🐛 Describe the bug
I ran the example of diffusion according to https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion:
steps:
conda env create -f environment.yaml
conda activate ldm
pip install colossalai==0.1.10+torch1.11cu11.3 -f https://release.colossalai.org
git clone https://github.com/Lightning-AI/lightning && cd lightning && git reset --hard b04a7aa
pip install -r requirements.txt && pip install .
dataset:
laion-400m
run:
bash train.sh
failed info:
**/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/strategies/ddp.py:438: UserWarning: Error handling mechanism for deadlock detection is uninitialized. Skipping check.
rank_zero_warn("Error handling mechanism for deadlock detection is uninitialized. Skipping check.")
Traceback (most recent call last):
File "/home/code/ColossalAI/examples/images/diffusion/main.py", line 811, in
trainer.fit(model, data)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 579, in fit
call._call_and_handle_interrupt(
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/call.py", line 38, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 621, in _fit_impl
self._run(model, ckpt_path=self.ckpt_path)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1058, in _run
results = self._run_stage()
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1137, in _run_stage
self._run_train()
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1160, in _run_train
self.fit_loop.run()
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/fit_loop.py", line 267, in advance
self._outputs = self.epoch_loop.run(self._data_fetcher)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 214, in advance
batch_output = self.batch_loop.run(kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/batch/training_batch_loop.py", line 88, in advance
outputs = self.optimizer_loop.run(optimizers, kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/loop.py", line 199, in run
self.advance(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 200, in advance
result = self._run_optimization(kwargs, self._optimizers[self.optim_progress.optimizer_position])
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 247, in _run_optimization
self._optimizer_step(optimizer, opt_idx, kwargs.get("batch_idx", 0), closure)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 357, in _optimizer_step
self.trainer._call_lightning_module_hook(
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1302, in _call_lightning_module_hook
output = fn(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/core/module.py", line 1661, in optimizer_step
optimizer.step(closure=optimizer_closure)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/core/optimizer.py", line 169, in step
step_output = self._strategy.optimizer_step(self._optimizer, self._optimizer_idx, closure, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/strategies/colossalai.py", line 368, in optimizer_step
return self.precision_plugin.optimizer_step(
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/plugins/precision/colossalai.py", line 74, in optimizer_step
closure_result = closure()
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 147, in call
self._result = self.closure(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 133, in closure
step_output = self._step_fn()
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/loops/optimization/optimizer_loop.py", line 406, in _training_step
training_step_output = self.trainer._call_strategy_hook("training_step", *kwargs.values())
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py", line 1440, in _call_strategy_hook
output = fn(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/strategies/ddp.py", line 352, in training_step
return self.model(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/colossalai/nn/parallel/data_parallel.py", line 241, in forward
outputs = self.module(*args, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/pytorch_lightning/overrides/base.py", line 98, in forward
output = self._forward_module.training_step(*inputs, **kwargs)
File "/home/code/ColossalAI/examples/images/diffusion/ldm/models/diffusion/ddpm.py", line 411, in training_step
loss, loss_dict = self.shared_step(batch)
File "/home/code/ColossalAI/examples/images/diffusion/ldm/models/diffusion/ddpm.py", line 976, in shared_step
loss = self(x, c)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home/code/ColossalAI/examples/images/diffusion/ldm/models/diffusion/ddpm.py", line 988, in forward
return self.p_losses(x, c, t, *args, **kwargs)
File "/home/code/ColossalAI/examples/images/diffusion/ldm/models/diffusion/ddpm.py", line 1122, in p_losses
model_output = self.apply_model(x_noisy, t, cond)
File "/home/code/ColossalAI/examples/images/diffusion/ldm/models/diffusion/ddpm.py", line 1094, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home/code/ColossalAI/examples/images/diffusion/ldm/models/diffusion/ddpm.py", line 1519, in forward
out = self.diffusion_model(x, t, context=cc)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/home/code/ColossalAI/examples/images/diffusion/ldm/modules/diffusionmodules/openaimodel.py", line 927, in forward
h = th.cat([h, hs.pop()], dim=1)
File "/opt/conda/envs/ldm/lib/python3.9/site-packages/colossalai/tensor/colo_tensor.py", line 170, in torch_function
ret = func(*args, kwargs)
RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 8 but got size 7 for tensor number 1 in the list.
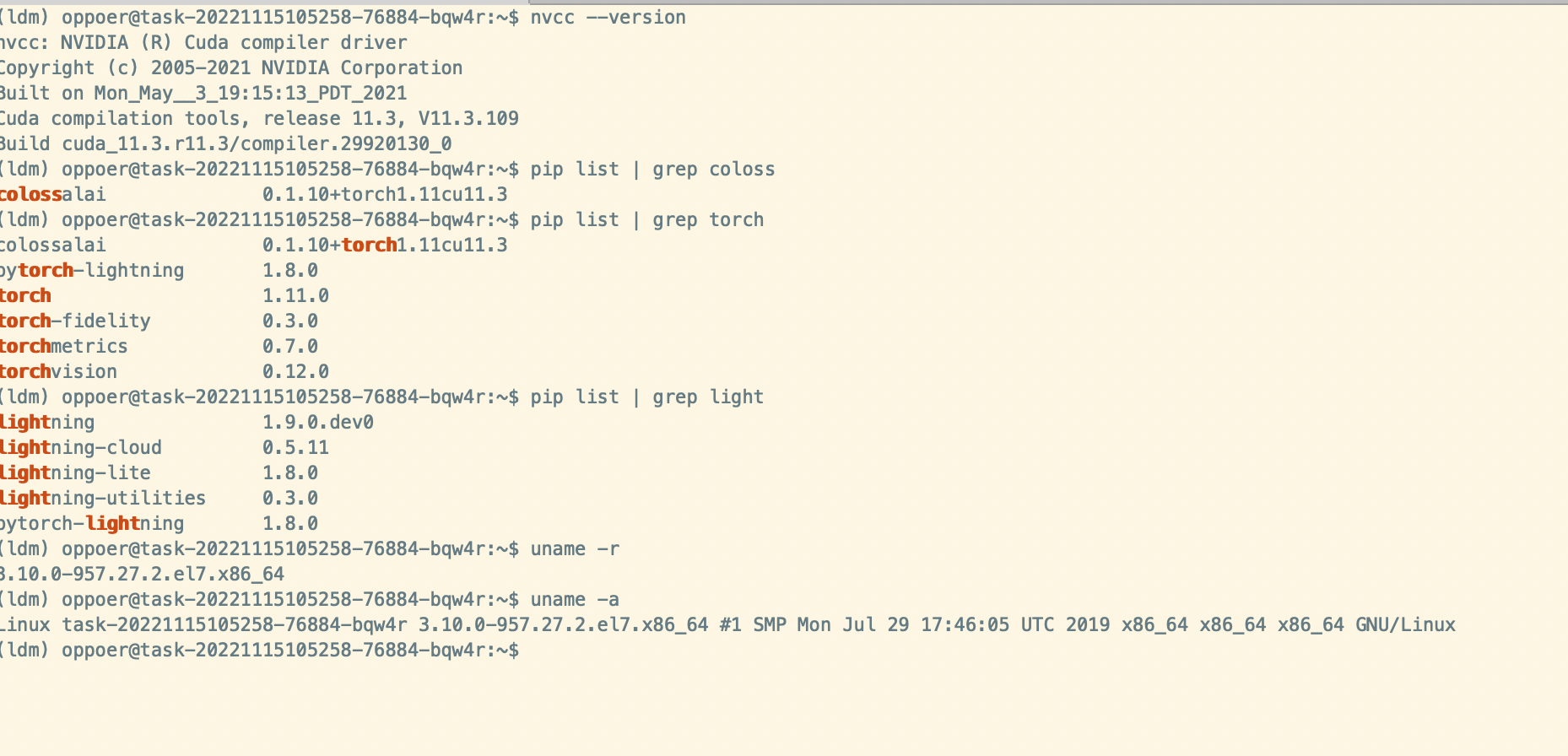
Environment
bug
![[BUG]: Memory consumption by fp16 is not normal](https://avatars.githubusercontent.com/u/24365567?v=4)
![[BUG]: RuntimeError of](https://avatars.githubusercontent.com/u/27288110?v=4)
![[BUG]: type object 'ChunkManager' has no attribute 'search_chunk_size'](https://avatars.githubusercontent.com/u/67773022?v=4)
![[BUG]: colossalai/kernel/cuda_native/csrc/moe_cuda_kernel.cu:5:10: fatal error: cub/cub.cuh: No such file or directory (update: now with more build errors!)](https://avatars.githubusercontent.com/u/7685285?v=4)
![[BUG]: Issue with Colossal-AI on Cuda 11.4 and Docker ?](https://avatars.githubusercontent.com/u/63513596?v=4)
![[BUG]: examples/images/diffusion ran failed](https://avatars.githubusercontent.com/u/24288375?v=4)

