DeepBDC for few-shot learning
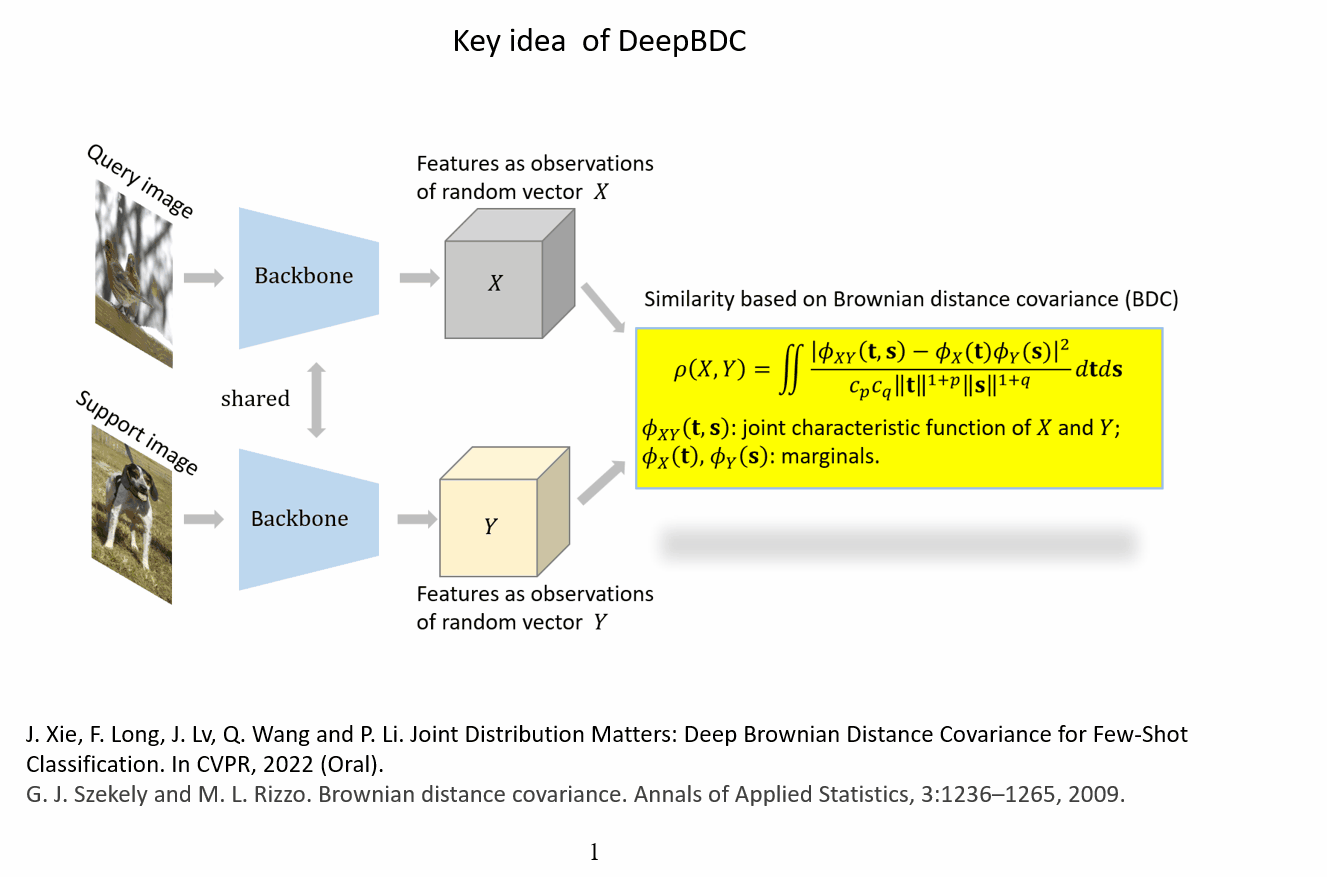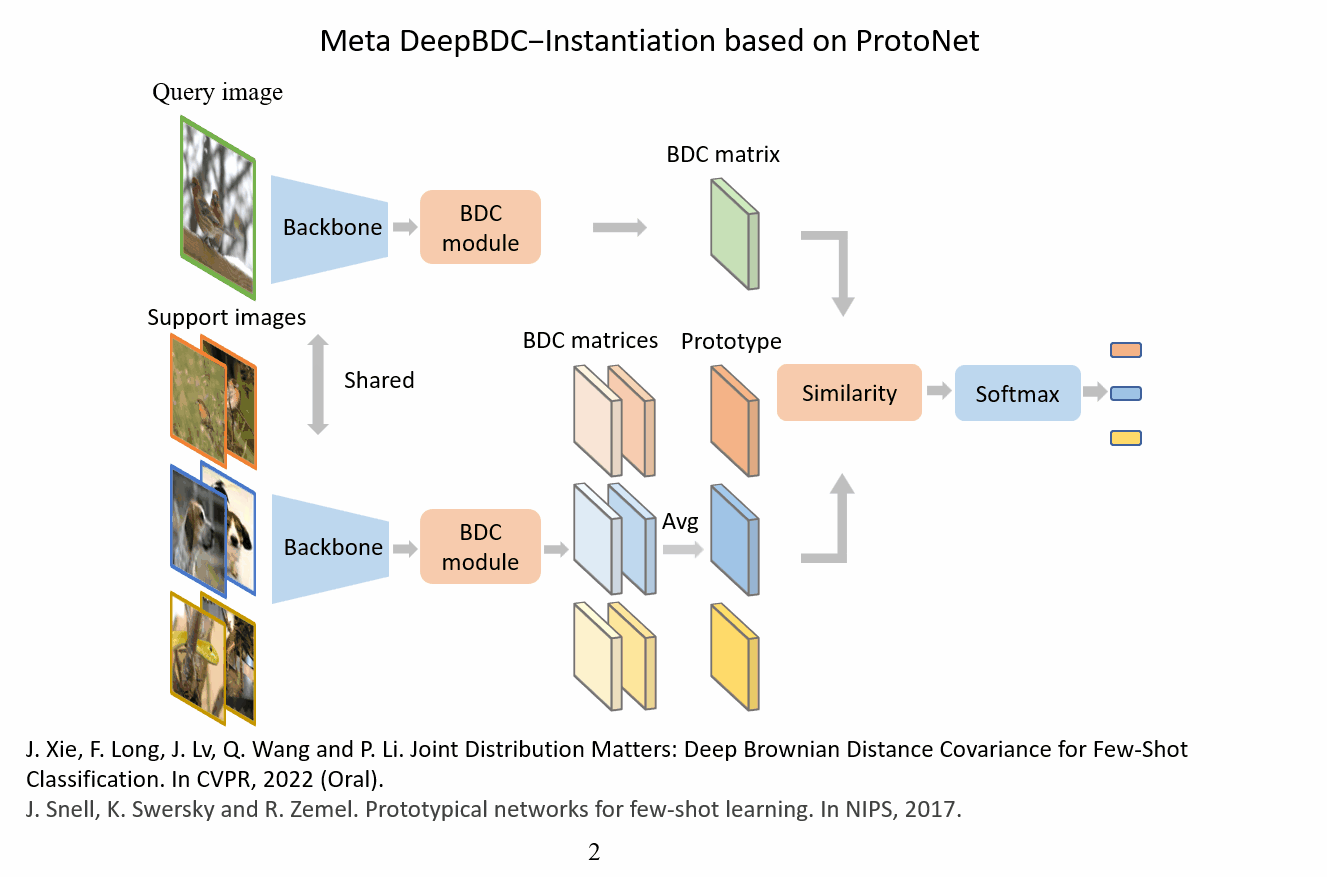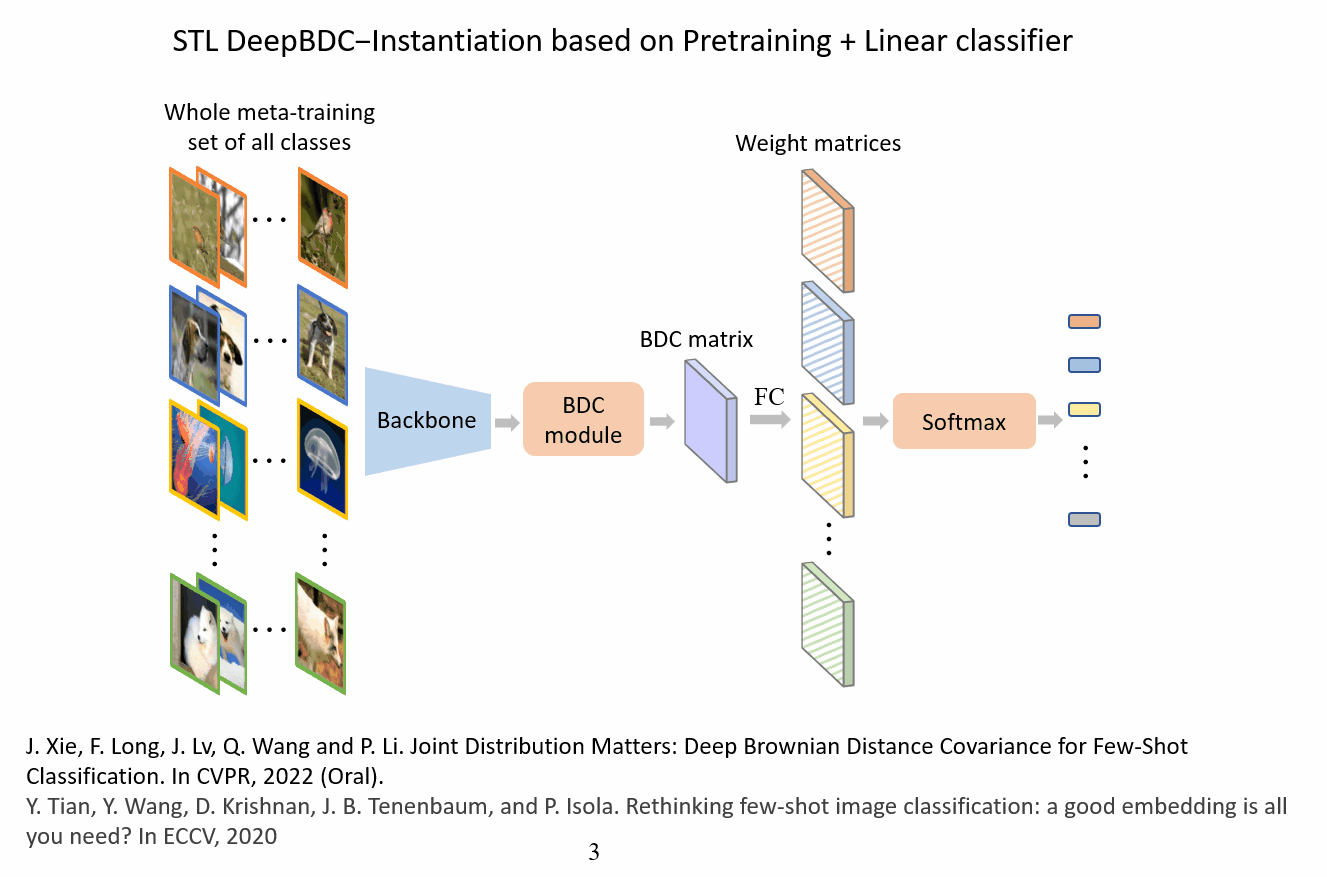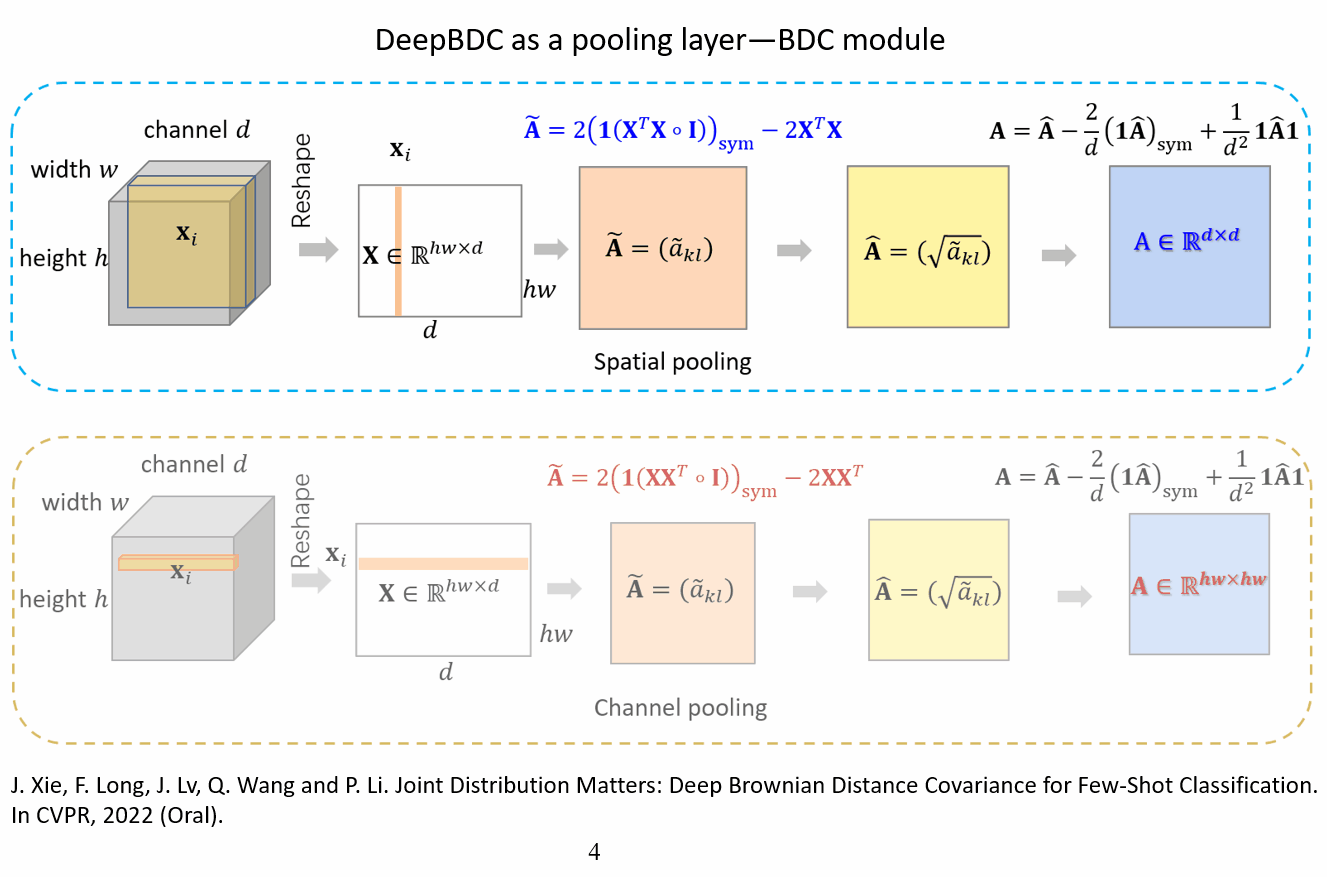
Introduction
In this repo, we provide the implementation of the following paper:
"Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification" [Project] [Paper].
In this paper, we propose deep Brownian Distance Covariance (DeepBDC) for few-shot classification. DeepBDC can effectively learn image representations by measuring, for the query and support