🔉
Sound-guided Semantic Image Manipulation (CVPR2022)
Official Pytorch Implementation

Sound-guided Semantic Image Manipulation
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022
Paper : https://arxiv.org/abs/2112.00007
Project Page: https://kuai-lab.github.io/cvpr2022sound/
Seung Hyun Lee, Wonseok Roh, Wonmin Byeon, Sang Ho Yoon, Chanyoung Kim, Jinkyu Kim*, and Sangpil Kim*
Abstract: The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal~(image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.
💾
Installation
For all the methods described in the paper, is it required to have:
- Anaconda
- CLIP
Specific requirements for each method are described in its section. To install CLIP please run the following commands:
conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=<CUDA_VERSION>
pip install ftfy regex tqdm gdown
pip install git+https://github.com/openai/CLIP.git
🔨
Method
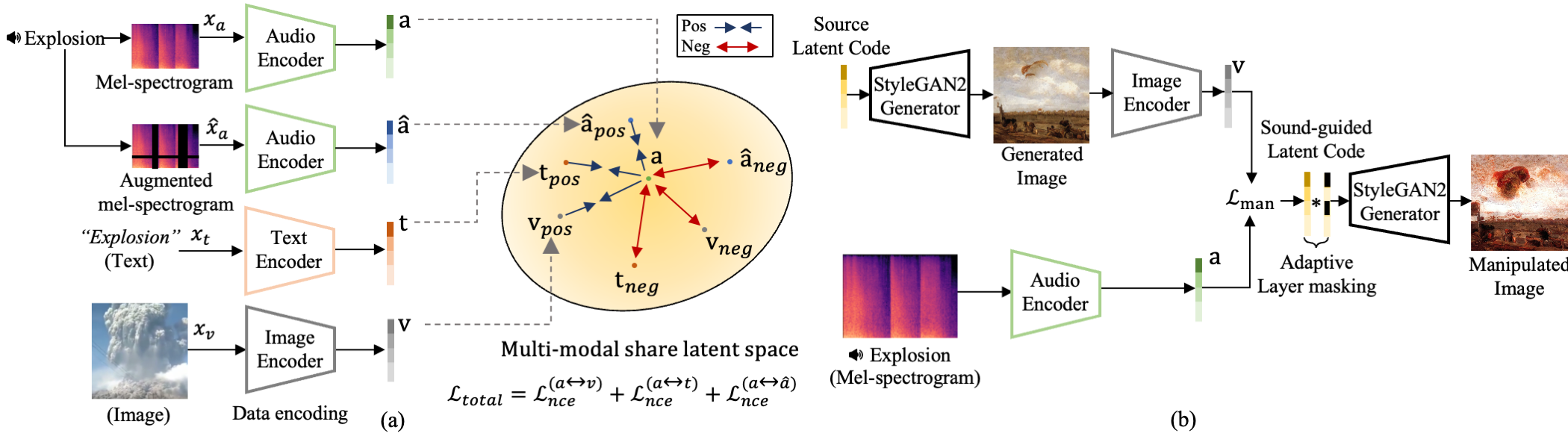
1. CLIP-based Contrastive Latent Representation Learning.
Dataset Curation.
We create an audio-text pair dataset with the vggsound dataset. We also used the audioset dataset as the script below.
- Please download
vggsound.csvfrom the link. - Execute
download.pyto download the audio file of the vggsound dataset. - Execute
curate.pyto preprocess the audio file (wav to mel-spectrogram).
cd soundclip
python3 download.py
python3 curate.py
Training.
python3 train.py
2. Sound-Guided Image Manipulation.
Direct Latent Code Optimization.
The code relies on the StyleCLIP pytorch implementation.
python3 optimization/run_optimization.py --lambda_similarity 0.002 --lambda_identity 0.0 --truncation 0.7 --lr 0.1 --audio_path "./audiosample/explosion.wav" --ckpt ./pretrained_models/landscape.pt --stylegan_size 256
⛳
Results
Zero-shot Audio Classification Accuracy.
| Model | Supervised Setting | Zero-Shot | ESC-50 | UrbanSound 8K |
|---|---|---|---|---|
| ResNet50 |
|
- | 66.8% | 71.3% |
| Ours (Without Self-Supervised) | - | - | 58.7% | 63.3% |
|
|
- | - | 72.2% | 66.8% |
| Wav2clip | - |
|
41.4% | 40.4% |
| AudioCLIP | - |
|
69.4% | 68.8% |
| Ours (Without Self-Supervised) | - |
|
49.4% | 45.6% |
|
|
- |
|
57.8% | 45.7% |
Manipulation Results.
LSUN.

FFHQ.

To see more diverse examples, please visit our project page!
Citation
@article{lee2021sound,
title={Sound-Guided Semantic Image Manipulation},
author={Lee, Seung Hyun and Roh, Wonseok and Byeon, Wonmin and Yoon, Sang Ho and Kim, Chan Young and Kim, Jinkyu and Kim, Sangpil},
journal={arXiv preprint arXiv:2112.00007},
year={2021}
}
 3 Aug 20, 2022
3 Aug 20, 2022

 150 Dec 26, 2022
150 Dec 26, 2022

 153 Dec 2, 2022
153 Dec 2, 2022

 88 Nov 22, 2022
88 Nov 22, 2022
![[CVPR 2022] Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels](https://github.com/Haochen-Wang409/U2PL/raw/main/img/pipeline.png)
 268 Dec 24, 2022
268 Dec 24, 2022

 113 Dec 27, 2022
113 Dec 27, 2022

 102 Dec 25, 2022
102 Dec 25, 2022

 113 Dec 21, 2022
113 Dec 21, 2022

 31 Sep 27, 2022
31 Sep 27, 2022





 87 Jan 8, 2023
87 Jan 8, 2023
 48 Dec 30, 2022
48 Dec 30, 2022
 80 Dec 8, 2022
80 Dec 8, 2022
 27 Dec 1, 2022
27 Dec 1, 2022
 7 Oct 30, 2022
7 Oct 30, 2022
 37 Nov 27, 2022
37 Nov 27, 2022
 141 Dec 30, 2022
141 Dec 30, 2022
 47 Oct 11, 2022
47 Oct 11, 2022
 337 Dec 15, 2022
337 Dec 15, 2022
 127 Dec 27, 2022
127 Dec 27, 2022