Describe the bug
If i try to run on bare machine i cannot run the MXNet example: https://github.com/bytedance/byteps/blob/master/docs/step-by-step-tutorial.md#mxnet
But if I use the container provided then I am able to run the example.
To Reproduce
Steps to reproduce the behavior:
- Ubuntu 16.04 DLAMI EC2 instance p2.8xlarge (8 k80gpus)
- pip install mxnet-cu100mkl
- pip install byteps==0.2.0
- git clone --recursive https://github.com/bytedance/byteps.git ~/byteps
- run following commands on shell:
export NVIDIA_VISIBLE_DEVICES=0,1,2,3 # gpus list
export DMLC_WORKER_ID=0 # your worker id
export DMLC_NUM_WORKER=1 # one worker
export DMLC_ROLE=worker
export DMLC_NUM_SERVER=1
export DMLC_PS_ROOT_URI=10.0.0.1
export DMLC_PS_ROOT_PORT=1234
bpslaunch python3 ~/byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32
- See error as shown in logs
Expected behavior
To run mxnet example
Logs
(mx_byteps) ubuntu@ip-172-31-85-4:~$ bpslaunch python byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32
BytePS launching worker
INFO:root:start with arguments Namespace(batch_size=32, benchmark=1, cpu_train=False, data_nthreads=4, data_train=None, data_train_idx='', data_val=None, data_val_idx='', disp_batches=20, dtype='float32', gc_threshold=0.5, gc_type='none', image_shape='3,224,224', initializer='default', kv_store='device', load_epoch=None, loss='', lr=0.1, lr_factor=0.1, lr_step_epochs='30,60', macrobatch_size=0, max_random_aspect_ratio=0.25, max_random_h=36, max_random_l=50, max_random_rotate_angle=10, max_random_s=50, max_random_scale=1, max_random_shear_ratio=0.1, min_random_scale=1, model_prefix=None, mom=0.9, monitor=0, network='resnet', num_classes=1000, num_epochs=80, num_examples=1281167, num_layers=50, optimizer='sgd', pad_size=0, random_crop=1, random_mirror=1, rgb_mean='123.68,116.779,103.939', test_io=0, top_k=0, warmup_epochs=5, warmup_strategy='linear', wd=0.0001)
INFO:root:start with arguments Namespace(batch_size=32, benchmark=1, cpu_train=False, data_nthreads=4, data_train=None, data_train_idx='', data_val=None, data_val_idx='', disp_batches=20, dtype='float32', gc_threshold=0.5, gc_type='none', image_shape='3,224,224', initializer='default', kv_store='device', load_epoch=None, loss='', lr=0.1, lr_factor=0.1, lr_step_epochs='30,60', macrobatch_size=0, max_random_aspect_ratio=0.25, max_random_h=36, max_random_l=50, max_random_rotate_angle=10, max_random_s=50, max_random_scale=1, max_random_shear_ratio=0.1, min_random_scale=1, model_prefix=None, mom=0.9, monitor=0, network='resnet', num_classes=1000, num_epochs=80, num_examples=1281167, num_layers=50, optimizer='sgd', pad_size=0, random_crop=1, random_mirror=1, rgb_mean='123.68,116.779,103.939', test_io=0, top_k=0, warmup_epochs=5, warmup_strategy='linear', wd=0.0001)
INFO:root:start with arguments Namespace(batch_size=32, benchmark=1, cpu_train=False, data_nthreads=4, data_train=None, data_train_idx='', data_val=None, data_val_idx='', disp_batches=20, dtype='float32', gc_threshold=0.5, gc_type='none', image_shape='3,224,224', initializer='default', kv_store='device', load_epoch=None, loss='', lr=0.1, lr_factor=0.1, lr_step_epochs='30,60', macrobatch_size=0, max_random_aspect_ratio=0.25, max_random_h=36, max_random_l=50, max_random_rotate_angle=10, max_random_s=50, max_random_scale=1, max_random_shear_ratio=0.1, min_random_scale=1, model_prefix=None, mom=0.9, monitor=0, network='resnet', num_classes=1000, num_epochs=80, num_examples=1281167, num_layers=50, optimizer='sgd', pad_size=0, random_crop=1, random_mirror=1, rgb_mean='123.68,116.779,103.939', test_io=0, top_k=0, warmup_epochs=5, warmup_strategy='linear', wd=0.0001)
INFO:root:start with arguments Namespace(batch_size=32, benchmark=1, cpu_train=False, data_nthreads=4, data_train=None, data_train_idx='', data_val=None, data_val_idx='', disp_batches=20, dtype='float32', gc_threshold=0.5, gc_type='none', image_shape='3,224,224', initializer='default', kv_store='device', load_epoch=None, loss='', lr=0.1, lr_factor=0.1, lr_step_epochs='30,60', macrobatch_size=0, max_random_aspect_ratio=0.25, max_random_h=36, max_random_l=50, max_random_rotate_angle=10, max_random_s=50, max_random_scale=1, max_random_shear_ratio=0.1, min_random_scale=1, model_prefix=None, mom=0.9, monitor=0, network='resnet', num_classes=1000, num_epochs=80, num_examples=1281167, num_layers=50, optimizer='sgd', pad_size=0, random_crop=1, random_mirror=1, rgb_mean='123.68,116.779,103.939', test_io=0, top_k=0, warmup_epochs=5, warmup_strategy='linear', wd=0.0001)
INFO:root:Launch BytePS process on GPU-2
learning rate from ``lr_scheduler`` has been overwritten by ``learning_rate`` in optimizer.