images, the discrepancy between the joint distribution of their embedded features and product of the marginals. The core of DeepBDC is formulated as a modular and efficient layer, which can be flexibly inserted into deep networks, suitable not only for meta-learning framework based on episodic training, but also for the simple transfer learning (STL) framework of pretraining plus linear classifier.
If you find this repo helpful for your research, please consider citing our paper:
@inproceedings{DeepBDC-CVPR2022,
title={Joint Distribution Matters: Deep Brownian Distance Covariance for Few-Shot Classification},
author={Jiangtao Xie and Fei Long and Jiaming Lv and Qilong Wang and Peihua Li},
booktitle={CVPR},
year={2022}
}
Few-shot classification Results
Experimental results on miniImageNet and CUB. We report average results with 2,000 randomly sampled episodes for both 1-shot and 5-shot evaluation. More details on the experiments can be seen in the paper.
miniImageNet
| Method | ResNet-12 | Pre-trained models | Meta-trained models | |||
|---|---|---|---|---|---|---|
| 5-way-1-shot | 5-way-5-shot | GoogleDrive | BaiduCloud | GoogleDrive | BaiduCloud | |
| ProtoNet | 62.11±0.44 | 80.77±0.30 | Download | Download | Download | Download |
| Good-Embed | 64.98±0.44 | 82.10±0.30 | Download | Download | N/A | |
| Meta DeepBDC | 67.34±0.43 | 84.46±0.28 | Download | Download | Download | Download |
| STL DeepBDC | 67.83±0.43 | 85.45±0.29 | Download | Download | N/A | |
Note that for Good-Embed and STL DeepBDC, a sequential self-distillation technique is used to obtain the pre-trained models; See the paper of Good-Embed for details.
