MVSS-Net
Code and models for ICCV 2021 paper: Image Manipulation Detection by Multi-View Multi-Scale Supervision
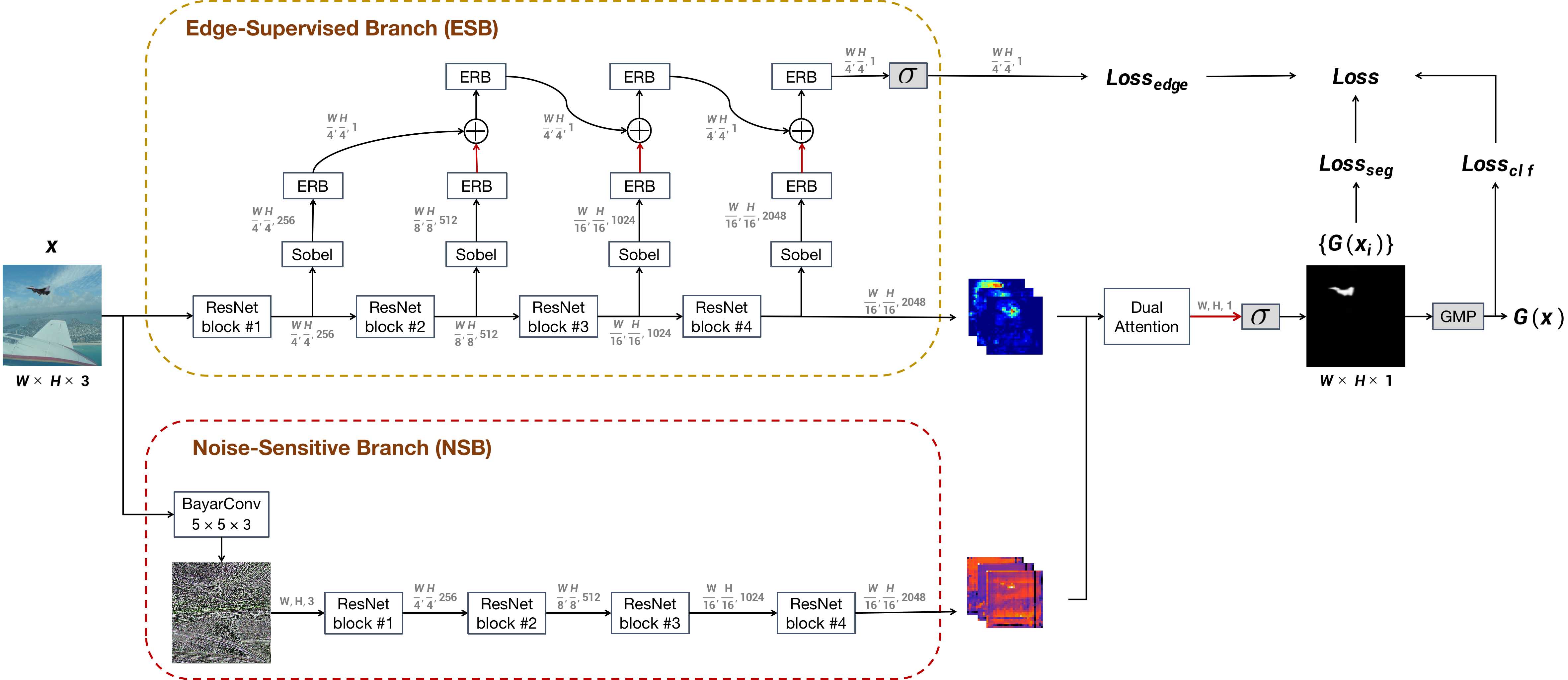
Update
- 22.02.17, Pretrained model for Real-World Image Foregery Localization Challange
To Be Done.
- 21.12.17, Something new: MVSS-Net++
We now have an improved version of MVSS-Net, denoted as MVSS-Net++. Check here.
Environment
- Ubuntu 16.04.6 LTS
- Python 3.6
- cuda10.1+cudnn7.6.3
Requirements
- Install nvidia-apex and move it to current directory.
- pip install requirements.txt
Usage
Dataset
An example of the dataset index file is given as data/CASIAv1plus.txt, where each line contains:
img_path mask_path label
- 0 represents the authentic and 1 represents the manipulated.
- For an authentic image, the mask_path is "None".
- For wild images without mask groundtruth, the index should at least contain "img_path" per line.
Training sets
Test sets
- DEFACTO-12k
- Columbia
- COVER
- NIST16
- CASIAv1plus: Note that some of the authentic images in CASIAv1 also appear in CASIAv2. With those images fully replaced by Corel images that are new to both CASIAv1 and CASIAv2, we constructed a revision of CASIAv1 termed as CASIAv1plus. We recommend to use CASIAv1plus as an alternative to the original CASIAv1.
