Barlow-Twins-TF
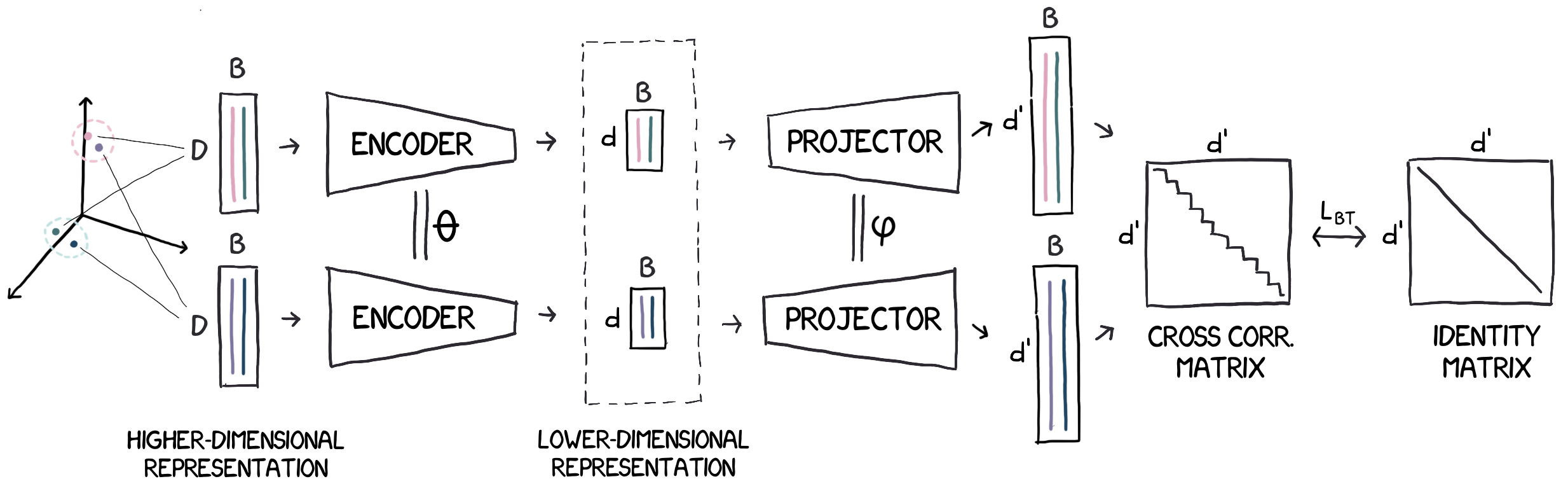
This repository implements Barlow Twins (Barlow Twins: Self-Supervised Learning via Redundancy Reduction) in TensorFlow and demonstrates it on the CIFAR10 dataset.
Summary:
With a ResNet20 as a trunk and a 3-layer MLP (each layer containing 2048 units) and 100 epochs of pre-training, this training notebook can give 62.61% accuracy on the CIFAR10 test set. The pre-training total takes ~23 minutes on a single Tesla V100. There are minor differences from the original implementation. However, the original loss function and the other minor details like having a big enough projection dimension have been maintained.
For details on Barlow Twins, I suggest reading the original paper, it's really well-written.
Loss progress during pre-training

Other notes
-
Pre-trained model is available here.
-
To follow the original implementation details as closely as possible, a WarmUpCosine learning rate schedule has been used during pre-training:
-
During linear evaluation, Cosine Decay has been used.

Acknowledgements
Thanks to Stéphane Deny (one of the authors of the paper) for helping me catch a pesky bug.
 19 Dec 12, 2022
19 Dec 12, 2022
 2 Oct 31, 2022
2 Oct 31, 2022

 482 Dec 18, 2022
482 Dec 18, 2022

 18 Dec 17, 2022
18 Dec 17, 2022

 459 Dec 27, 2022
459 Dec 27, 2022

 49 Dec 16, 2022
49 Dec 16, 2022
 72 Dec 12, 2022
72 Dec 12, 2022
 105 Dec 28, 2022
105 Dec 28, 2022
![A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]](https://user-images.githubusercontent.com/33194443/104581604-2592cb00-56a2-11eb-9610-5eaa0afb6e1f.png)
 2.4k Jan 5, 2023
2.4k Jan 5, 2023

 839 Dec 29, 2022
839 Dec 29, 2022
 49 Nov 24, 2022
49 Nov 24, 2022
 16 Nov 26, 2022
16 Nov 26, 2022
 92 Nov 30, 2022
92 Nov 30, 2022
 52 Nov 14, 2022
52 Nov 14, 2022
 370 Dec 27, 2022
370 Dec 27, 2022
 109 Dec 23, 2022
109 Dec 23, 2022
 152 Jan 7, 2023
152 Jan 7, 2023
 282 Jan 9, 2023
282 Jan 9, 2023