labml.ai Deep Learning Paper Implementations
This is a collection of simple PyTorch implementations of neural networks and related algorithms. These implementations are documented with explanations,
The website renders these as side-by-side formatted notes. We believe these would help you understand these algorithms better.
We are actively maintaining this repo and adding new implementations almost weekly. 
Modules
✨
Transformers
- Multi-headed attention
- Transformer building blocks
- Transformer XL
- Compressive Transformer
- GPT Architecture
- GLU Variants
- kNN-LM: Generalization through Memorization
- Feedback Transformer
- Switch Transformer
- Fast Weights Transformer
- FNet
- Attention Free Transformer
- Masked Language Model
- MLP-Mixer: An all-MLP Architecture for Vision
- Pay Attention to MLPs (gMLP)
- Vision Transformer (ViT)
- Primer EZ
✨
Recurrent Highway Networks
✨
LSTM
✨
HyperNetworks - HyperLSTM
✨
ResNet
✨
ConvMixer
✨
Capsule Networks
✨
Generative Adversarial Networks
- Original GAN
- GAN with deep convolutional network
- Cycle GAN
- Wasserstein GAN
- Wasserstein GAN with Gradient Penalty
- StyleGAN 2
✨
Diffusion models
✨
Sketch RNN
✨
Graph Neural Networks
✨
Counterfactual Regret Minimization (CFR)
Solving games with incomplete information such as poker with CFR.
✨
Reinforcement Learning
- Proximal Policy Optimization with Generalized Advantage Estimation
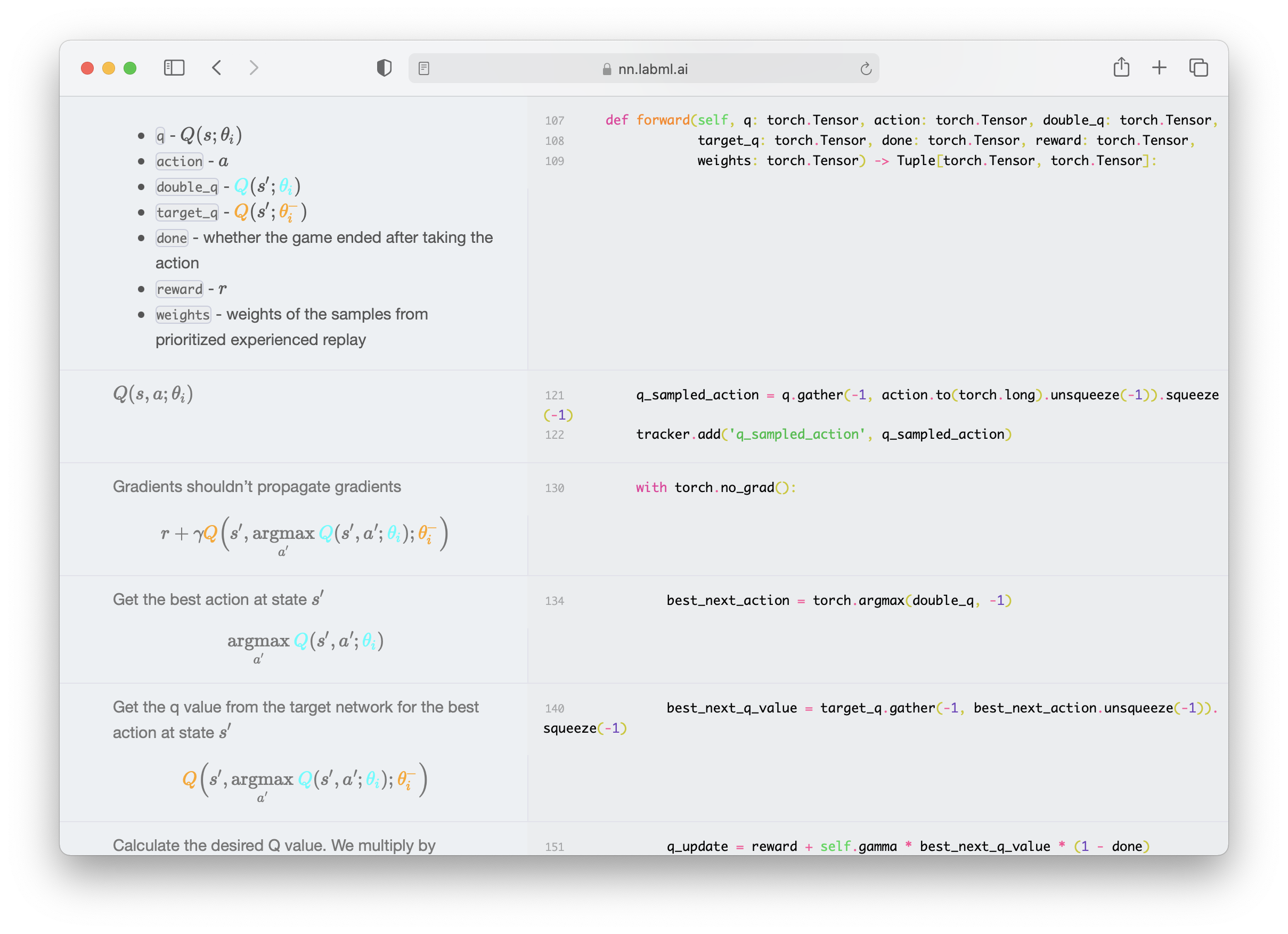
- Deep Q Networks with with Dueling Network, Prioritized Replay and Double Q Network.
✨
Optimizers
✨
Normalization Layers
- Batch Normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
- Weight Standardization
- Batch-Channel Normalization
✨
Distillation
✨
Adaptive Computation
✨
Uncertainty
Installation
pip install labml-nn
Citing
If you use this for academic research, please cite it using the following BibTeX entry.
@misc{labml,
author = {Varuna Jayasiri, Nipun Wijerathne},
title = {labml.ai Annotated Paper Implementations},
year = {2020},
url = {https://nn.labml.ai/},
}
Other Projects
🚀
Trending Research Papers
This shows the most popular research papers on social media. It also aggregates links to useful resources like paper explanations videos and discussions.
🧪
labml.ai/labml
This is a library that let's you monitor deep learning model training and hardware usage from your mobile phone. It also comes with a bunch of other tools to help write deep learning code efficiently.
















![[BUG] StyleGAN2: latent vector is ignored](https://avatars.githubusercontent.com/u/1911342?v=4)




 2.2k Jan 3, 2023
2.2k Jan 3, 2023
 892 Dec 28, 2022
892 Dec 28, 2022
 9 Nov 29, 2022
9 Nov 29, 2022
 98 Nov 16, 2022
98 Nov 16, 2022
 322 Dec 17, 2022
322 Dec 17, 2022
 183 Dec 15, 2022
183 Dec 15, 2022
 32 Dec 15, 2022
32 Dec 15, 2022
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
 4.7k Jan 4, 2023
4.7k Jan 4, 2023
 183 Dec 28, 2022
183 Dec 28, 2022
 4 Dec 31, 2022
4 Dec 31, 2022
 270 Dec 31, 2022
270 Dec 31, 2022
 33 Dec 2, 2022
33 Dec 2, 2022
 4.7k Jan 1, 2023
4.7k Jan 1, 2023
 546 Dec 5, 2022
546 Dec 5, 2022
 80 Dec 30, 2022
80 Dec 30, 2022
 27 Dec 1, 2022
27 Dec 1, 2022
 37 Dec 24, 2022
37 Dec 24, 2022
 0 Nov 13, 2021
0 Nov 13, 2021