PoolFormer: MetaFormer is Actually What You Need for Vision (arXiv)
This is a PyTorch implementation of PoolFormer proposed by our paper "MetaFormer is Actually What You Need for Vision".
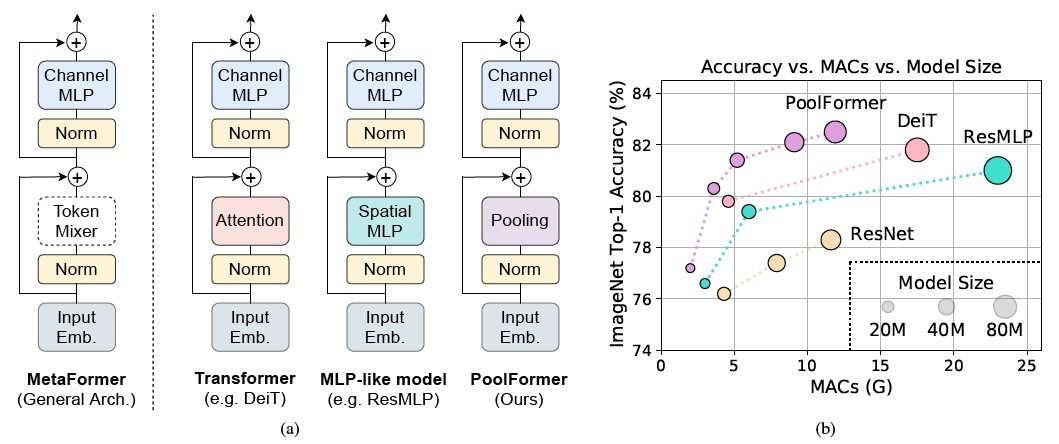
Figure 1: MetaFormer and performance of MetaFormer-based models on ImageNet-1K validation set. We argue that the competence of transformer/MLP-like models primarily stems from the general architecture MetaFormer instead of the equipped specific token mixers. To demonstrate this, we exploit an embarrassingly simple non-parametric operator, pooling, to conduct extremely basic token mixing. Surprisingly, the resulted model PoolFormer consistently outperforms the DeiT and ResMLP as shown in (b), which well supports that MetaFormer is actually what we need to achieve competitive performance.
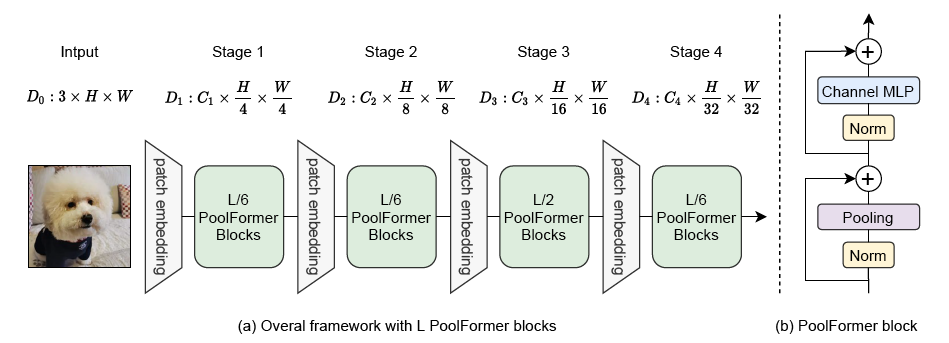 Figure 2: (a) The overall framework of PoolFormer. (b) The architecture of PoolFormer block. Compared with transformer block, it replaces attention with an extremely simple non-parametric operator, pooling, to conduct only basic token mixing.
Figure 2: (a) The overall framework of PoolFormer. (b) The architecture of PoolFormer block. Compared with transformer block, it replaces attention with an extremely simple non-parametric operator, pooling, to conduct only basic token mixing.
Bibtex
@article{yu2021metaformer,
title={MetaFormer is Actually What You Need for Vision},
author={Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng},
journal={arXiv preprint arXiv:2111.11418},
year={2021}
}
1. Requirements
For Image Classification (Configs of detection and segmentation will be available soon)
torch>=1.7.0; torchvision>=0.8.0; pyyaml; apex-amp (if you want to use fp16); timm (pip install git+https://github.com/rwightman/pytorch-image-models.git@9d6aad44f8fd32e89e5cca503efe3ada5071cc2a)
data prepare: ImageNet with the following folder structure, you can extract ImageNet by this script.
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
Directory structure in this repo:
│poolformer/
├──misc/
├──models/
│ ├── __init__.py
│ ├── poolformer.py
├──LICENSE
├──README.md
├──distributed_train.sh
├──train.py
├──validate.py
2. PoolFormer Models
| Model | #params | Image resolution | Top1 Acc | Download |
|---|---|---|---|---|
| poolformer_s12 | 12M | 224 | 77.2 | here |
| poolformer_s24 | 21M | 224 | 80.3 | here |
| poolformer_s36 | 31M | 224 | 81.4 | here |
| poolformer_m36 | 56M | 224 | 82.1 | here |
| poolformer_m48 | 73M | 224 | 82.5 | here |
All the pretrained models can also be downloaded by BaiDu Yun (password: esac).
Update ResNet Scores in the paper