CUB
| Method | ResNet-18 | Pre-trained models | Meta-trained models | |||
|---|---|---|---|---|---|---|
| 5-way-1-shot | 5-way-5-shot | GoogleDrive | BaiduCloud | GoogleDrive | BaiduCloud | |
| ProtoNet | 80.90±0.43 | 89.81±0.23 | Download | Download | Download | Download |
| Good-Embed | 77.92±0.46 | 89.94±0.26 | Download | Download | N/A | |
| Meta DeepBDC | 83.55±0.40 | 93.82±0.17 | Download | Download | Download | Download |
| STL DeepBDC | 84.01±0.42 | 94.02±0.24 | Download | Download | N/A | |
Note that for Good-Embed and STL DeepBDC, a sequential self-distillation technique is used to obtain the pre-trained models; See the paper of Good-Embed for details.
References
[BDC] G. J. Szekely and M. L. Rizzo. Brownian distance covariance. Annals of Applied Statistics, 3:1236–1265, 2009.
[ProtoNet] Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. In NIPS, 2017.
[Good-Embed] Y. Tian, Y. Wang, D. Krishnan, J. B. Tenenbaum, and P. Isola. Rethinking few-shot image classification: a good embedding is all you need? In ECCV, 2020.
Implementation details
Datasets
- miniImageNet: We use the splits provided by Chen et al.
- CUB: We use the splits provided by Chen et al.
- tieredImageNet
- Aircraft
- Cars
Implementation environment
Note that the test accuracy may slightly vary with different Pytorch/CUDA versions, GPUs, etc.
- Linux
- Python 3.8.3
- torch 1.7.1
- GPU (RTX3090) + CUDA11.0 CuDNN
- sklearn1.0.1, pillow8.0.0, numpy1.19.2
Installation
- Clone this repo:
git clone https://github.com/Fei-Long121/DeepBDC.git
cd DeepBDC
For Meta DeepBDC on general object recognition
cd scripts/mini_magenet/run_meta_deepbdc- modify the dataset path in
run_pretrain.sh,run_metatrain.shandrun_test.sh bash run.sh
For STL DeepBDC on general object recognition
cd scripts/mini_imagenet/run_stl_deepbdc- modify the dataset path in
run_pretrain.sh,run_distillation.shandrun_test.sh bash run.sh
Acknowledgments
Our code builds upon the the following code publicly available:
Contact
If you have any questions or suggestions, please contact us:
Fei Long([email protected])
Jiaming Lv([email protected])










 1.4k Jan 1, 2023
1.4k Jan 1, 2023
 365 Dec 30, 2022
365 Dec 30, 2022
 36 Nov 23, 2022
36 Nov 23, 2022
 138 Dec 28, 2022
138 Dec 28, 2022
 108 Dec 27, 2022
108 Dec 27, 2022
 249 Dec 28, 2022
249 Dec 28, 2022
 264 Dec 23, 2022
264 Dec 23, 2022
 842 Jan 4, 2023
842 Jan 4, 2023
 96 Jan 3, 2023
96 Jan 3, 2023
 102 Dec 25, 2022
102 Dec 25, 2022
 259 Dec 25, 2022
259 Dec 25, 2022
 256 Dec 28, 2022
256 Dec 28, 2022
 309 Dec 30, 2022
309 Dec 30, 2022
 235 Jan 3, 2023
235 Jan 3, 2023
 203 Dec 31, 2022
203 Dec 31, 2022
 280 Jan 7, 2023
280 Jan 7, 2023
 3 Aug 20, 2022
3 Aug 20, 2022
 37 Nov 27, 2022
37 Nov 27, 2022
 83 May 11, 2022
83 May 11, 2022