INFO:root:Launch BytePS process on GPU-0
INFO:root:Launch BytePS process on GPU-1
learning rate from ``lr_scheduler`` has been overwritten by ``learning_rate`` in optimizer.
learning rate from ``lr_scheduler`` has been overwritten by ``learning_rate`` in optimizer.
environ({'LESSOPEN': '| /usr/bin/lesspipe %s', 'CONDA_PROMPT_MODIFIER': '(mx_byteps) ', 'BYTEPS_LOCAL_RANK': '2', 'MAIL': '/var/mail/ubuntu', 'SSH_CLIENT': '76.126.245.87 59732 22', 'USER': 'ubuntu', 'LD_LIBRARY_PATH_WITH_DEFAULT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:', 'LD_LIBRARY_PATH': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/home/ubuntu/src/cntk/bindings/python/cntk/libs:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/cuda/efa/lib:/usr/local/cuda/lib:/opt/amazon/efa/lib:/usr/local/mpi/lib:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:', 'SHLVL': '1', 'CONDA_SHLVL': '1', 'HOME': '/home/ubuntu', 'SSH_TTY': '/dev/pts/1', 'DMLC_PS_ROOT_URI': '10.0.0.1', 'LC_TERMINAL_VERSION': '3.3.9', 'DMLC_NUM_SERVER': '1', 'LOGNAME': 'ubuntu', 'DMLC_PS_ROOT_PORT': '1234', '_': '/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch', 'BYTEPS_LOCAL_SIZE': '4', 'PKG_CONFIG_PATH': '/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:', 'XDG_SESSION_ID': '3', 'TERM': 'xterm-256color', 'DMLC_NUM_WORKER': '1', 'PATH': '/home/ubuntu/anaconda3/envs/mx_byteps/bin:/home/ubuntu/anaconda3/bin/:/home/ubuntu/bin:/home/ubuntu/.local/bin:/home/ubuntu/anaconda3/bin/:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/home/ubuntu/src/cntk/bin:/usr/local/mpi/bin:/opt/aws/neuron/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/opt/amazon/openmpi/bin:/opt/amazon/efa/bin/:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'DMLC_ROLE': 'worker', 'XDG_RUNTIME_DIR': '/run/user/1000', 'LANG': 'en_US.UTF-8', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_PYTHON_EXE': '/home/ubuntu/anaconda3/bin/python', 'SHELL': '/bin/bash', 'CONDA_DEFAULT_ENV': 'mx_byteps', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', 'MODULE_VERSION': '3.2.10', 'LD_LIBRARY_PATH_WITHOUT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:', 'LC_TERMINAL': 'iTerm2', 'MODULE_VERSION_STACK': '3.2.10', 'PWD': '/home/ubuntu', 'LOADEDMODULES': '', 'CONDA_EXE': '/home/ubuntu/anaconda3/bin/conda', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '76.126.245.87 59732 172.31.85.4 22', 'PYTHONPATH': '/home/ubuntu/src/cntk/bindings/python', 'DMLC_WORKER_ID': '0', 'NVIDIA_VISIBLE_DEVICES': '0,1,2,3', 'CONDA_PREFIX': '/home/ubuntu/anaconda3/envs/mx_byteps', 'MANPATH': '/opt/aws/neuron/share/man:', 'MODULEPATH': '/etc/environment-modules/modules:/usr/share/modules/versions:/usr/Modules/$MODULE_VERSION/modulefiles:/usr/share/modules/modulefiles', 'MODULESHOME': '/usr/share/modules'})=============2
INFO:root:Launch BytePS process on GPU-3
environ({'LESSOPEN': '| /usr/bin/lesspipe %s', 'CONDA_PROMPT_MODIFIER': '(mx_byteps) ', 'BYTEPS_LOCAL_RANK': '1', 'MAIL': '/var/mail/ubuntu', 'SSH_CLIENT': '76.126.245.87 59732 22', 'USER': 'ubuntu', 'LD_LIBRARY_PATH_WITH_DEFAULT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:', 'LD_LIBRARY_PATH': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/home/ubuntu/src/cntk/bindings/python/cntk/libs:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/cuda/efa/lib:/usr/local/cuda/lib:/opt/amazon/efa/lib:/usr/local/mpi/lib:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:', 'SHLVL': '1', 'CONDA_SHLVL': '1', 'HOME': '/home/ubuntu', 'SSH_TTY': '/dev/pts/1', 'DMLC_PS_ROOT_URI': '10.0.0.1', 'LC_TERMINAL_VERSION': '3.3.9', 'DMLC_NUM_SERVER': '1', 'LOGNAME': 'ubuntu', 'DMLC_PS_ROOT_PORT': '1234', '_': '/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch', 'BYTEPS_LOCAL_SIZE': '4', 'PKG_CONFIG_PATH': '/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:', 'XDG_SESSION_ID': '3', 'TERM': 'xterm-256color', 'DMLC_NUM_WORKER': '1', 'PATH': '/home/ubuntu/anaconda3/envs/mx_byteps/bin:/home/ubuntu/anaconda3/bin/:/home/ubuntu/bin:/home/ubuntu/.local/bin:/home/ubuntu/anaconda3/bin/:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/home/ubuntu/src/cntk/bin:/usr/local/mpi/bin:/opt/aws/neuron/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/opt/amazon/openmpi/bin:/opt/amazon/efa/bin/:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'DMLC_ROLE': 'worker', 'XDG_RUNTIME_DIR': '/run/user/1000', 'LANG': 'en_US.UTF-8', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_PYTHON_EXE': '/home/ubuntu/anaconda3/bin/python', 'SHELL': '/bin/bash', 'CONDA_DEFAULT_ENV': 'mx_byteps', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', 'MODULE_VERSION': '3.2.10', 'LD_LIBRARY_PATH_WITHOUT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:', 'LC_TERMINAL': 'iTerm2', 'MODULE_VERSION_STACK': '3.2.10', 'PWD': '/home/ubuntu', 'LOADEDMODULES': '', 'CONDA_EXE': '/home/ubuntu/anaconda3/bin/conda', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '76.126.245.87 59732 172.31.85.4 22', 'PYTHONPATH': '/home/ubuntu/src/cntk/bindings/python', 'DMLC_WORKER_ID': '0', 'NVIDIA_VISIBLE_DEVICES': '0,1,2,3', 'CONDA_PREFIX': '/home/ubuntu/anaconda3/envs/mx_byteps', 'MANPATH': '/opt/aws/neuron/share/man:', 'MODULEPATH': '/etc/environment-modules/modules:/usr/share/modules/versions:/usr/Modules/$MODULE_VERSION/modulefiles:/usr/share/modules/modulefiles', 'MODULESHOME': '/usr/share/modules'})=============1
learning rate from ``lr_scheduler`` has been overwritten by ``learning_rate`` in optimizer.