Trained Models
We offer FCNs and MVSS-Nets trained on CASIAv2 and DEFACTO_84k, respectively. Please download the models and place them in the ckpt directory:
- 百度网盘 (提取码:mvss)
- Google drive
The performance of these models for image-level manipulation detection (metric: AUC and image-level F1) is as follows. More details are reported in the paper.
Performance metric: AUC
| Model | Training data | CASIAv1plus | Columbia | COVER | DEFACTO-12k |
|---|---|---|---|---|---|
| MVSS_Net | CASIAv2 | 0.932 | 0.980 | 0.731 | 0.573 |
| MVSS_Net | DEFACTO-84k | 0.771 | 0.563 | 0.525 | 0.886 |
| FCN | CASIAv2 | 0.769 | 0.762 | 0.541 | 0.551 |
| FCN | DEFACTO-84k | 0.629 | 0.535 | 0.543 | 0.840 |
Performance metric: Image-level F1 (threshold=0.5)
| Model | Training data | CASIAv1plus | Columbia | COVER | DEFACTO-12k |
|---|---|---|---|---|---|
| MVSS_Net | CASIAv2 | 0.759 | 0.802 | 0.244 | 0.404 |
| MVSS_Net | DEFACTO-84k | 0.685 | 0.353 | 0.360 | 0.799 |
| FCN | CASIAv2 | 0.684 | 0.481 | 0.180 | 0.458 |
| FCN | DEFACTO-84k | 0.561 | 0.492 | 0.511 | 0.709 |
Inference & Evaluation
You can specify which pre-trained model to use by setting model_path in do_pred_and_eval.sh. Given a test_collection (e.g. CASIAv1plus or DEFACTO12k-test), the prediction maps and evaluation results will be saved under save_dir. The default threshold is set as 0.5.
bash do_pred_and_eval.sh $test_collection
#e.g. bash do_pred_and_eval.sh CASIAv1plus
For inference only, use following command to skip evaluation:
bash do_pred.sh $test_collection
#e.g. bash do_pred.sh CASIAv1plus
Demo
- demo.ipynb: A step-by-step notebook tutorial showing the usage of a pre-trained model to detect manipulation in a specific image.
Citation
If you find this work useful in your research, please consider citing:
@InProceedings{MVSS_2021ICCV,
author = {Chen, Xinru and Dong, Chengbo and Ji, Jiaqi and Cao, juan and Li, Xirong},
title = {Image Manipulation Detection by Multi-View Multi-Scale Supervision},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
year = {2021}
}
Acknowledgments
- Nvidia-apex is adopted for semi-precision training/inferencing.
- The implement of DA module is based on the awesome-semantic-segmentation-pytorch.
Contact
If you enounter any issue when running the code, please feel free to reach us either by creating a new issue in the github or by emailing
- Xinru Chen ([email protected])
- Chengbo Dong ([email protected])
















 From this picture, most models have relatively clear judgments on the tampered area in most cases. Why can the F1 scores of most models be doubled or even tripled only by adjusting the optimal threshold? Effect of the threshold seem excessive?
From this picture, most models have relatively clear judgments on the tampered area in most cases. Why can the F1 scores of most models be doubled or even tripled only by adjusting the optimal threshold? Effect of the threshold seem excessive?

 58 Jan 6, 2023
58 Jan 6, 2023
 332 Jan 3, 2023
332 Jan 3, 2023
 11 Feb 8, 2022
11 Feb 8, 2022
 118 Jan 4, 2023
118 Jan 4, 2023
 129 Dec 11, 2022
129 Dec 11, 2022
 190 Dec 30, 2022
190 Dec 30, 2022
 47 Oct 11, 2022
47 Oct 11, 2022
 621 Dec 31, 2022
621 Dec 31, 2022
 88 Nov 22, 2022
88 Nov 22, 2022
 64 Dec 12, 2022
64 Dec 12, 2022
 118 Dec 26, 2022
118 Dec 26, 2022
 63 Dec 16, 2022
63 Dec 16, 2022
 58 Dec 28, 2022
58 Dec 28, 2022
 66 Jan 4, 2023
66 Jan 4, 2023
 52 Jan 7, 2023
52 Jan 7, 2023
 470 Dec 30, 2022
470 Dec 30, 2022
 337 Dec 15, 2022
337 Dec 15, 2022
 10 Oct 28, 2022
10 Oct 28, 2022
 689 Dec 25, 2022
689 Dec 25, 2022