crfill
Usage | Web App | | Paper | Supplementary Material | More results |
code for paper ``CR-Fill: Generative Image Inpainting with Auxiliary Contextual Reconstruction". This repo (including code and models) are for research purposes only.






Usage
Dependencies
- Download code
git clone --single-branch https://github.com/zengxianyu/crfill
git submodule init
git submodule update
- Download data and model
chmod +x download/*
./download/download_model.sh
./download/download_datal.sh
- Install dependencies:
conda env create -f environment.yml
or install these packages manually in a Python 3.6 enviroment:
pytorch=1.3.1, opencv=3.4.2, tqdm, torchvision, dill, matplotlib, opencv
Inference
./test.sh
These script will run the inpainting model on the samples I provided. Modify the options --image_dir, --mask_dir, --output_dir in test.sh to test on custom data.
Train
-
Prepare training datasets and put them in
./datasets/following the example./datasets/places -
run the training script:
./train.sh
open the html files in ./output to visualize training
After the training is finished, the model files can be found in ./checkpoints/debugarr0
you may modify the training script to use different settings, e.g., batch size, hyperparameters
Finetune
For finetune on custom dataset based on my pretrained models, use the following command:
- download checkpoints
./download/download_pretrain.sh
- run the training script
./finetune.sh
you may change the options in finetune.sh to use different hyperparameters or your own dataset
Web APP
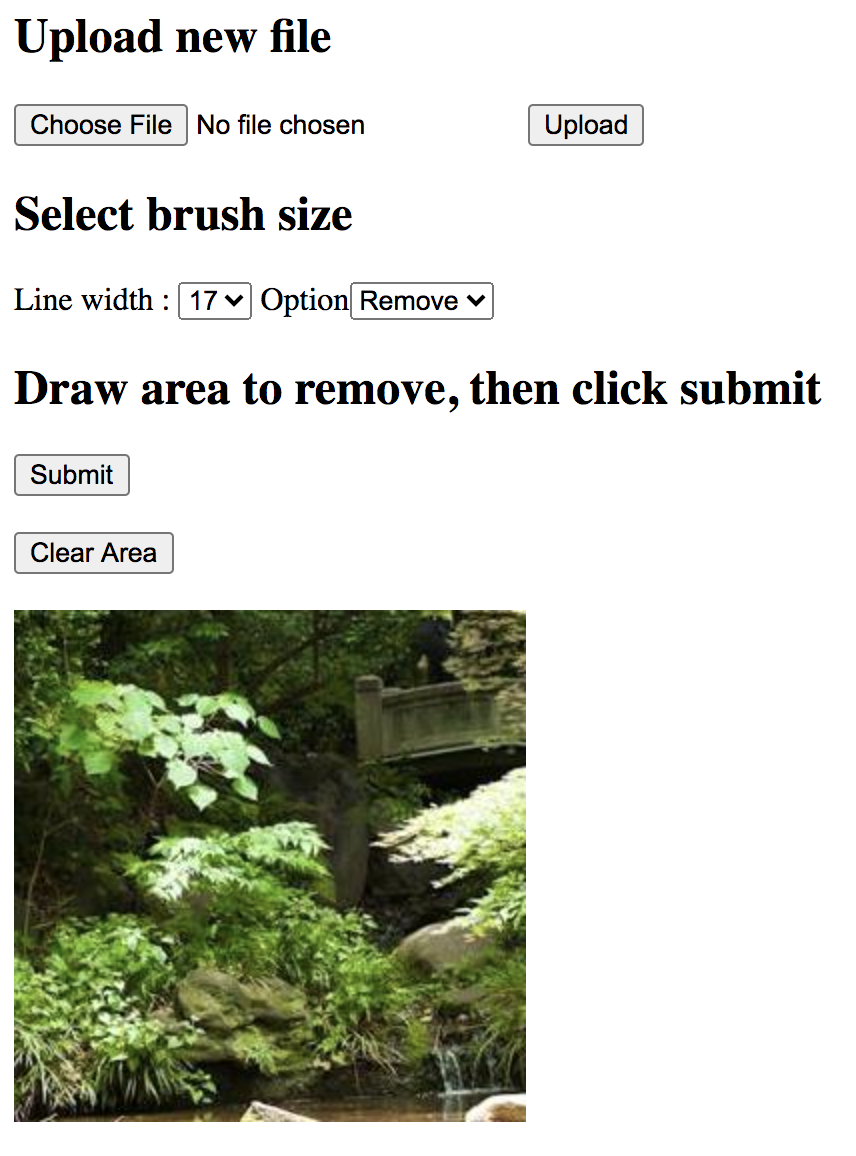
To use the web app, these additional packages are required:
flask, requests, pillow
./demo.sh
then open http://localhost:2334 in the browser to use the web app
Citing
@inproceedings{zeng2021generative,
title={CR-Fill: Generative Image Inpainting with Auxiliary Contextual Reconstruction},
author={Zeng, Yu and Lin, Zhe and Lu, Huchuan and Patel, Vishal M.},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
year={2021}
}












 122 Dec 11, 2022
122 Dec 11, 2022
 77 Dec 27, 2022
77 Dec 27, 2022
 10 Jan 1, 2023
10 Jan 1, 2023
 85 Jan 2, 2023
85 Jan 2, 2023
 152 Nov 4, 2022
152 Nov 4, 2022
 25 Nov 9, 2022
25 Nov 9, 2022
 2 Dec 24, 2021
2 Dec 24, 2021
 51 Nov 23, 2022
51 Nov 23, 2022
 117 Dec 28, 2022
117 Dec 28, 2022
 274 Jan 5, 2023
274 Jan 5, 2023
 64 Nov 19, 2022
64 Nov 19, 2022
 89 Jan 5, 2023
89 Jan 5, 2023
 42 Dec 5, 2022
42 Dec 5, 2022
 4 Jul 12, 2021
4 Jul 12, 2021
 13 Dec 10, 2022
13 Dec 10, 2022
 105 Dec 23, 2022
105 Dec 23, 2022
 55 Nov 9, 2022
55 Nov 9, 2022
 47 Oct 11, 2022
47 Oct 11, 2022