 --decode_attention --separation_coef 0.005 --seed 99 -u
Train Pybullet Ant with baselines
# RAD PPO baseline
python3 train.py --algo pporad -t ant -v 1 -e 0002 --total_timesteps 5000000 --frame_stack 2 --seed 99 -u
# Vanilla PPO baseline
python3 train.py --algo ppopixel -t ant -v 1 -e 0003 --total_timesteps 5000000 --frame_stack 2 --seed 99 -u
Train & Visualize 'Close-Box' environment in Meta-world with Keypoint3D(Ours)
python3 train.py --algo ppokeypoint -t bc -v 1 -e 0004 -m 3d -j --offset_crop --decode_first_frame --num_keypoint 32 --decode_attention --total_timesteps 4000000 --seed 99 -u
# After checkpoint is saved, visualize
python3 visualize.py --algo ppokeypoint -t bc -v 1 -e 0004 -m 3d -j --offset_crop --decode_first_frame --num_keypoint 32 --decode_attention --total_timesteps 4000000 --seed 99 -u
Train 'Close-Box' environment in Meta-world with baselines
# RAD PPO baseline
python3 train.py --algo pporad -t bc -v 1 -e 0005 --total_timesteps 4000000 --seed 99 -u
# Vanilla PPO baseline
python3 train.py --algo ppopixel -t bc -v 1 -e 0006 --total_timesteps 4000000 --seed 99 -u
Other environments in general
# Any training command follows the following format
python3 train.py -a [algo name] -t [env name] -v [env version] -e [experiment id] [...]
# Any visualization command is simply using the same options but run visualize.py instead of train.py
python3 visualize.py -a [algo name] -t [env name] -v [env version] -e [experiment id] [...]
# For colorless ant, you can change the ant example's [-t ant] flag to [-t antnc]
# For metaworld, you can change the close-box example's [-t bc] flag to other abbreviations such as [-t door] etc.
# For a full list of arugments and their meanings,
python3 train.py -h
Update Log
| Data | Notes |
|---|---|
| Jun/15/21 | Initial release of the code. Email me if you have questions or find any errors in this version. |
| Jun/16/21 | Add all metaworld environments with notes about placeholder observations |
![Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations. [2021]](https://github.com/wvangansbeke/Revisiting-Contrastive-SSL/raw/main/images/teaser.jpg)
 80 Nov 20, 2022
80 Nov 20, 2022

 35 Nov 20, 2022
35 Nov 20, 2022

 49 Nov 10, 2022
49 Nov 10, 2022

 225 Dec 29, 2022
225 Dec 29, 2022

 1 Nov 4, 2022
1 Nov 4, 2022

 1 Jan 12, 2022
1 Jan 12, 2022
 87 Nov 30, 2022
87 Nov 30, 2022

 6 Feb 28, 2022
6 Feb 28, 2022
 23 Oct 19, 2022
23 Oct 19, 2022




 49 Dec 5, 2022
49 Dec 5, 2022
 271 Nov 29, 2022
271 Nov 29, 2022
 1 Feb 11, 2022
1 Feb 11, 2022
 73 Sep 18, 2022
73 Sep 18, 2022
 42 Dec 9, 2022
42 Dec 9, 2022
 114 Oct 16, 2022
114 Oct 16, 2022
 34 Dec 21, 2022
34 Dec 21, 2022
 75 Dec 16, 2022
75 Dec 16, 2022
 293 Dec 20, 2022
293 Dec 20, 2022
 49 Jan 2, 2023
49 Jan 2, 2023