environ({'LESSOPEN': '| /usr/bin/lesspipe %s', 'CONDA_PROMPT_MODIFIER': '(mx_byteps) ', 'BYTEPS_LOCAL_RANK': '0', 'MAIL': '/var/mail/ubuntu', 'SSH_CLIENT': '76.126.245.87 59732 22', 'USER': 'ubuntu', 'LD_LIBRARY_PATH_WITH_DEFAULT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:', 'LD_LIBRARY_PATH': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/home/ubuntu/src/cntk/bindings/python/cntk/libs:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/cuda/efa/lib:/usr/local/cuda/lib:/opt/amazon/efa/lib:/usr/local/mpi/lib:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:', 'SHLVL': '1', 'CONDA_SHLVL': '1', 'HOME': '/home/ubuntu', 'SSH_TTY': '/dev/pts/1', 'DMLC_PS_ROOT_URI': '10.0.0.1', 'LC_TERMINAL_VERSION': '3.3.9', 'DMLC_NUM_SERVER': '1', 'LOGNAME': 'ubuntu', 'DMLC_PS_ROOT_PORT': '1234', '_': '/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch', 'BYTEPS_LOCAL_SIZE': '4', 'PKG_CONFIG_PATH': '/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:', 'XDG_SESSION_ID': '3', 'TERM': 'xterm-256color', 'DMLC_NUM_WORKER': '1', 'PATH': '/home/ubuntu/anaconda3/envs/mx_byteps/bin:/home/ubuntu/anaconda3/bin/:/home/ubuntu/bin:/home/ubuntu/.local/bin:/home/ubuntu/anaconda3/bin/:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/home/ubuntu/src/cntk/bin:/usr/local/mpi/bin:/opt/aws/neuron/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/opt/amazon/openmpi/bin:/opt/amazon/efa/bin/:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'DMLC_ROLE': 'worker', 'XDG_RUNTIME_DIR': '/run/user/1000', 'LANG': 'en_US.UTF-8', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_PYTHON_EXE': '/home/ubuntu/anaconda3/bin/python', 'SHELL': '/bin/bash', 'CONDA_DEFAULT_ENV': 'mx_byteps', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', 'MODULE_VERSION': '3.2.10', 'LD_LIBRARY_PATH_WITHOUT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:', 'LC_TERMINAL': 'iTerm2', 'MODULE_VERSION_STACK': '3.2.10', 'PWD': '/home/ubuntu', 'LOADEDMODULES': '', 'CONDA_EXE': '/home/ubuntu/anaconda3/bin/conda', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '76.126.245.87 59732 172.31.85.4 22', 'PYTHONPATH': '/home/ubuntu/src/cntk/bindings/python', 'DMLC_WORKER_ID': '0', 'NVIDIA_VISIBLE_DEVICES': '0,1,2,3', 'CONDA_PREFIX': '/home/ubuntu/anaconda3/envs/mx_byteps', 'MANPATH': '/opt/aws/neuron/share/man:', 'MODULEPATH': '/etc/environment-modules/modules:/usr/share/modules/versions:/usr/Modules/$MODULE_VERSION/modulefiles:/usr/share/modules/modulefiles', 'MODULESHOME': '/usr/share/modules'})=============0
environ({'LESSOPEN': '| /usr/bin/lesspipe %s', 'CONDA_PROMPT_MODIFIER': '(mx_byteps) ', 'BYTEPS_LOCAL_RANK': '3', 'MAIL': '/var/mail/ubuntu', 'SSH_CLIENT': '76.126.245.87 59732 22', 'USER': 'ubuntu', 'LD_LIBRARY_PATH_WITH_DEFAULT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/usr/local/cuda-9.0/lib/:', 'LD_LIBRARY_PATH': '/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:/home/ubuntu/src/cntk/bindings/python/cntk/libs:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/cuda/efa/lib:/usr/local/cuda/lib:/opt/amazon/efa/lib:/usr/local/mpi/lib:/usr/lib64/openmpi/lib/:/usr/local/cuda/lib64:/usr/local/lib:/usr/lib:/usr/local/cuda/extras/CUPTI/lib64:/usr/local/mpi/lib:/lib/:', 'SHLVL': '1', 'CONDA_SHLVL': '1', 'HOME': '/home/ubuntu', 'SSH_TTY': '/dev/pts/1', 'DMLC_PS_ROOT_URI': '10.0.0.1', 'LC_TERMINAL_VERSION': '3.3.9', 'DMLC_NUM_SERVER': '1', 'LOGNAME': 'ubuntu', 'DMLC_PS_ROOT_PORT': '1234', '_': '/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch', 'BYTEPS_LOCAL_SIZE': '4', 'PKG_CONFIG_PATH': '/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:/usr/local/lib/pkgconfig:', 'XDG_SESSION_ID': '3', 'TERM': 'xterm-256color', 'DMLC_NUM_WORKER': '1', 'PATH': '/home/ubuntu/anaconda3/envs/mx_byteps/bin:/home/ubuntu/anaconda3/bin/:/home/ubuntu/bin:/home/ubuntu/.local/bin:/home/ubuntu/anaconda3/bin/:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/home/ubuntu/src/cntk/bin:/usr/local/mpi/bin:/opt/aws/neuron/bin:/usr/local/cuda/bin:/usr/local/bin:/opt/aws/bin:/usr/local/mpi/bin:/opt/amazon/openmpi/bin:/opt/amazon/efa/bin/:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin', 'DMLC_ROLE': 'worker', 'XDG_RUNTIME_DIR': '/run/user/1000', 'LANG': 'en_US.UTF-8', 'LS_COLORS': 'rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;36:*.spx=00;36:*.xspf=00;36:', 