Introduction
DistML is a Ray extension library to support large-scale distributed ML training on heterogeneous multi-node multi-GPU clusters. This library is under active development and we are adding more advanced training strategies and auto-parallelization features.
DistML currently supports:
-
Distributed training strategies
- Data parallelism
- AllReduce strategy
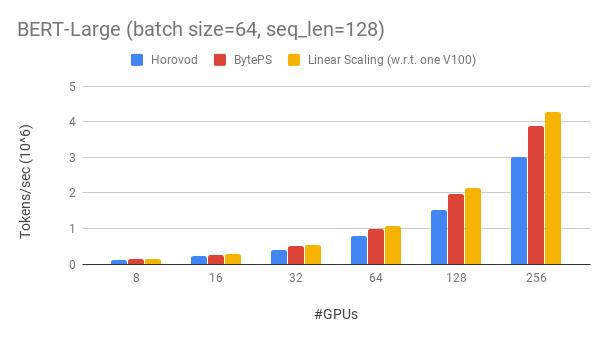
- Sharded parameter server strategy
- BytePS strategy Pipeline parallleism
- Micro-batch pipeline parallelism
- Data parallelism
-
DL Frameworks:
- PyTorch
- JAX
Installation
Install Dependencies
Depending on your CUDA version, install cupy following https://docs.cupy.dev/en/stable/install.html.
Install from source for dev
pip install -e .

 12.9k Jan 7, 2023
12.9k Jan 7, 2023
 3.3k Dec 28, 2022
3.3k Dec 28, 2022
 6 Jun 18, 2022
6 Jun 18, 2022

 393 Dec 27, 2022
393 Dec 27, 2022
 6.9k Jan 5, 2023
6.9k Jan 5, 2023

 216 Dec 30, 2022
216 Dec 30, 2022
 16 Sep 23, 2022
16 Sep 23, 2022
 23.6k Jan 3, 2023
23.6k Jan 3, 2023
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
![[DistML] Basic AllReduce data-parallelism and torch training operator](https://avatars.githubusercontent.com/u/1654062?v=4)


 23.3k Dec 31, 2022
23.3k Dec 31, 2022
 2.5k Dec 28, 2022
2.5k Dec 28, 2022
 239 Nov 10, 2022
239 Nov 10, 2022
 2k Dec 28, 2022
2k Dec 28, 2022
 131 Dec 12, 2022
131 Dec 12, 2022
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
 8.4k Dec 30, 2022
8.4k Dec 30, 2022
 3.8k Jan 4, 2023
3.8k Jan 4, 2023
 2 Apr 18, 2022
2 Apr 18, 2022
 4 Feb 16, 2022
4 Feb 16, 2022