Cross-modal Retrieval using Transformer Encoder Reasoning Networks
This project reimplements the idea from "Transformer Reasoning Network for Image-Text Matching and Retrieval". To solve the task of cross-modal retrieval, representative features from both modal are extracted using distinctive pipeline and then projected into the same embedding space. Because the features are sequence of vectors, Transformer-based model can be utilised to work best. In this repo, my highlight contribution is:
- Reimplement TERN module, which exploits the effectiveness of using Transformer on bottom-up attention features and bert features.
- Take advantage of facebookresearch's FAISS for efficient similarity search and clustering of dense vectors.
- Experiment various metric learning loss objectives from KevinMusgrave's Pytorch Metric Learning
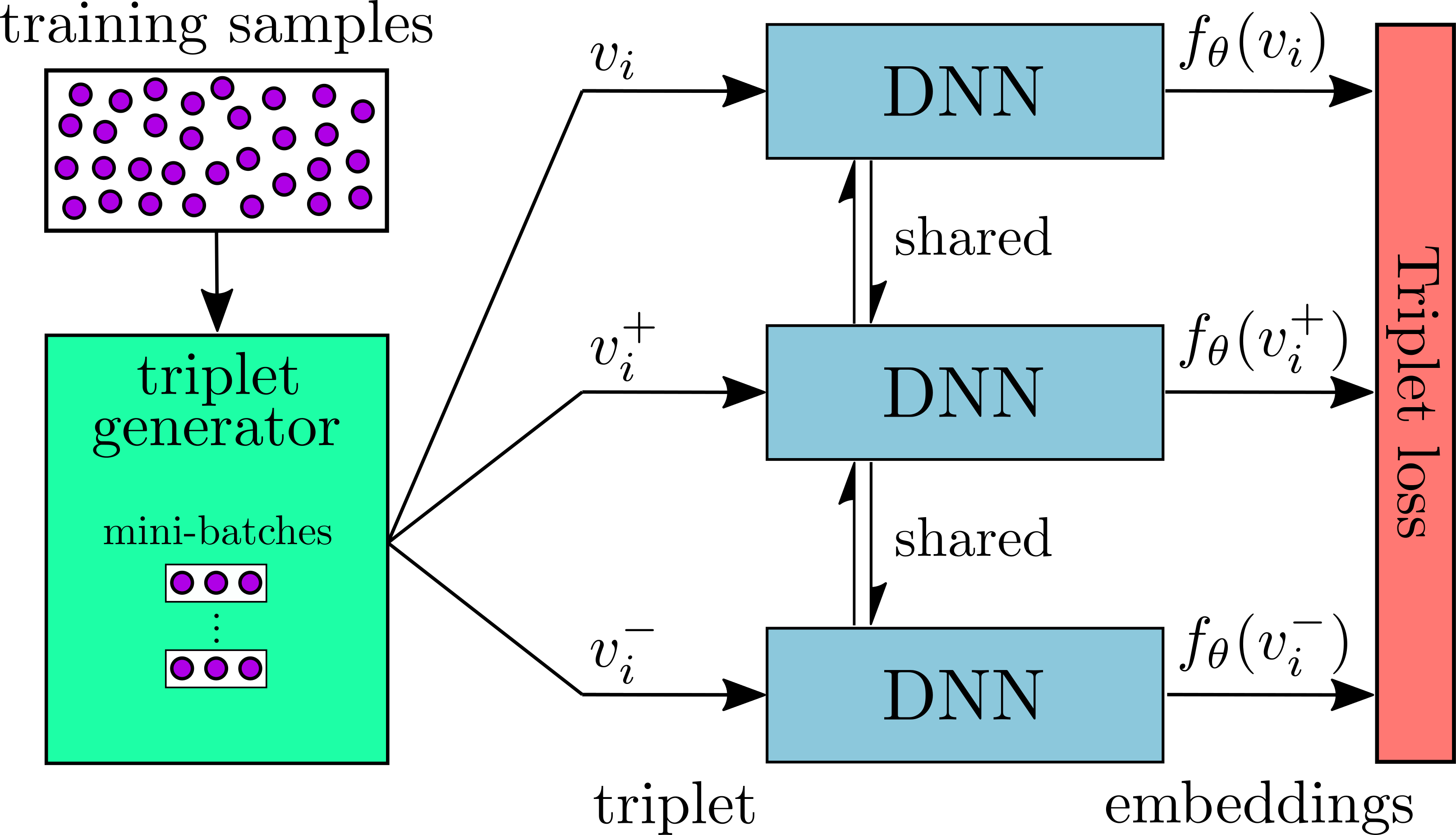
The figure below shows the overview of the architecture