'CONDA_PYTHON_EXE': '/home/ubuntu/anaconda3/bin/python', 'SHELL': '/bin/bash', 'CONDA_DEFAULT_ENV': 'mx_byteps', 'LESSCLOSE': '/usr/bin/lesspipe %s %s', 'MODULE_VERSION': '3.2.10', 'LD_LIBRARY_PATH_WITHOUT_CUDA': '/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:/usr/lib64/openmpi/lib/:/usr/local/lib:/usr/lib:/usr/local/mpi/lib:/lib/:', 'LC_TERMINAL': 'iTerm2', 'MODULE_VERSION_STACK': '3.2.10', 'PWD': '/home/ubuntu', 'LOADEDMODULES': '', 'CONDA_EXE': '/home/ubuntu/anaconda3/bin/conda', 'XDG_DATA_DIRS': '/usr/local/share:/usr/share:/var/lib/snapd/desktop', 'SSH_CONNECTION': '76.126.245.87 59732 172.31.85.4 22', 'PYTHONPATH': '/home/ubuntu/src/cntk/bindings/python', 'DMLC_WORKER_ID': '0', 'NVIDIA_VISIBLE_DEVICES': '0,1,2,3', 'CONDA_PREFIX': '/home/ubuntu/anaconda3/envs/mx_byteps', 'MANPATH': '/opt/aws/neuron/share/man:', 'MODULEPATH': '/etc/environment-modules/modules:/usr/share/modules/versions:/usr/Modules/$MODULE_VERSION/modulefiles:/usr/share/modules/modulefiles', 'MODULESHOME': '/usr/share/modules'})=============3
Segmentation fault: 11
Segmentation fault: 11
Stack trace:
[bt] (0) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x41a8100) [0x7fe075c25100]
[bt] (1) /lib/x86_64-linux-gnu/libc.so.6(+0x354b0) [0x7fe1021c34b0]
[bt] (2) /lib/x86_64-linux-gnu/libpthread.so.0(pthread_mutex_lock+0x4) [0x7fe102561d44]
[bt] (3) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x389d737) [0x7fe07531a737]
[bt] (4) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38a0863) [0x7fe07531d863]
[bt] (5) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3896551) [0x7fe075313551]
[bt] (6) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(MXEnginePushAsync+0x2f7) [0x7fe075279a67]
[bt] (7) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/site-packages/byteps/mxnet/c_lib.cpython-36m-x86_64-linux-gnu.so(byteps_mxnet_push_pull_async+0x150) [0x7fdff9762970]
[bt] (8) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/lib-dynload/../../libffi.so.6(ffi_call_unix64+0x4c) [0x7fe1012dfec0]
Stack trace:
[bt] (0) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x41a8100) [0x7f3556934100]
[bt] (1) /lib/x86_64-linux-gnu/libc.so.6(+0x354b0) [0x7f35e2ed24b0]
[bt] (2) /lib/x86_64-linux-gnu/libpthread.so.0(pthread_mutex_lock+0x4) [0x7f35e3270d44]
[bt] (3) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x389d737) [0x7f3556029737]
[bt] (4) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38a0863) [0x7f355602c863]
[bt] (5) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3896551) [0x7f3556022551]
[bt] (6) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(MXEnginePushAsync+0x2f7) [0x7f3555f88a67]
[bt] (7) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/site-packages/byteps/mxnet/c_lib.cpython-36m-x86_64-linux-gnu.so(byteps_mxnet_push_pull_async+0x150) [0x7f34e1762970]
[bt] (8) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/lib-dynload/../../libffi.so.6(ffi_call_unix64+0x4c) [0x7f35e1feeec0]
[2020-03-16 21:41:59*** Error in `.956268: F byteps/common/core_loops.cc:299] Check failed: r == ncclSuccess NCCL error: unhandled cuda error
Segmentation fault: 11
Stack trace:
[bt] (0) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x41a8100) [0x7fefa3442100]
[bt] (1) /lib/x86_64-linux-gnu/libc.so.6(+0x354b0) [0x7ff02f9e04b0]
[bt] (2) /lib/x86_64-linux-gnu/libpthread.so.0(pthread_mutex_lock+0x4) [0x7ff02fd7ed44]
[bt] (3) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x389d737) [0x7fefa2b37737]
[bt] (4) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38a0863) [0x7fefa2b3a863]
[bt] (5) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3896551) [0x7fefa2b30551]
[bt] (6) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(MXEnginePushAsync+0x2f7) [0x7fefa2a96a67]
[bt] (7) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/site-packages/byteps/mxnet/c_lib.cpython-36m-x86_64-linux-gnu.so(byteps_mxnet_push_pull_async+0x150) [0x7fef2d762970]
[bt] (8) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/lib-dynload/../../libffi.so.6(ffi_call_unix64+0x4c) [0x7ff02eafcec0]
Segmentation fault: 11
Segmentation fault: 11
Stack trace:
[bt] (0) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x41a8100) [0x7f14f6979100]
[bt] (1) /lib/x86_64-linux-gnu/libc.so.6(+0x354b0) [0x7f1582f174b0]
[bt] (2) /lib/x86_64-linux-gnu/libpthread.so.0(pthread_mutex_lock+0x4) [0x7f15832b5d44]
