Note: We're moving to PyTorch Lightning! Read about the move here. From the end of February, torchbearer will no longer be actively maintained. We'll continue to fix bugs when they are found and ensure that torchbearer runs on new versions of pytorch. However, we won't plan or implement any new functionality (if there's something you'd like to see in a training library, consider creating an issue on PyTorch Lightning).
![]()

Website • Docs • Examples • Install • Citing • Related
A PyTorch model fitting library designed for use by researchers (or anyone really) working in deep learning or differentiable programming. Specifically, we aim to dramatically reduce the amount of boilerplate code you need to write without limiting the functionality and openness of PyTorch.
Examples
General
 |
Quickstart: Get up and running with torchbearer, training a simple CNN on CIFAR-10. | |
| |
||
| |
||
 |
Callbacks: A detailed exploration of callbacks in torchbearer, with some useful visualisations. | |
| |
||
| |
||
 |
Imaging: A detailed exploration of the imaging sub-package in torchbearer, useful for showing visualisations during training. | |
| |
||
| |
||
| Serialization: This guide gives an introduction to serializing and restarting training in torchbearer. | |
|
| |
||
| |
||
| History and Replay: This guide gives an introduction to the history returned by a trial and the ability to replay training. | |
|
| |
||
| |
||
| Custom Data Loaders: This guide gives an introduction on how to run custom data loaders in torchbearer. | |
|
| |
||
| |
||
| Data Parallel: This guide gives an introduction to using torchbearer with DataParrallel. | |
|
| |
||
| |
||
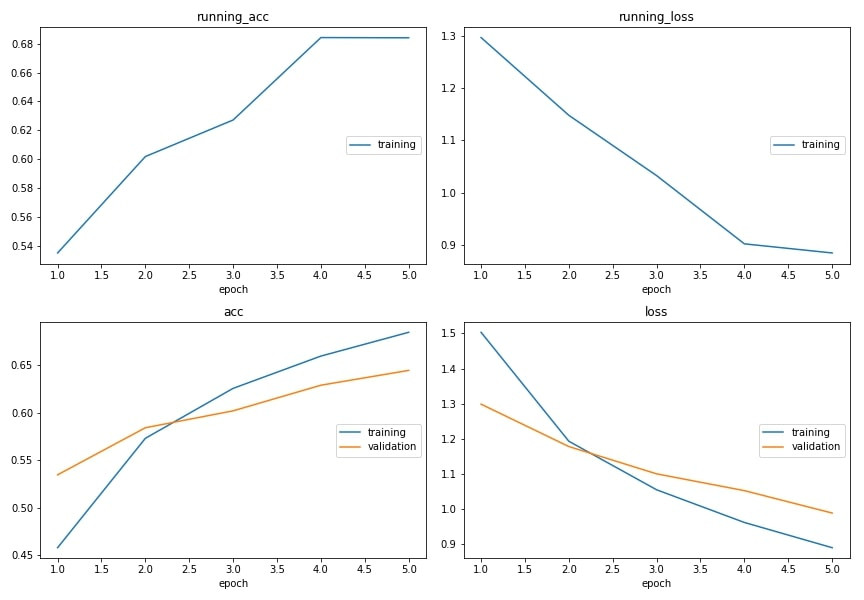 |
LiveLossPlot: A demonstration of the LiveLossPlot callback included in torchbearer. | |
| |
||
| |
||
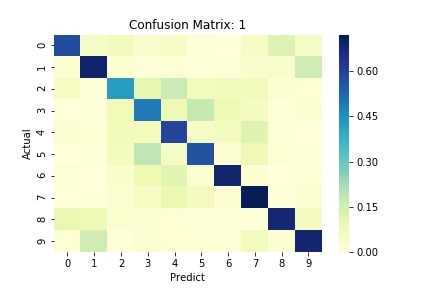 |
PyCM: A demonstration of the PyCM callback included in torchbearer for generating confusion matrices. | |
| |
||
| |
||
| NVIDIA Apex: A guide showing how to perform half and mixed precision training in torchbearer with NVIDIA Apex. | |
|
| |
||
| |
||
Deep Learning
 |
Training a VAE: A demonstration of how to train (add do a simple visualisation of) a Variational Auto-Encoder (VAE) on MNIST with torchbearer. | |
| |
||
| |
||
 |
Training a GAN: A demonstration of how to train (add do a simple visualisation of) a Generative Adversarial Network (GAN) on MNIST with torchbearer. | |
| |
||
| |
||
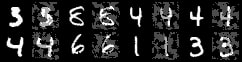 |
Generating Adversarial Examples: A demonstration of how to perform a simple adversarial attack with torchbearer. | |
| |
||
| |
||
| |
Transfer Learning with Torchbearer: A demonstration of how to perform transfer learning on STL10 with torchbearer. | |
| |
||
| |
||
 |
Regularisers in Torchbearer: A demonstration of how to use all of the built-in regularisers in torchbearer (Mixup, CutOut, CutMix, Random Erase, Label Smoothing and Sample Pairing). | |
| |
||
| |
