◥ Curriculum Labeling ◣
Revisiting Pseudo-Labeling for Semi-Supervised Learning
Paola Cascante-Bonilla, Fuwen Tan, Yanjun Qi, Vicente Ordonez.
In the 35th AAAI Conference on Artificial Intelligence. AAAI 2021.
About • Requirements • Train/Eval • Bibtex
About
In this paper we revisit the idea of pseudo-labeling in the context of semi-supervised learning where a learning algorithm has access to a small set of labeled samples and a large set of unlabeled samples. Pseudo-labeling works by applying pseudo-labels to samples in the unlabeled set by using a model trained on the combination of the labeled samples and any previously pseudo-labeled samples, and iteratively repeating this process in a self-training cycle. Current methods seem to have abandoned this approach in favor of consistency regularization methods that train models under a combination of different styles of self-supervised losses on the unlabeled samples and standard supervised losses on the labeled samples. We empirically demonstrate that pseudo-labeling can in fact be competitive with the state-of-the-art, while being more resilient to out-of-distribution samples in the unlabeled set. We identify two key factors that allow pseudo-labeling to achieve such remarkable results (1) applying curriculum learning principles and (2) avoiding concept drift by restarting model parameters before each self-training cycle. We obtain 94.91% accuracy on CIFAR-10 using only 4,000 labeled samples, and 68.87% top-1 accuracy on Imagenet-ILSVRC using only 10% of the labeled samples.