[bt] (3) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x389d737) [0x7f14f606e737]
[bt] (4) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38a0863) [0x7f14f6071863]
[bt] (5) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3896551) [0x7f14f6067551]
[bt] (6) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(MXEnginePushAsync+0x2f7) [0x7f14f5fcda67]
[bt] (7) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/site-packages/byteps/mxnet/c_lib.cpython-36m-x86_64-linux-gnu.so(byteps_mxnet_push_pull_async+0x150) [0x7f1481762970]
[bt] (8) /home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/lib-dynload/../../libffi.so.6(ffi_call_unix64+0x4c) [0x7f1582033ec0]
Segmentation fault: 11
Segmentation fault: 11
Stack trace:
[bt] (0) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x41a8100) [0x7f14f6979100]
[bt] (1) /lib/x86_64-linux-gnu/libc.so.6(+0x354b0) [0x7f1582f174b0]
[bt] (2) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x389f261) [0x7f14f6070261]
[bt] (3) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38a0611) [0x7f14f6071611]
[bt] (4) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3896551) [0x7f14f6067551]
[bt] (5) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38974a4) [0x7f14f60684a4]
[bt] (6) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(mxnet::NDArray::Chunk::~Chunk()+0x48a) [0x7f14f629056a]
[bt] (7) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x6d860a) [0x7f14f2ea960a]
[bt] (8) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3ab7101) [0x7f14f6288101]
Stack trace:
[bt] (0) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x41a8100) [0x7f14f6979100]
[bt] (1) /lib/x86_64-linux-gnu/libc.so.6(+0x354b0) [0x7f1582f174b0]
[bt] (2) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x389f261) [0x7f14f6070261]
[bt] (3) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38a0611) [0x7f14f6071611]
[bt] (4) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3896551) [0x7f14f6067551]
[bt] (5) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x38974a4) [0x7f14f60684a4]
[bt] (6) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(mxnet::NDArray::Chunk::~Chunk()+0x48a) [0x7f14f629056a]
[bt] (7) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x6d860a) [0x7f14f2ea960a]
[bt] (8) /home/ubuntu/.local/lib/python3.6/site-packages/mxnet/libmxnet.so(+0x3ab7101) [0x7f14f6288101]
Aborted (core dumped)
Exception in thread Thread-4:
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch", line 47, in worker
subprocess.check_call(command, env=my_env, stdout=sys.stdout, stderr=sys.stderr, shell=True)
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/subprocess.py", line 311, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'python byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32' returned non-zero exit status 134.
Segmentation fault (core dumped)
Exception in thread Thread-3:
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch", line 47, in worker
subprocess.check_call(command, env=my_env, stdout=sys.stdout, stderr=sys.stderr, shell=True)
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/subprocess.py", line 311, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'python byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32' returned non-zero exit status 139.
Segmentation fault (core dumped)
Exception in thread Thread-1:
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch", line 47, in worker
subprocess.check_call(command, env=my_env, stdout=sys.stdout, stderr=sys.stderr, shell=True)
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/subprocess.py", line 311, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'python byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32' returned non-zero exit status 139.
Segmentation fault (core dumped)
Exception in thread Thread-2:
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/ubuntu/anaconda3/envs/mx_byteps/bin/bpslaunch", line 47, in worker
subprocess.check_call(command, env=my_env, stdout=sys.stdout, stderr=sys.stderr, shell=True)
File "/home/ubuntu/anaconda3/envs/mx_byteps/lib/python3.6/subprocess.py", line 311, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'python byteps/example/mxnet/train_imagenet_byteps.py --benchmark 1 --batch-size=32' returned non-zero exit status 139.
