It Leaves A Trail
This repository contains a python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
Screenshots


All implementations are based on what I've learned from Digital Image Processing, 3rd edition Book by Rafael C. GONZALES and Richard E. Woods

 243 Dec 30, 2022
243 Dec 30, 2022
 88 Jun 2, 2022
88 Jun 2, 2022

 3.3k Dec 31, 2022
3.3k Dec 31, 2022
 8 Jul 29, 2022
8 Jul 29, 2022
 648 Dec 30, 2022
648 Dec 30, 2022
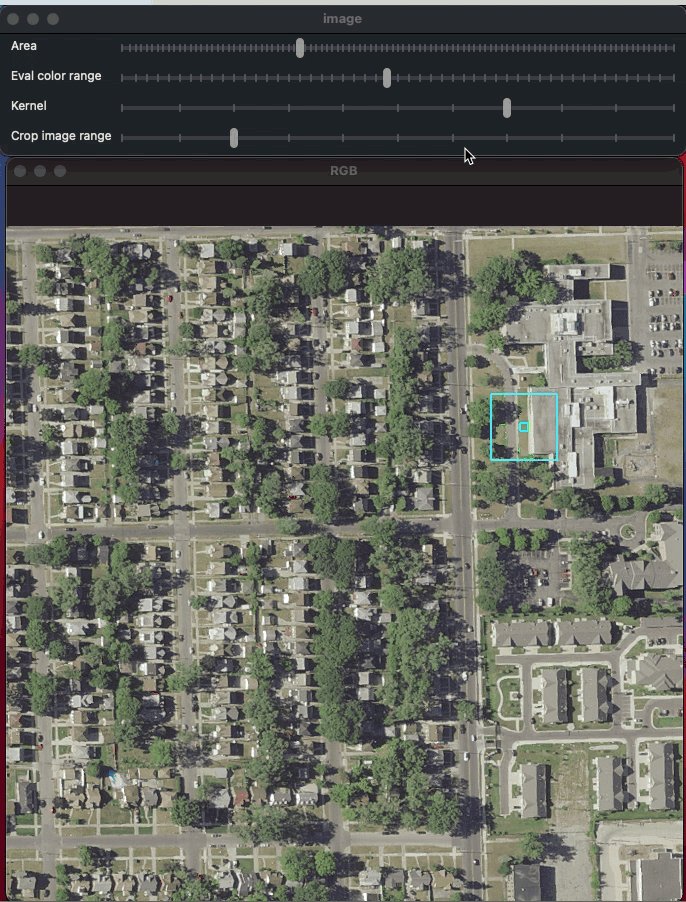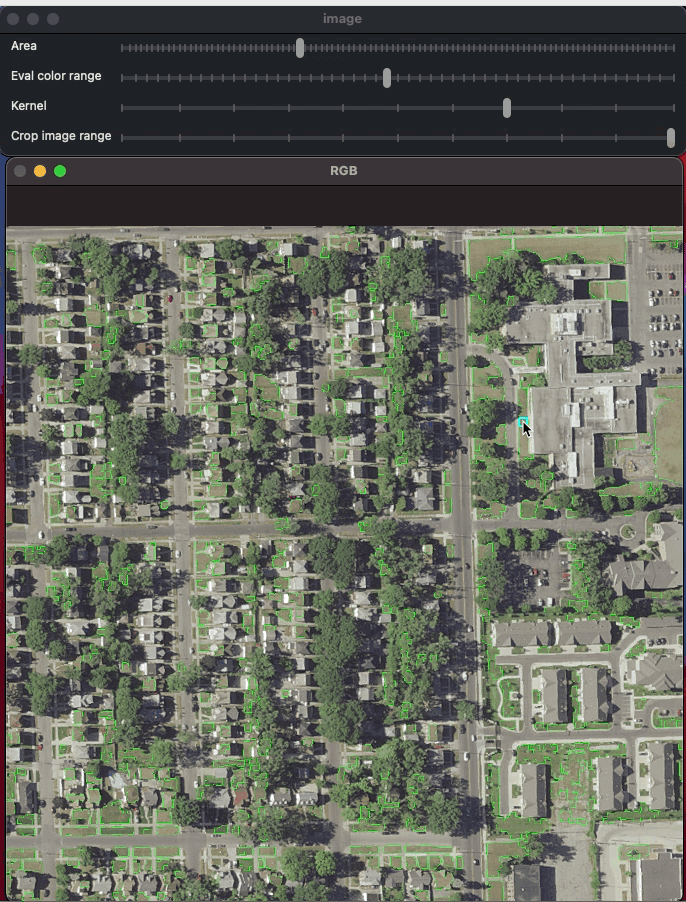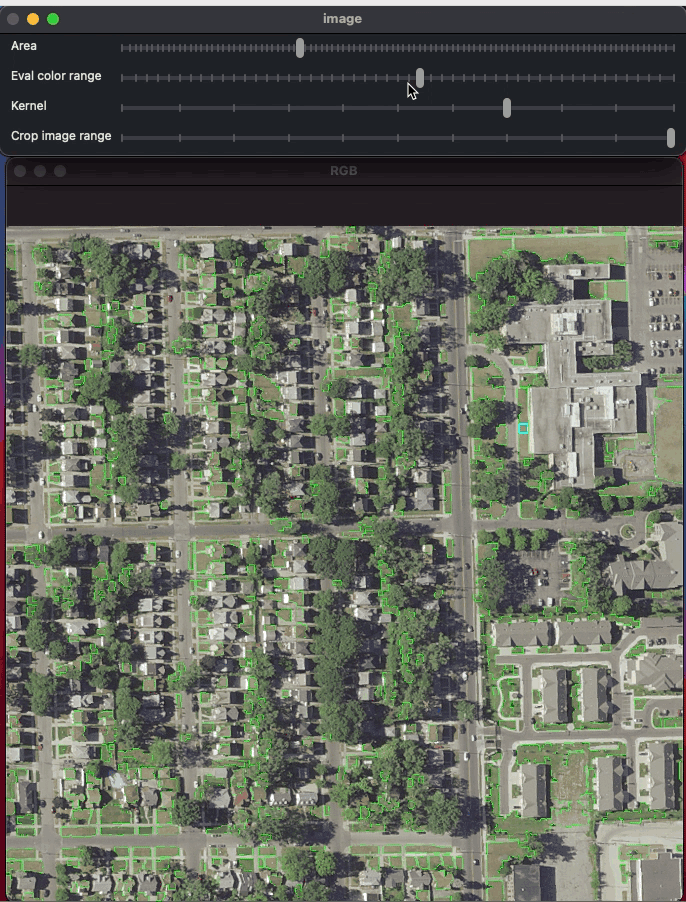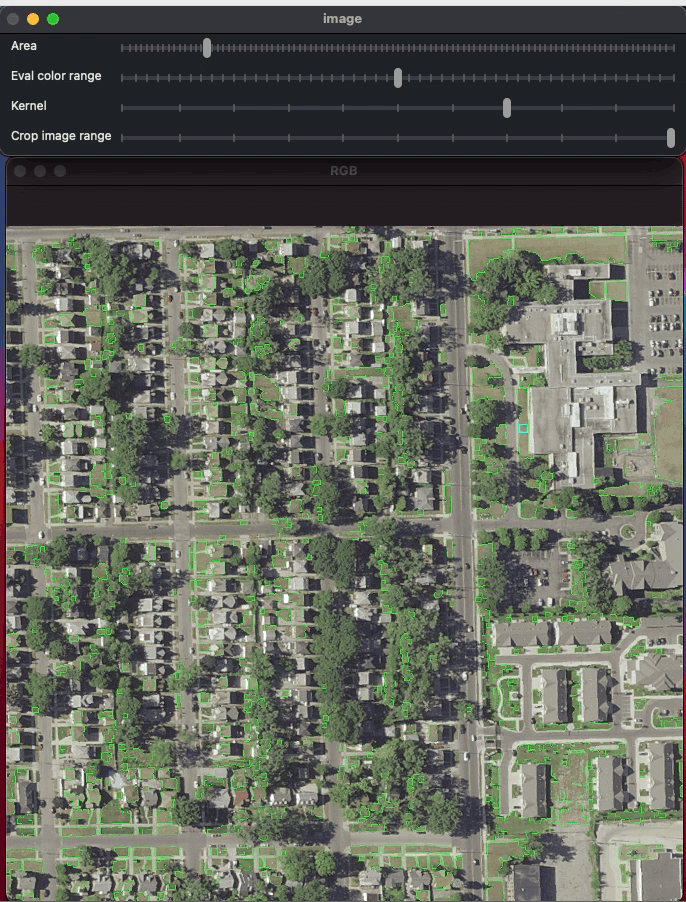
 9 Jul 27, 2022
9 Jul 27, 2022
 111 Nov 27, 2022
111 Nov 27, 2022

 671 Dec 27, 2022
671 Dec 27, 2022

 213 Dec 26, 2022
213 Dec 26, 2022

 4 Jul 18, 2021
4 Jul 18, 2021
 71 Dec 30, 2022
71 Dec 30, 2022
 1 Nov 5, 2021
1 Nov 5, 2021
 81 Dec 1, 2022
81 Dec 1, 2022
 6 Dec 6, 2022
6 Dec 6, 2022
 45 Dec 6, 2022
45 Dec 6, 2022
 1 Feb 13, 2022
1 Feb 13, 2022
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
 162 Jan 5, 2023
162 Jan 5, 2023