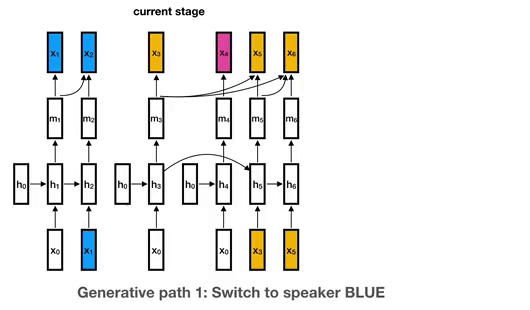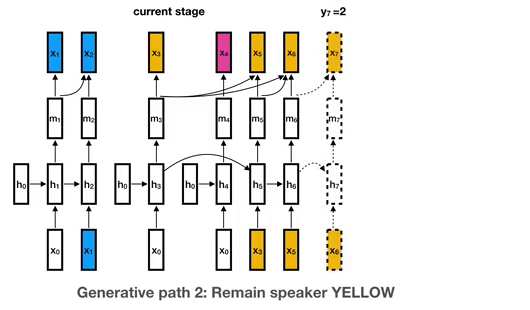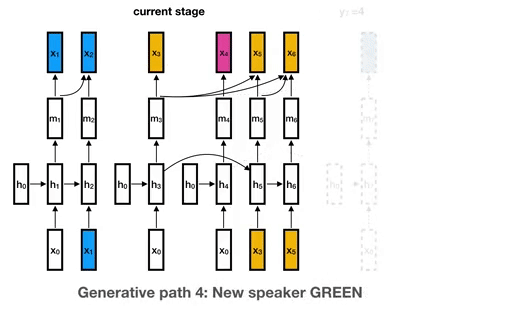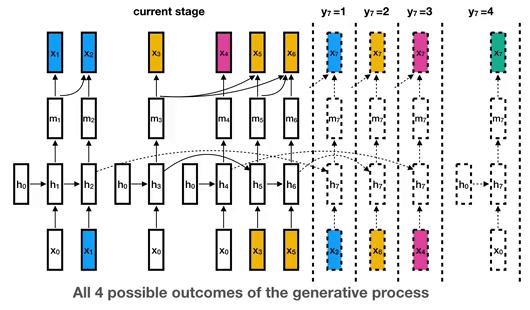
Curriculum Labeling (CL) Algorithm.
Requirements
- python >= 3.7.7
- pytorch > 1.5.0
- torchvision
- tensorflow-gpu==1.14
- torchcontrib
- pytest
- Download both zca_components.npy and zca_mean.npy. Save them in the main folder (Curriculum-Labeling).
Train
TL;DR
Run the command below to reproduce one of our experiments on CIFAR-10 with WideResNet-28-2:
python main.py --doParallel --seed 821 --nesterov --weight-decay 0.0005 --arch WRN28_2 --batch_size 512 --epochs 700 --lr_rampdown_epochs 750 --add_name WRN28_CIFAR10_AUG_MIX_SWA --mixup --swa
Everything you need to run and evaluate Curriculum Labeling is in main.py. The Wrapper class contains all the main functions to create the model, prepare the dataset, and train your model. The arguments you pass are handled by the Wrapper. For example, if you want to activate the debug mode to sneak-peak the test set scores, you can add the argument --debug when executing python main.py.
The code below shows how to set every step and get ready to train:
import wrapper as super_glue
# all possible parameters are passed to the wrapper as a dictionary
wrapper = super_glue.Wrapper(args_dict)
# one line to prepare datasets
wrapper.prepare_datasets()
# create the model
wrapper.create_network()
# set the hyperparameters
wrapper.set_model_hyperparameters()
# set optimizer (SGD or Adam)
wrapper.set_model_optimizer()
# voilà! really? sure, print the model!
print (wrapper.model)
Then you just have to call the train and evaluate functions:
# train cl
wrapper.train_cl()
# evaluate cl
wrapper.eval_cl()
Some Arguments and Usage
usage: main.py [-h] [--dataset DATASET] [--num_labeled L]
[--num_valid_samples V] [--arch ARCH] [--dropout DO]
[--optimizer OPTIMIZER] [--epochs N] [--start_epoch N] [-b N]
[--lr LR] [--initial_lr LR] [--lr_rampup EPOCHS]
[--lr_rampdown_epochs EPOCHS] [--momentum M] [--nesterov]
[--weight-decay W] [--checkpoint_epochs EPOCHS]
[--print_freq N] [--pretrained] [--root_dir ROOT_DIR]
[--data_dir DATA_DIR] [--n_cpus N_CPUS] [--add_name ADD_NAME]
[--doParallel] [--use_zca] [--pretrainedEval]
[--pretrainedFrom PATH] [-e] [-evaluateLabeled]
[-getLabeledResults]
[--set_labeled_classes SET_LABELED_CLASSES]
[--set_unlabeled_classes SET_UNLABELED_CLASSES]
[--percentiles_holder PERCENTILES_HOLDER] [--static_threshold]
[--seed SEED] [--augPolicy AUGPOLICY] [--swa]
[--swa_start SWA_START] [--swa_freq SWA_FREQ] [--mixup]
[--alpha ALPHA] [--debug]
Detailed list of Arguments
| arg | default | help |
|---|---|---|
--help |
show this help message and exit | |
--dataset |
cifar10 |
dataset: cifar10, svhn or imagenet |
--num_labeled |
400 |
number of labeled samples per class |
--num_valid_samples |
500 |
number of validation samples per class |
--arch |
cnn13 |
either of cnn13, WRN28_2, resnet50 |
--dropout |
0.0 |
dropout rate |
--optimizer |
sgd |
optimizer we are going to use. can be either adam of sgd |
--epochs |
100 |
number of total epochs to run |
--start_epoch |
0 |
manual epoch number (useful on restarts) |
--batch_size |
100 |
mini-batch size (default: 100) |
--learning-rate |
0.1 |
max learning rate |
--initial_lr |
0.0 |
initial learning rate when using linear rampup |
--lr_rampup |
0 |
length of learning rate rampup in the beginning |
--lr_rampdown_epochs |
150 |
length of learning rate cosine rampdown (>= length of training): the epoch at which learning rate reaches to zero |
--momentum |
0.9 |
momentum |
--nesterov |
use nesterov momentum | |
--wd |
0.0001 |
weight decay (default: 1e-4) |
--checkpoint_epochs |
500 |
checkpoint frequency (by epoch) |
--print_freq |
100 |
print frequency (default: 10) |
--pretrained |
use pre-trained model | |
--root_dir |
experiments |
folder where results are to be stored |
--data_dir |
/data/cifar10/ |
folder where data is stored |
--n_cpus |
12 |
number of cpus for data loading |
--add_name |
SSL_Test |
Name of your folder to store the experiment results |
--doParallel |
use DataParallel | |
--use_zca |
use zca whitening | |
--pretrainedEval |
use pre-trained model | |
--pretrainedFrom |
/full/path/ |
path to pretrained results (default: none) |
--set_labeled_classes |
0,1,2,3,4,5,6,7,8,9 |
set the classes to treat as the label set |
--set_unlabeled_classes |
0,1,2,3,4,5,6,7,8,9 |
set the classes to treat as the unlabeled set |
--percentiles_holder |
20 |
mu parameter - sets the steping percentile for thresholding after each iteration |
--static_threshold |
use static threshold | |
--seed |
0 |
define seed for random distribution of dataset |
--augPolicy |
2 |
augmentation policy: 0 for none, 1 for moderate, 2 for heavy (random-augment) |
--swa |
Apply SWA | |
--swa_start |
200 |
Start SWA |
--swa_freq |
5 |
Frequency |
--mixup |
Apply Mixup to inputs | |
--alpha |
1.0 |
mixup interpolation coefficient (default: 1) |
--debug |
Track the testing accuracy, only for debugging purposes |
Bibtex
If you use Curriculum Labeling for your research or projects, please cite Curriculum Labeling: Revisiting Pseudo-Labeling for Semi-Supervised Learning.
@misc{cascantebonilla2020curriculum,
title={Curriculum Labeling: Revisiting Pseudo-Labeling for Semi-Supervised Learning},
author={Paola Cascante-Bonilla and Fuwen Tan and Yanjun Qi and Vicente Ordonez},
year={2020},
eprint={2001.06001},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
 9 Nov 25, 2022
9 Nov 25, 2022
 69 Jan 3, 2023
69 Jan 3, 2023
 49 Aug 24, 2022
49 Aug 24, 2022

 1 Apr 17, 2022
1 Apr 17, 2022

 105 Jan 4, 2023
105 Jan 4, 2023

 3k Jan 6, 2023
3k Jan 6, 2023
 1.4k Dec 28, 2022
1.4k Dec 28, 2022

 46 Dec 15, 2022
46 Dec 15, 2022
 478 Dec 25, 2022
478 Dec 25, 2022




 128 Dec 11, 2022
128 Dec 11, 2022
 592 Dec 18, 2022
592 Dec 18, 2022
 2.3k Dec 29, 2022
2.3k Dec 29, 2022
 16 Sep 9, 2022
16 Sep 9, 2022
 6 Dec 20, 2022
6 Dec 20, 2022
 60 Dec 31, 2022
60 Dec 31, 2022
 89 Nov 10, 2022
89 Nov 10, 2022
 829 Jan 7, 2023
829 Jan 7, 2023
 1 Nov 18, 2021
1 Nov 18, 2021