||
| Manifold Mixup: A demonstration of how to use the Manifold Mixup callback in Torchbearer. | |
|
| |
||
| |
||
 |
Class Appearance Model: A demonstration of the Class Appearance Model (CAM) callback in torchbearer. | |
| |
||
| |
||
Differentiable Programming
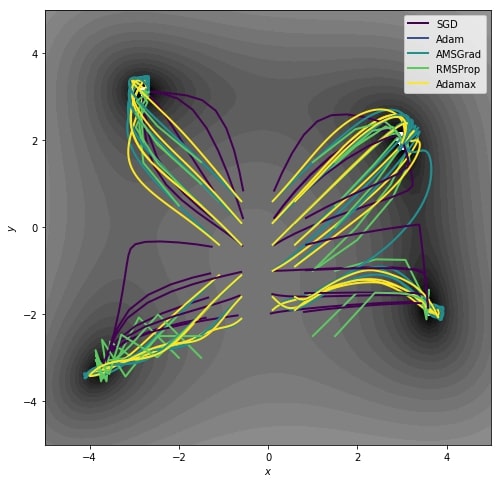 |
Optimising Functions: An example (and some fun visualisations) showing how torchbearer can be used for the purpose of optimising functions with respect to their parameters using gradient descent. | |
| |
||
| |
||
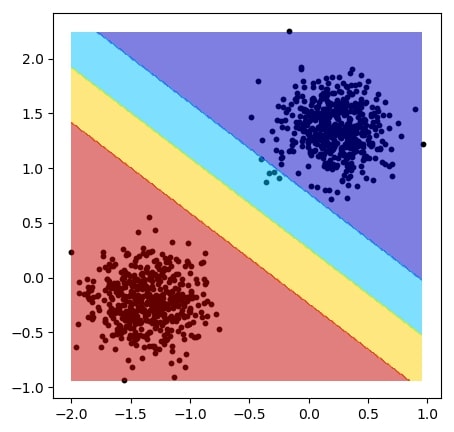 |
Linear SVM: Train a linear support vector machine (SVM) using torchbearer, with an interactive visualisation! | |
| |
||
| |
||
 |
Breaking Adam: The Adam optimiser doesn't always converge, in this example we reimplement some of the function optimisations from the AMSGrad paper showing this empirically. | |
| |
||
| |
Install
The easiest way to install torchbearer is with pip:
pip install torchbearer
Alternatively, build from source with:
pip install git+https://github.com/pytorchbearer/torchbearer
Citing Torchbearer
If you find that torchbearer is useful to your research then please consider citing our preprint: Torchbearer: A Model Fitting Library for PyTorch, with the following BibTeX entry:
@article{torchbearer2018,
author = {Ethan Harris and Matthew Painter and Jonathon Hare},
title = {Torchbearer: A Model Fitting Library for PyTorch},
journal = {arXiv preprint arXiv:1809.03363},
year = {2018}
}
Related
Torchbearer isn't the only library for training PyTorch models. Here are a few others that might better suit your needs (this is by no means a complete list, see the awesome pytorch list or the incredible pytorch for more):
- skorch, model wrapper that enables use with scikit-learn - crossval etc. can be very useful
- PyToune, simple Keras style API
- ignite, advanced model training from the makers of PyTorch, can need a lot of code for advanced functions (e.g. Tensorboard)
- TorchNetTwo (TNT), can be complex to use but well established, somewhat replaced by ignite
- Inferno, training utilities and convenience classes for PyTorch
- Pytorch Lightning, lightweight wrapper on top of PyTorch with advanced multi-gpu and cluster support
- Pywick, high-level training framework, based on torchsample, support for various segmentation models











 873 Dec 15, 2022
873 Dec 15, 2022
 44 Dec 1, 2022
44 Dec 1, 2022
 6 Dec 8, 2022
6 Dec 8, 2022
 3 Mar 30, 2022
3 Mar 30, 2022
 210 Dec 21, 2022
210 Dec 21, 2022
 865 Dec 24, 2022
865 Dec 24, 2022
 5 Nov 19, 2022
5 Nov 19, 2022
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
 97 Jan 3, 2023
97 Jan 3, 2023
 109 Dec 28, 2022
109 Dec 28, 2022
 47 Jul 26, 2022
47 Jul 26, 2022
 19 Dec 10, 2022
19 Dec 10, 2022
 137 Jan 3, 2023
137 Jan 3, 2023
 6 Dec 1, 2022
6 Dec 1, 2022
 12 Nov 9, 2022
12 Nov 9, 2022
 7 Aug 16, 2022
7 Aug 16, 2022
 1 Oct 24, 2021
1 Oct 24, 2021
 9 Oct 31, 2022
9 Oct 31, 2022
 2 Jan 17, 2022
2 Jan 17, 2022