Environment (please complete the following information):
- OS: Ubuntu 16.04
- GCC version: 5.4.0
- CUDA and NCCL version: CUDA 10.0 and NCCL 2.4.7
- Framework (TF, PyTorch, MXNet): MXNet
bug


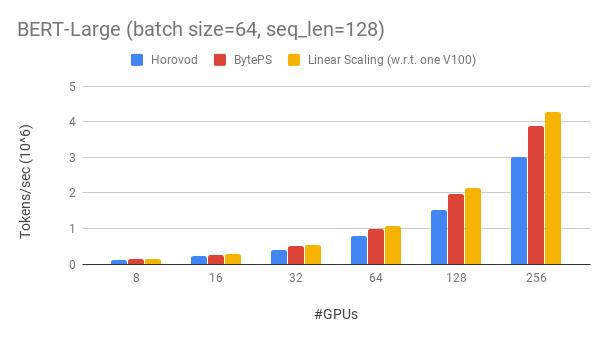





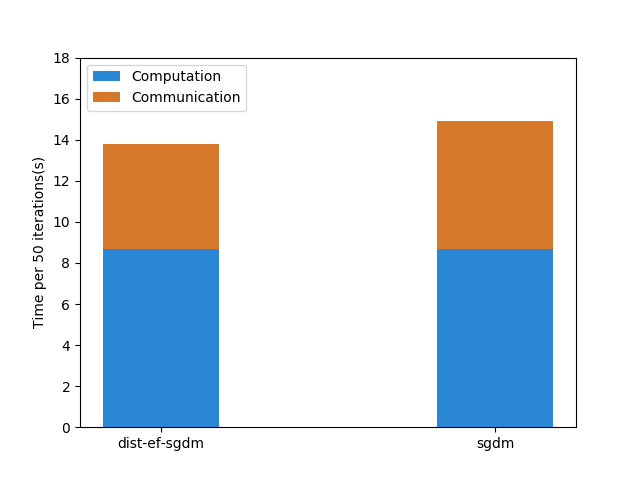
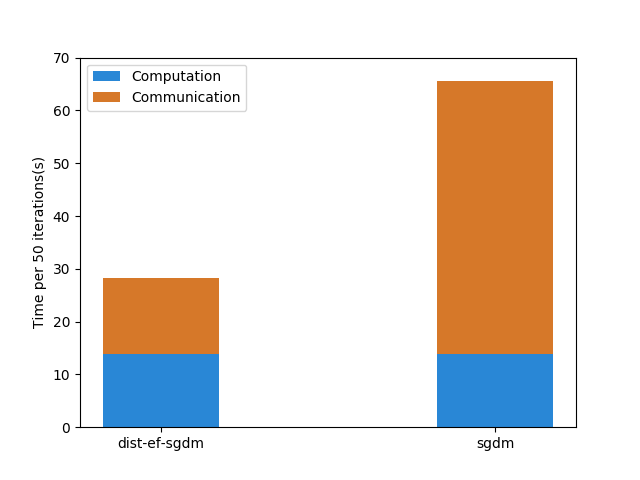
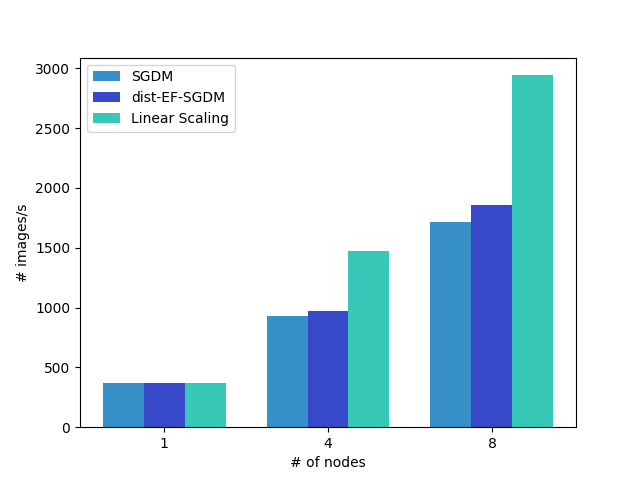
