Customer Segmentation with RFM Scores and K-means
RFM Segmentation table:
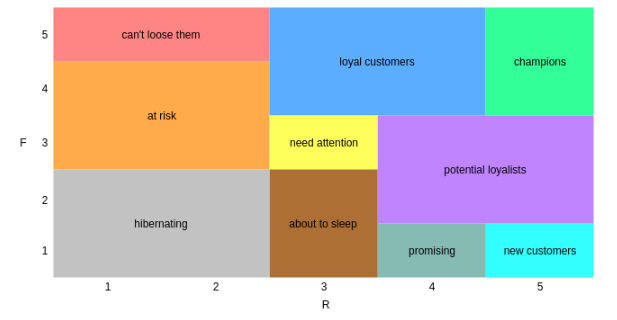
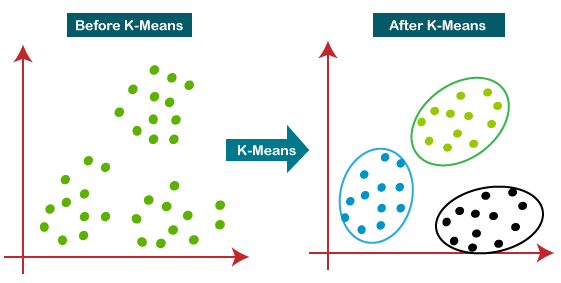
K-Means Clustering:
Business Problem
Rule-based customer segmentation machine learning method with RFM for customer segmentation of K-Means comparison is expected.
History of Dataset
The dataset named Online Retail II contains a UK-based online sale store's sales between 01/12/2009 - 09/12/2011. We used data from 01/12/2010 - 09/12/2011 years at this project. Because we wanted to use recent data. The product catalog of this company includes souvenirs. The vast majority of the company's customers are corporate customers.
Variables
InvoiceNo – Invoice Number, If this code starts with C, it indicates that the transaction has been cancelled.
StockCode – Product code, unique number for each product.
Description – Product name or derscription
Quantity – Product quantity
InvoiceDate –Invoice Date
UnitPrice – Unit price (Currency: GBP)
CustomerID – Customer ID number
Country – Country name
 203 Dec 26, 2022
203 Dec 26, 2022
 121 Dec 28, 2022
121 Dec 28, 2022
 124 Dec 28, 2022
124 Dec 28, 2022
 73 Oct 17, 2022
73 Oct 17, 2022

 164 Jan 4, 2023
164 Jan 4, 2023
 31 Nov 3, 2022
31 Nov 3, 2022
 14 Mar 30, 2022
14 Mar 30, 2022

 2 Dec 10, 2021
2 Dec 10, 2021
 2 Dec 14, 2021
2 Dec 14, 2021

 1 Nov 1, 2021
1 Nov 1, 2021
 1 Dec 13, 2021
1 Dec 13, 2021
 3 Feb 8, 2022
3 Feb 8, 2022
 1 Jan 30, 2022
1 Jan 30, 2022
 3k Jan 8, 2023
3k Jan 8, 2023
 23.6k Jan 3, 2023
23.6k Jan 3, 2023
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
 924 Jan 3, 2023
924 Jan 3, 2023