![[BUG]: RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one.](https://avatars.githubusercontent.com/u/69774354?v=4)
![[BUG]: CUDA extension build skipped when installing from source](https://avatars.githubusercontent.com/u/50511903?v=4)

![[example] simplify opt example](https://avatars.githubusercontent.com/u/5706969?v=4)
![[DOC]: examples中transformers版本错误](https://avatars.githubusercontent.com/u/22529082?v=4)
![[device] find best logical mesh](https://avatars.githubusercontent.com/u/72588413?v=4)

 48 Dec 30, 2022
48 Dec 30, 2022
 45 Jan 1, 2023
45 Jan 1, 2023
 185 Dec 21, 2022
185 Dec 21, 2022
 607 Dec 31, 2022
607 Dec 31, 2022
 72 Dec 16, 2022
72 Dec 16, 2022
 130 Dec 2, 2022
130 Dec 2, 2022
 432 Dec 16, 2022
432 Dec 16, 2022
 33 Jun 27, 2021
33 Jun 27, 2021
 36 Oct 30, 2022
36 Oct 30, 2022
 137 Dec 15, 2022
137 Dec 15, 2022
 128 Nov 29, 2022
128 Nov 29, 2022
 43 Dec 26, 2022
43 Dec 26, 2022
 290 Dec 29, 2022
290 Dec 29, 2022
 294 Dec 12, 2022
294 Dec 12, 2022
 37 Dec 8, 2022
37 Dec 8, 2022