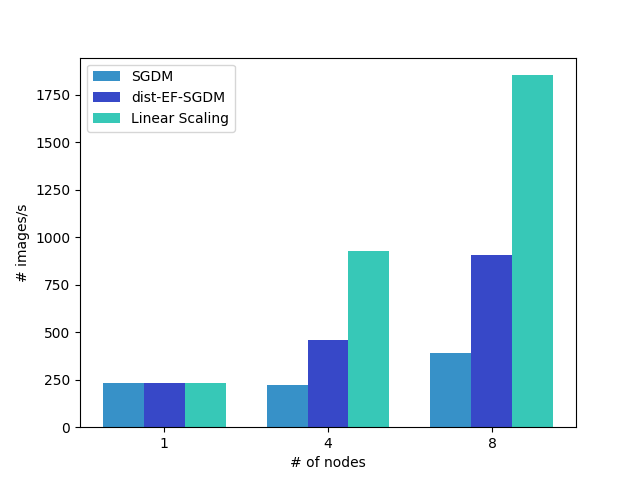
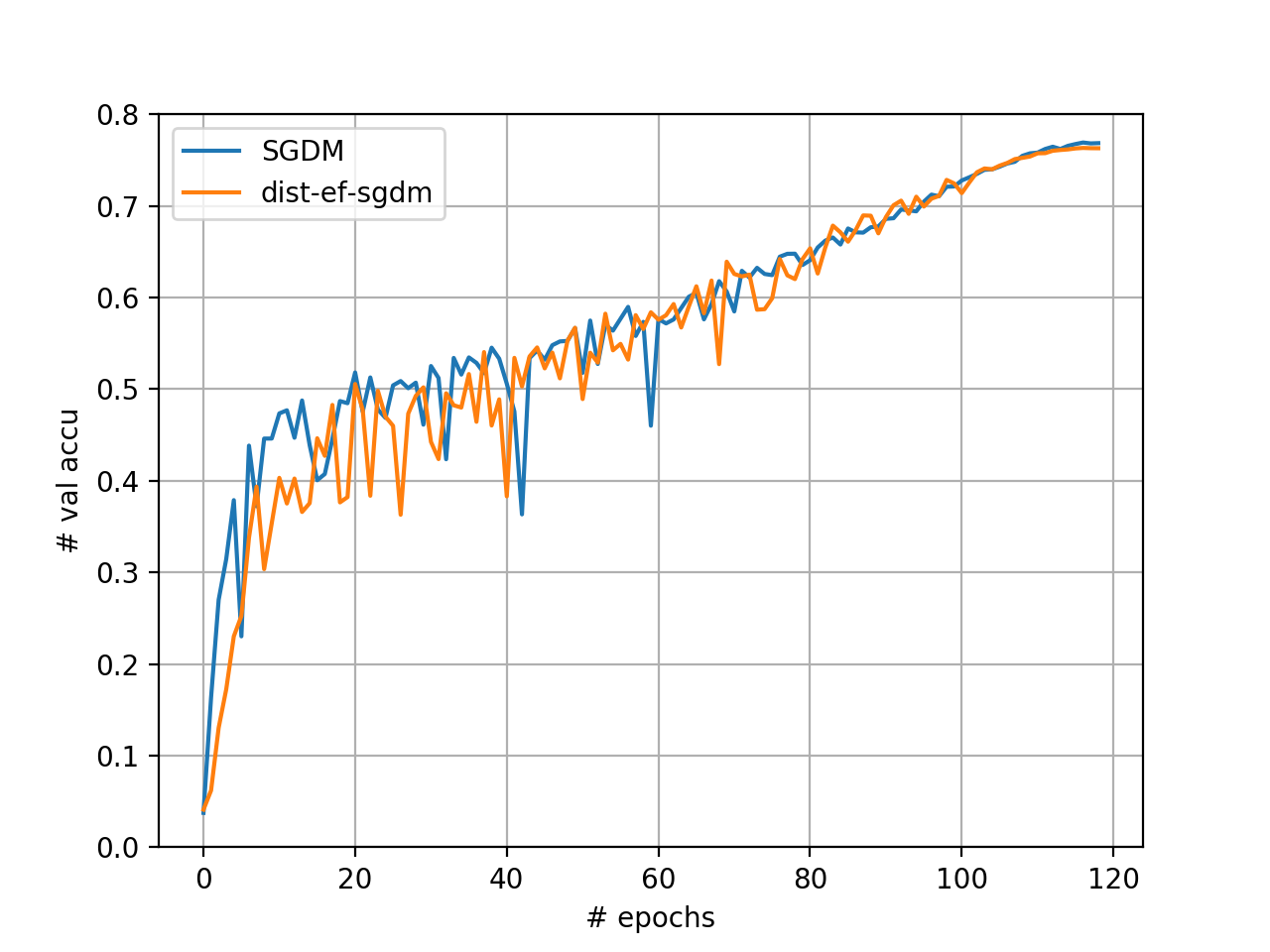
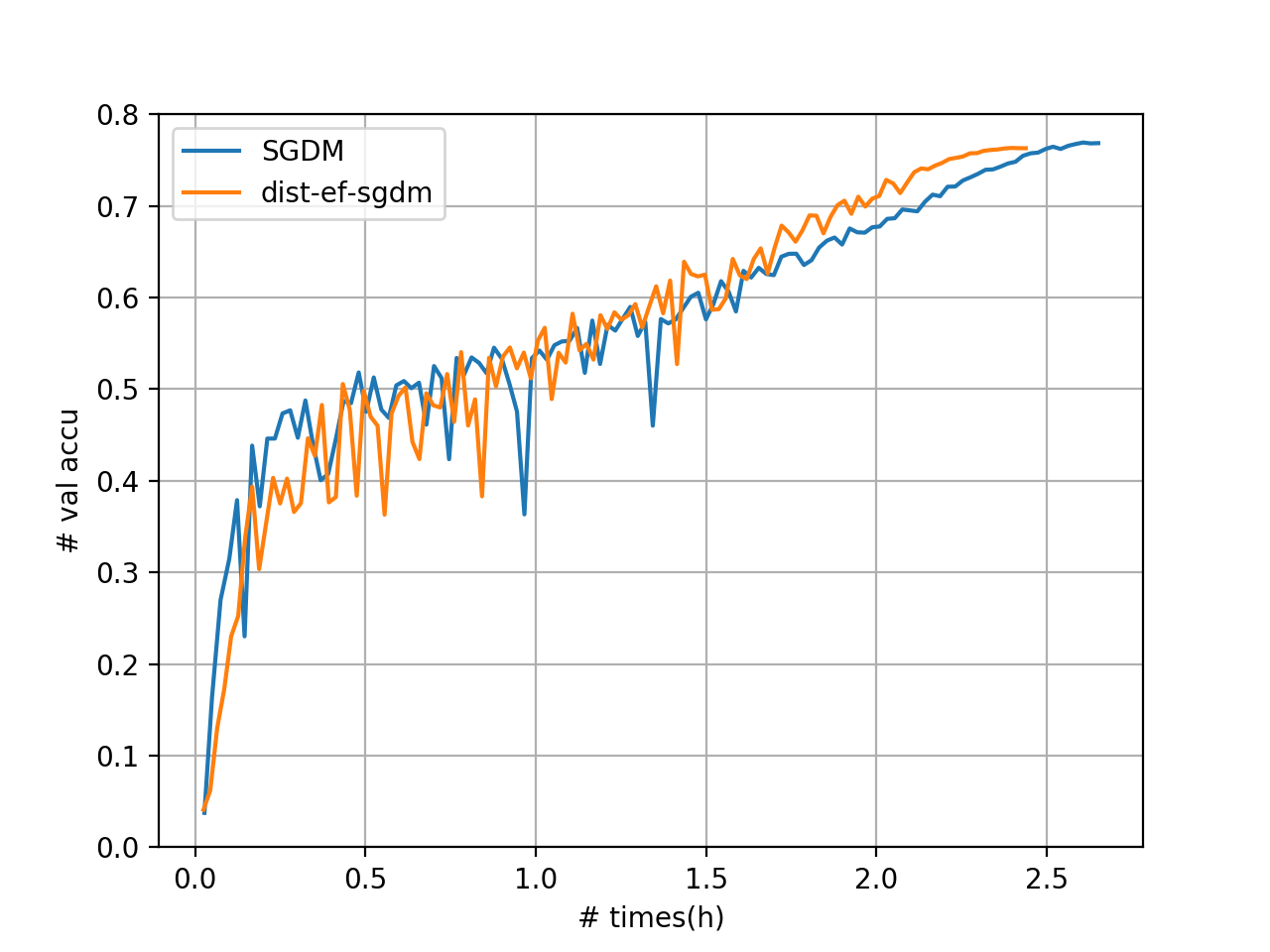
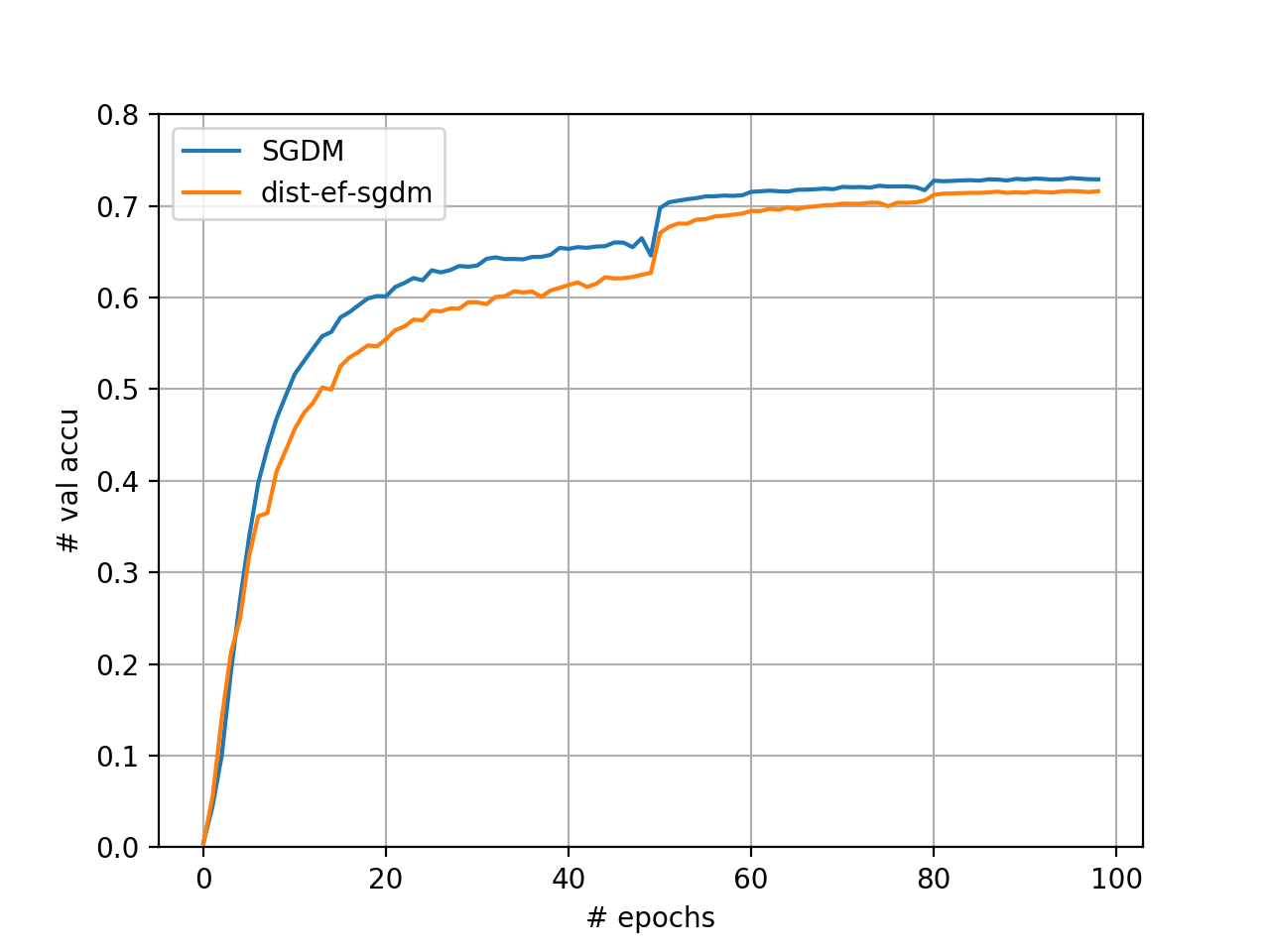

 server
server
 worker0
worker0
 worker1
worker1
















 92 Dec 14, 2022
92 Dec 14, 2022
 2k Dec 28, 2022
2k Dec 28, 2022
 241 Dec 26, 2022
241 Dec 26, 2022
 164 Jan 4, 2023
164 Jan 4, 2023
 12.9k Jan 7, 2023
12.9k Jan 7, 2023
 3 Nov 24, 2021
3 Nov 24, 2021
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
 3k Jan 8, 2023
3k Jan 8, 2023
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
 6 Jun 18, 2022
6 Jun 18, 2022
 174 Dec 7, 2022
174 Dec 7, 2022
 200 Dec 14, 2022
200 Dec 14, 2022
 4.1k Jan 9, 2023
4.1k Jan 9, 2023
 23.6k Jan 3, 2023
23.6k Jan 3, 2023
 1.6k Dec 29, 2022
1.6k Dec 29, 2022