Datasets
-
I trained TERN on Flickr30k dataset which contains 31,000 images collected from Flickr, together with 5 reference sentences provided by human annotators for each image. For each sample, visual and text features are pre-extracted as numpy files
-
Some samples from the dataset:
| Images | Captions |
|---|---|
 |
1. An elderly man is setting the table in front of an open door that leads outside to a garden. 2. The guy in the black sweater is looking onto the table below. 3. A man in a black jacket picking something up from a table. 4. An old man wearing a black jacket is looking on the table. 5. The gray-haired man is wearing a sweater. |
 |
1. Two men are working on a bicycle on the side of the road. 2. Three men working on a bicycle on a cobblestone street. 3. Two men wearing shorts are working on a blue bike. 4. Three men inspecting a bicycle on a street. 5. Three men examining a bicycle. |
Execution
- Installation
pip install -r requirements.txt
apt install libomp-dev
pip install faiss-gpu
-
Specify dataset paths and configuration in the config file
-
For training
PYTHONPATH=. python tools/train.py
- For evaluation
PYTHONPATH=. python tools/eval.py \
--top_k= <top k similarity> \
--weight= <model checkpoint> \
- For inference
- See tools/inference.py script
Notebooks
Inference TERN on Flickr30k dataset
Results
- Validation m on Flickr30k dataset (trained for 100 epochs):
| Model | Weights | i2t/R@10 | t2i/R@10 |
|---|---|---|---|
| TERN | link | 0.5174 | 0.7496 |
- Some visualization
| Query text: Two dogs are running along the street |
|---|
 |
| Query text: The woman is holding a violin |
|---|
 |
| Query text: Young boys are playing baseball |
|---|
 |
| Query text: A man is standing, looking at a lake |
|---|
 |
Paper References
@misc{messina2021transformer,
title={Transformer Reasoning Network for Image-Text Matching and Retrieval},
author={Nicola Messina and Fabrizio Falchi and Andrea Esuli and Giuseppe Amato},
year={2021},
eprint={2004.09144},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{anderson2018bottomup,
title={Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering},
author={Peter Anderson and Xiaodong He and Chris Buehler and Damien Teney and Mark Johnson and Stephen Gould and Lei Zhang},
year={2018},
eprint={1707.07998},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{JDH17,
title={Billion-scale similarity search with GPUs},
author={Johnson, Jeff and Douze, Matthijs and J{\'e}gou, Herv{\'e}},
journal={arXiv preprint arXiv:1702.08734},
year={2017}
}

 170 Dec 30, 2022
170 Dec 30, 2022
![The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]](https://github.com/Paranioar/SGRAF/raw/main/fig/model.png)
 149 Dec 22, 2022
149 Dec 22, 2022
 2 Jan 24, 2022
2 Jan 24, 2022
 104 Nov 12, 2022
104 Nov 12, 2022

 203 Nov 30, 2022
203 Nov 30, 2022

 12.6k Jan 9, 2023
12.6k Jan 9, 2023

 225 Dec 25, 2022
225 Dec 25, 2022

 37 Dec 8, 2022
37 Dec 8, 2022

 24 Mar 2, 2022
24 Mar 2, 2022

 42 Nov 17, 2022
42 Nov 17, 2022
 489 Jan 7, 2023
489 Jan 7, 2023
 9 Jan 12, 2022
9 Jan 12, 2022
 514 Dec 28, 2022
514 Dec 28, 2022
 39 Jul 21, 2022
39 Jul 21, 2022
 32 Dec 15, 2022
32 Dec 15, 2022
 28 Dec 30, 2022
28 Dec 30, 2022
 912 Jan 8, 2023
912 Jan 8, 2023
 146 Dec 28, 2022
146 Dec 28, 2022
 16 Dec 14, 2022
16 Dec 14, 2022