[1] He et al., "Deep Residual Learning for Image Recognition", CVPR 2016.
[2] Wightman et al., "Resnet strikes back: An improved training procedure in timm", arXiv preprint arXiv:2110.00476. 2021 Oct 1.
Usage
We also provide a Colab notebook which run the steps to perform inference with poolformer.
3. Validation
To evaluate our PoolFormer models, run:
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
python3 validate.py /path/to/imagenet --model $MODEL \
--checkpoint /path/to/checkpoint -b 128
4. Train
We show how to train PoolFormers on 8 GPUs. The relation between learning rate and batch size is lr=bs/1024*1e-3. For convenience, assuming the batch size is 1024, then the learning rate is set as 1e-3 (for batch size of 1024, setting the learning rate as 2e-3 sometimes sees better performance).
MODEL=poolformer_s12 # poolformer_{s12, s24, s36, m36, m48}
DROP_PATH=0.1 # drop path rates [0.1, 0.1, 0.2, 0.3, 0.4] responding to model [s12, s24, s36, m36, m48]
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 ./distributed_train.sh 8 /path/to/imagenet \
--model $MODEL -b 128 --lr 1e-3 --drop-path $DROP_PATH --apex-amp
5. Acknowledgment
Our implementation is mainly based on the following codebases. We gratefully thank the authors for their wonderful works.
pytorch-image-models, mmdetection, mmsegmentation.
Besides, Weihao Yu would like to thank TPU Research Cloud (TRC) program for the support of partial computational resources.
LICENSE
This repo is under the Apache-2.0 license. For commercial use, please contact the authors.












 The official example :
#Image Example
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
#Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
#as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)
The official example :
#Image Example
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
#Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
#as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)






 1k Dec 31, 2022
1k Dec 31, 2022
 59 Sep 25, 2022
59 Sep 25, 2022
 79 Dec 28, 2022
79 Dec 28, 2022
 126 Dec 6, 2022
126 Dec 6, 2022
 139 Dec 28, 2022
139 Dec 28, 2022
 10 Jan 30, 2022
10 Jan 30, 2022
 7.1k Jan 4, 2023
7.1k Jan 4, 2023
 230 Dec 7, 2022
230 Dec 7, 2022
 16 Jul 16, 2022
16 Jul 16, 2022
 194 Jan 3, 2023
194 Jan 3, 2023
 12 Apr 28, 2022
12 Apr 28, 2022
 8 Oct 3, 2022
8 Oct 3, 2022
 195 Dec 30, 2022
195 Dec 30, 2022
 30 Dec 7, 2022
30 Dec 7, 2022
 4 Jan 5, 2022
4 Jan 5, 2022
 134 Dec 30, 2022
134 Dec 30, 2022
 209 Dec 30, 2022
209 Dec 30, 2022
 12.6k Jan 9, 2023
12.6k Jan 9, 2023