TAPEX: Table Pre-training via Learning a Neural SQL Executor
The official repository which contains the code and pre-trained models for our paper TAPEX: Table Pre-training via Learning a Neural SQL Executor.
🔥
Updates
- 2021-08-28: We released the fine-tuned model weights on SQA and WikiTableQuestions!
- 2021-08-27: We released the code, the pre-training corpus, and the pre-trained TAPEX model weights. Thanks for your patience!
- 2021-07-16: We released our paper and home page. Check it out!
🏴
Overview
Paper
In the paper, we present TAPEX (for Table Pre-training via Execution), a conceptually simple and empirically powerful pre-training approach to empower existing generative pre-trained models (e.g., BART in our paper) with table reasoning skills. TAPEX realizes table pre-training by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries.
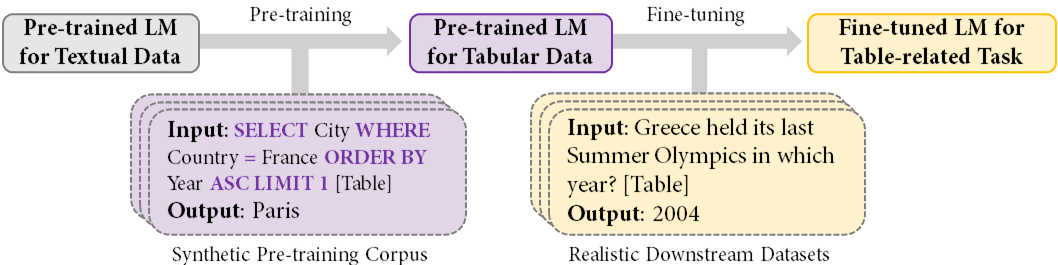
The central point of TAPEX is to train a model to mimic the SQL query execution process over a table. We believe that if a model can be trained to faithfully execute SQL queries, then it must have a deep understanding of table structures and possess an inductive bias towards table structures.

Meanwhile, since the diversity of SQL queries can be guaranteed systemically, and thus a diverse and high-quality pre-training corpus can be automatically synthesized for TAPEX.
Project
This project contains two parts, tapex library and examples to employ it on different table-related applications (e.g., Table Question Answering).
- For
tapex, there is an overview:
|-- common
|-- dbengine.py # the database engine to return answer for a SQL query
|-- download.py # download helper for automatic resource
|-- data_utils
|-- wikisql
|-- executor.py # the re-implementation of WikiSQL style SQL execution to obtain ground-truth answers in the dataset
|-- format_converter.py # convert dataset formats into HuggingFace style
|-- preprocess_binary.py # wrapper for the fairseq preprocess script
|-- preprocess_bpe.py # wrapper for the BPE preprocess
|-- processor
|-- table_linearize.py # the class to flatten a table into a linearized form, which should keep consistent during pre-training, fine-tuning and evaluating
|-- table_truncate.py # the class to truncate a long table into a shorter version to satisfy model's input length limit (e.g., BART can accept at most 1024 tokens)
|-- table_processor.py # the wrapper for the above two table utility function classes
|-- model_eval.py # evaluate the denotation accuracy of model
|-- model_interface.py # wrap a model interface for interaction based on HubInterface
- For
examples, please refer to here for more details.
⚡️
Quickstart
Prepare Environment
First, you should set up a python environment. This code base has been tested under python 3.x, and we officially support python 3.8.
After installing python 3.8, we strongly recommend you to use virtualenv (a tool to create isolated Python environments) to manage the python environment. You could use following commands to create an environment venv and activate it.
$ python3.8 -m venv venv
$ source venv/bin/activate
Install TAPEX
The main requirements of our code base is fairseq, which may be difficult for beginners to get started in an hour.
However, do not worry, we already wrap all necessary commands for developers. In other words, you do not need to study fairseq to start your journey about TAPEX! You can simply run the following command (in the virtual environment) to use TAPEX:
$ pip install --editable ./
The argument
--editableis important for your potential follow-up modification on the tapex library. The command will not only install dependencies, but also installtapexas a library, which can be imported easily.
Use TAPEX
Once tapex is successfully installed, you could go into examples to enjoy fine-tuning TAPEX models and using them on different applications!
🏰
Resource
Pre-training Corpus
Our synthetic pre-training corpus which includes nearly 5,000,000 tuples of (SQL queries, flattened tables, SQL execution results) can be downloaded from here. You can use it for research purpose, but you should be careful about the data license.
