176 Repositories
Python certified-word-sub Libraries
🌸 fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
floret: fastText + Bloom embeddings for compact, full-coverage vectors with spaCy floret is an extended version of fastText that can produce word repr
 222 Dec 16, 2022
222 Dec 16, 2022

WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region. This repository provides the codebase and dataset for our work WORD: Revisiting Or
 71 Jan 7, 2023
71 Jan 7, 2023
Interpretable-contrastive-word-mover-s-embedding
Interpretable-contrastive-word-mover-s-embedding Paper Datasets Here is a Dropbox link to the datasets used in the paper: https://www.dropbox.com/sh/n
 0 Nov 2, 2021
0 Nov 2, 2021

Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch
Next Word Prediction Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch 🎬 Project Demo ✔ Application is hosted on Streamlit. You can see t
 3 Aug 26, 2022
3 Aug 26, 2022
This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user
max_tweeted_word This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user The program uses twe
 1 Nov 29, 2021
1 Nov 29, 2021
Japanese Long-Unit-Word Tokenizer with RemBertTokenizerFast of Transformers
Japanese-LUW-Tokenizer Japanese Long-Unit-Word (国語研長単位) Tokenizer for Transformers based on 青空文庫 Basic Usage from transformers import RemBertToken
 3 Dec 22, 2021
3 Dec 22, 2021
Count the frequency of letters or words in a text file and show a graph.
Word Counter By EBUS Coding Club Count the frequency of letters or words in a text file and show a graph. Requirements Python 3.9 or higher matplotlib
 0 Apr 9, 2022
0 Apr 9, 2022
This Django app will be used to host Source.Python plugins, sub-plugins, and custom packages.
Source.Python Project Manager This Django app will be used to host Source.Python plugins, sub-plugins, and custom packages. Want to help develop this
 2 Sep 24, 2022
2 Sep 24, 2022
Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR
Speech_38_ru_commands Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR Программа умеет распознавать 38 ключевы
 9 May 5, 2022
9 May 5, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022
On-device wake word detection powered by deep learning.
Porcupine Made in Vancouver, Canada by Picovoice Porcupine is a highly-accurate and lightweight wake word engine. It enables building always-listening
 2.8k Dec 29, 2022
2.8k Dec 29, 2022
![[ICCV 2021] Code release for](https://github.com/yikaiw/SNN/raw/main/intro.png)
[ICCV 2021] Code release for "Sub-bit Neural Networks: Learning to Compress and Accelerate Binary Neural Networks"
Sub-bit Neural Networks: Learning to Compress and Accelerate Binary Neural Networks By Yikai Wang, Yi Yang, Fuchun Sun, Anbang Yao. This is the pytorc
 26 Nov 20, 2022
26 Nov 20, 2022
 2 Jan 28, 2022
2 Jan 28, 2022
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
 79 Dec 27, 2022
79 Dec 27, 2022

Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordcloud packages
Wikipedia WordCloud App Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordclou
 5 Jan 2, 2022
5 Jan 2, 2022
Creates folders into a directory to categorize files in that directory by file extensions and move all things from sub-directories to current directory.
Categorize and Uncategorize Your Folders Table of Content TL;DR just take me to how to install. What are Extension Categorizer and Folder Dumper Insta
 1 Oct 17, 2021
1 Oct 17, 2021
Telegram Group Management Bot based on phython !!!
How to setup/deploy. For easiest way to deploy this Bot click on the below button Mᴀᴅᴇ Bʏ Sᴜᴘᴘᴏʀᴛ Sᴏᴜʀᴄᴇ Find This Bot on Telegram A modular Telegram
 5 Nov 17, 2021
5 Nov 17, 2021
split Word file by chapter
split Word file by chapter we use the mircosoft word api to code this tool api url:https://docs.microsoft.com/zh-cn/dotnet/api/ if this tool is good f
 5 Nov 6, 2021
5 Nov 6, 2021
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming. Outperforming `GPT-3` on SuperGLUE Few-Shot text classification.
 75 Nov 6, 2022
75 Nov 6, 2022

A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
 201 Nov 9, 2022
201 Nov 9, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022
This is a simple python script to collect sub-domains from hackertarget API
Domain-Scraper 🌐 This is a simple python script to collect sub-domains from hackertarget API Note : This is tool is limited to 20 Queries / day with
 4 Sep 9, 2021
4 Sep 9, 2021
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
79 Dec 27, 2022

MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving.
MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving. It is a comprehensive framework for research purpose that integrates popular MWP benchmark datasets and typical deep learning-based MWP algorithms.
 119 Jan 4, 2023
119 Jan 4, 2023
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
从flomo导出的笔记中生成词云
flomo-word-cloud 从flomo导出的笔记中生成词云 如何使用? 将本项目克隆到你的电脑上,使用如下的命令,安装所需python库 pip install -r requirements.txt 在项目里新建一个file文件夹,把所有从flomo导出的html文件放入其中 运行main
 9 Dec 30, 2022
9 Dec 30, 2022
A Simple, LightWeight, Statically-Typed Python3 API wrapper for GogoAnime.
AniKimi API A Simple, LightWeight, Statically-Typed Python3 API wrapper for GogoAnime The v2 of gogoanimeapi (depreciated) Made with JavaScript and Py
 17 Dec 9, 2022
17 Dec 9, 2022
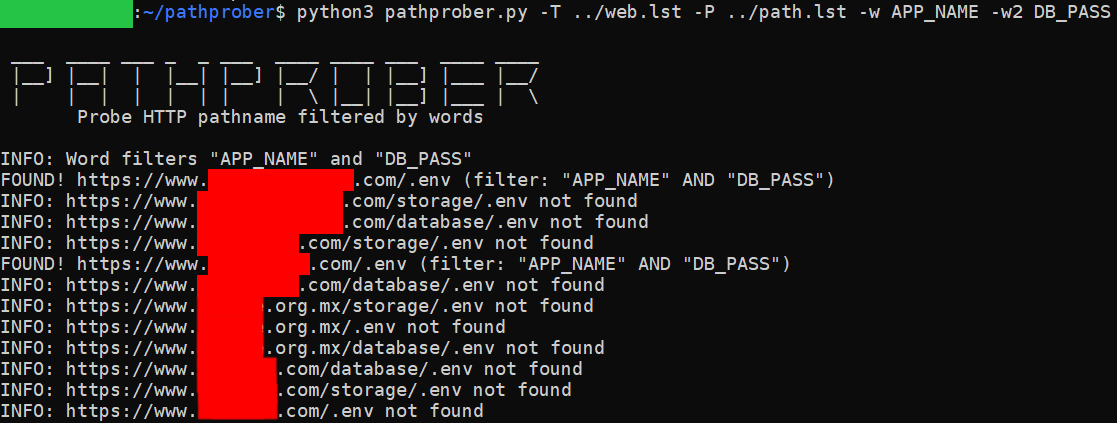
Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once
pathprober Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once. Purpose Brute-forcing webs
 41 Jul 6, 2022
41 Jul 6, 2022

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
114 Nov 4, 2022
A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
201 Nov 9, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022
Code for the ACL2021 paper "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction"
CSCBLI Code for our ACL Findings 2021 paper, "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction". Require
 12 Oct 8, 2022
12 Oct 8, 2022
Code for Graph-to-Tree Learning for Solving Math Word Problems (ACL 2020)
Graph-to-Tree Learning for Solving Math Word Problems PyTorch implementation of Graph based Math Word Problem solver described in our ACL 2020 paper G
 66 Nov 23, 2022
66 Nov 23, 2022
Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021)
L1-Refinement Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021) 🙈 A more detailed readme is co
 4 Jun 9, 2021
4 Jun 9, 2021

Code for our paper "Mask-Align: Self-Supervised Neural Word Alignment" in ACL 2021
Mask-Align: Self-Supervised Neural Word Alignment This is the implementation of our work Mask-Align: Self-Supervised Neural Word Alignment. @inproceed
 46 Dec 15, 2022
46 Dec 15, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022

A library for Multilingual Unsupervised or Supervised word Embeddings
MUSE: Multilingual Unsupervised and Supervised Embeddings MUSE is a Python library for multilingual word embeddings, whose goal is to provide the comm
 3k Jan 6, 2023
3k Jan 6, 2023
Official repository for Jia, Raghunathan, Göksel, and Liang, "Certified Robustness to Adversarial Word Substitutions" (EMNLP 2019)
Certified Robustness to Adversarial Word Substitutions This is the official GitHub repository for the following paper: Certified Robustness to Adversa
 38 Oct 16, 2022
38 Oct 16, 2022
Code and data of the Fine-Grained R2R Dataset proposed in paper Sub-Instruction Aware Vision-and-Language Navigation
Fine-Grained R2R Code and data of the Fine-Grained R2R Dataset proposed in the EMNLP2020 paper Sub-Instruction Aware Vision-and-Language Navigation. C
 34 Nov 15, 2022
34 Nov 15, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
Code for paper "A Critical Assessment of State-of-the-Art in Entity Alignment" (https://arxiv.org/abs/2010.16314)
A Critical Assessment of State-of-the-Art in Entity Alignment This repository contains the source code for the paper A Critical Assessment of State-of
 16 Oct 14, 2022
16 Oct 14, 2022
A fast and durable Pub/Sub channel over Websockets. FastAPI + WebSockets + PubSub == ⚡ 💪 ❤️
⚡ 🗞️ FastAPI Websocket Pub/Sub A fast and durable Pub/Sub channel over Websockets. The easiest way to create a live publish / subscribe multi-cast ov
 8 Dec 6, 2022
8 Dec 6, 2022