Below is an example from the pre-training corpus:
- The SQL plus flattened Table as INPUT:
select ( select number where number = 4 ) - ( select number where number = 3 ) col : number | date | name | age (at execution) | age (at offense) | race | state | method row 1 : 1 | november 2, 1984 | velma margie barfield | 52 | 45 | white | north carolina | lethal injection row 2 : 2 | february 3, 1998 | karla faye tucker | 38 | 23 | white | texas | lethal injection row 3 : 3 | march 30, 1998 | judias v. buenoano | 54 | 28 | white | florida | electrocution row 4 : 4 | february 24, 2000 | betty lou beets | 62 | 46 | white | texas | lethal injection row 5 : 5 | may 2, 2000 | christina marie riggs | 28 | 26 | white | arkansas | lethal injection row 6 : 6 | january 11, 2001 | wanda jean allen | 41 | 29 | black | oklahoma | lethal injection row 7 : 7 | may 1, 2001 | marilyn kay plantz | 40 | 27 | white | oklahoma | lethal injection row 8 : 8 | december 4, 2001 | lois nadean smith | 61 | 41 | white | oklahoma | lethal injection row 9 : 9 | may 10, 2002 | lynda lyon block | 54 | 45 | white | alabama | electrocution row 10 : 10 | october 9, 2002 | aileen carol wuornos | 46 | 33 | white | florida | lethal injection row 11 : 11 | september 14, 2005 | frances elaine newton | 40 | 21 | black | texas | lethal injection row 12 : 12 | september 23, 2010 | teresa wilson bean lewis | 41 | 33 | white | virginia | lethal injection row 13 : 13 | june 26, 2013 | kimberly lagayle mccarthy | 52 | 36 | black | texas | lethal injection row 14 : 14 | february 5, 2014 | suzanne margaret basso | 59 | 44 | white | texas | lethal injection
- The SQL Execution Result as OUTPUT:
1.0
Here we want to acknowledge the huge effort of paper On the Potential of Lexico-logical Alignments for Semantic Parsing to SQL Queries, which provides the rich resources of SQL templates for us to synthesize the pre-training corpus. If you are interested, please give a STAR to their repo.
Pre-trained models
The pre-trained models trained on the above pre-training corpus.
| Model | Description | # Params | Download |
|---|---|---|---|
tapex.base |
6 encoder and decoder layers | 140M | tapex.base.tar.gz |
tapex.large |
12 encoder and decoder layers | 400M | tapex.large.tar.gz |
Fine-tuned Models
We provide fine-tuned model weights and their performance on different datasets below. The following Accuracy (Acc) refers to denotation accuracy computed by our script model_eval.py. Meanwhile, it is worth noting that we need truncating long tables during preprocessing with some randomness. Therefore, we also provide preprocessed datasets for reproducing our experimental results.
| Model | Dev Acc | Test Acc | Dataset | Download Data | Download Model |
|---|---|---|---|---|---|
tapex.large.wtq |
58.0 | 57.2 | WikiTableQuestions | wtq.preprocessed.zip | tapex.large.wtq.tar.gz |
tapex.large.sqa |
70.7 | 74.0 | SQA | sqa.preprocessed.zip | tapex.large.sqa.tar.gz |
tapex.large.wikisql |
89.3 | 89.2 | WikiSQL | wikisql.preprocessed.zip | tapex.large.wikisql.tar.gz |
Given these fine-tuned model weights, you can play with them using the predict mode in examples/tableqa/run_model.py.
For example, you can use the following command and see its log:
$ python examples/tableqa/run_model.py predict --resource-dir ./tapex.large.wtq --checkpoint-name model.pt
2021-08-29 17:39:47 | INFO | __main__ | Receive question as : Greece held its last Summer Olympics in which year?
2021-08-29 17:39:47 | INFO | __main__ | The answer should be : 2004
💬
Citation
If our work is useful for you, please consider citing our paper:
@misc{liu2021tapex,
title={TAPEX: Table Pre-training via Learning a Neural SQL Executor},
author={Qian Liu and Bei Chen and Jiaqi Guo and Zeqi Lin and Jian-guang Lou},
year={2021},
eprint={2107.07653},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
👍
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
📝
License
Please note that there are TWO LICENSES for code and pre-training corpus. The code and pre-trained models are open-sourced under MIT License, while the pre-training corpus is released under CC BY-SA 4.0.
™️
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.












 5 Mar 30, 2022
5 Mar 30, 2022
 2.2k Jan 8, 2023
2.2k Jan 8, 2023
 284 Dec 21, 2022
284 Dec 21, 2022
 74 Dec 3, 2022
74 Dec 3, 2022
 282 Jan 9, 2023
282 Jan 9, 2023
 63 Oct 17, 2022
63 Oct 17, 2022
 178 Jan 5, 2023
178 Jan 5, 2023
 22 Feb 27, 2022
22 Feb 27, 2022
 1 Dec 13, 2021
1 Dec 13, 2021
 55 Nov 23, 2022
55 Nov 23, 2022
 196 Dec 13, 2022
196 Dec 13, 2022
 21 Dec 13, 2022
21 Dec 13, 2022
 892 Dec 28, 2022
892 Dec 28, 2022
 63 Nov 23, 2022
63 Nov 23, 2022
 75 Nov 2, 2022
75 Nov 2, 2022
 26 Oct 25, 2022
26 Oct 25, 2022
 1 Jan 18, 2022
1 Jan 18, 2022
 430 Dec 23, 2022
430 Dec 23, 2022