This is a c++ project deploying a deep scene text reading pipeline with tensorflow. It reads text from natural scene images. It uses frozen tensorflow graphs. The detector detect scene text locations. The recognizer reads word from each detected bounding box.
DeepSceneTextReader This is a c++ project deploying a deep scene text reading pipeline. It reads text from natural scene images. Prerequsites The proj
 49 Sep 10, 2022
49 Sep 10, 2022

Deep Learning Chinese Word Segment
引用 本项目模型BiLSTM+CRF参考论文:http://www.aclweb.org/anthology/N16-1030 ,IDCNN+CRF参考论文:https://arxiv.org/abs/1702.02098 构建 安装好bazel代码构建工具,安装好tensorflow(目前本项目需
 2.1k Dec 23, 2022
2.1k Dec 23, 2022

ARU-Net - Deep Learning Chinese Word Segment
ARU-Net: A Neural Pixel Labeler for Layout Analysis of Historical Documents Contents Introduction Installation Demo Training Introduction This is the
 128 Sep 12, 2022
128 Sep 12, 2022
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. Flair is: A powerful NLP library. Flair allo
 12.3k Jan 2, 2023
12.3k Jan 2, 2023
📝 Wrapper library for text generation / language models at char and word level with RNN in TensorFlow
tensorlm Generate Shakespeare poems with 4 lines of code. Installation tensorlm is written in / for Python 3.4+ and TensorFlow 1.1+ pip3 install tenso
 63 May 22, 2021
63 May 22, 2021
一款高性能敏感词(非法词/脏字)检测过滤组件,附带繁体简体互换,支持全角半角互换,汉字转拼音,模糊搜索等功能。
一款高性能非法词(敏感词)检测组件,附带繁体简体互换,支持全角半角互换,获取拼音首字母,获取拼音字母,拼音模糊搜索等功能。
 3.6k Jan 7, 2023
3.6k Jan 7, 2023
Yet another Python binding for fastText
pyfasttext Warning! pyfasttext is no longer maintained: use the official Python binding from the fastText repository: https://github.com/facebookresea
 228 Feb 17, 2021
228 Feb 17, 2021
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 718 Feb 18, 2021
718 Feb 18, 2021
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
 2.1k Feb 13, 2021
2.1k Feb 13, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
 1.9k Feb 18, 2021
1.9k Feb 18, 2021

🦆 Contextually-keyed word vectors
sense2vec: Contextually-keyed word vectors sense2vec (Trask et. al, 2015) is a nice twist on word2vec that lets you learn more interesting and detaile
1.2k Feb 17, 2021
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. IMPORTANT: (30.08.2020) We moved our models
10k Feb 18, 2021
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
 4.8k Feb 18, 2021
4.8k Feb 18, 2021

A little word cloud generator in Python
Linux macOS Windows PyPI word_cloud A little word cloud generator in Python. Read more about it on the blog post or the website. The code is tested ag
 7.9k Feb 17, 2021
7.9k Feb 17, 2021
Yet another Python binding for fastText
pyfasttext Warning! pyfasttext is no longer maintained: use the official Python binding from the fastText repository: https://github.com/facebookresea
230 Nov 16, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
11.7k Feb 12, 2021
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
847 Dec 19, 2022
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
2.7k Jan 8, 2023
Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
2k Dec 27, 2022
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
1.9k Feb 3, 2021
🦆 Contextually-keyed word vectors
sense2vec: Contextually-keyed word vectors sense2vec (Trask et. al, 2015) is a nice twist on word2vec that lets you learn more interesting and detaile
1.5k Dec 25, 2022
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. IMPORTANT: (30.08.2020) We moved our models
12.3k Dec 31, 2022
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
6.4k Jan 1, 2023
A little word cloud generator in Python
Linux macOS Windows PyPI word_cloud A little word cloud generator in Python. Read more about it on the blog post or the website. The code is tested ag
9.2k Dec 30, 2022
A collection of over 5.1 million sub-domains and assets belonging to public bug bounty programs, compiled into a repo, for performing bulk operations.
📂 Public Bug Bounty Targets Data By BugBountyResources A collection of over 5.1M sub-domains and assets belonging to bug bounty targets, all put in a
 87 Dec 13, 2022
87 Dec 13, 2022

PyTorch implementation of "A Full-Band and Sub-Band Fusion Model for Real-Time Single-Channel Speech Enhancement."
FullSubNet This Git repository for the official PyTorch implementation of "A Full-Band and Sub-Band Fusion Model for Real-Time Single-Channel Speech E
 357 Jan 4, 2023
357 Jan 4, 2023
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
2.1k Jan 1, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 2, 2023
pkuseg多领域中文分词工具; The pkuseg toolkit for multi-domain Chinese word segmentation
pkuseg:一个多领域中文分词工具包 (English Version) pkuseg 是基于论文[Luo et. al, 2019]的工具包。其简单易用,支持细分领域分词,有效提升了分词准确度。 目录 主要亮点 编译和安装 各类分词工具包的性能对比 使用方式 论文引用 作者 常见问题及解答 主要
 6k Dec 29, 2022
6k Dec 29, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
13.8k Jan 3, 2023