26 Repositories
Python crawling Libraries
An University Project of Quera Web Crawling.
WebCrawlerProject An University Project of Quera Web Crawling. خزشگر اینستاگرام در این پروژه شما باید با استفاده از کتابخانه های زیر یک خزشگر اینستاگر
 3 Aug 12, 2022
3 Aug 12, 2022
Python script for crawling ResearchGate.net papers✨⭐️📎
ResearchGate Crawler Python script for crawling ResearchGate.net papers About the script This code start crawling process by urls in start.txt and giv
 4 Aug 30, 2022
4 Aug 30, 2022
Robust and blazing fast open-redirect vulnerability scanner with ability of recursevely crawling all of web-forms, entry points, or links with data.
After Golismero project got dead there is no more any up to date open-source tool that can collect links with parametrs and web-forms and then test th
 34 Aug 25, 2022
34 Aug 25, 2022
Check bookings for TUM libraries.
TUM Library Checker Only for educational purposes This repository contains a crawler to save bookings for TUM libraries in a CSV file. Sample data fro
 3 Jan 27, 2022
3 Jan 27, 2022

Complete pipeline for crawling online newspaper article.
Complete pipeline for crawling online newspaper article. The articles are stored to MongoDB. The whole pipeline is dockerized, thus the user does not need to worry about dependencies. Additionally, docker-compose is available to increase the useability for the user.
 4 May 27, 2022
4 May 27, 2022
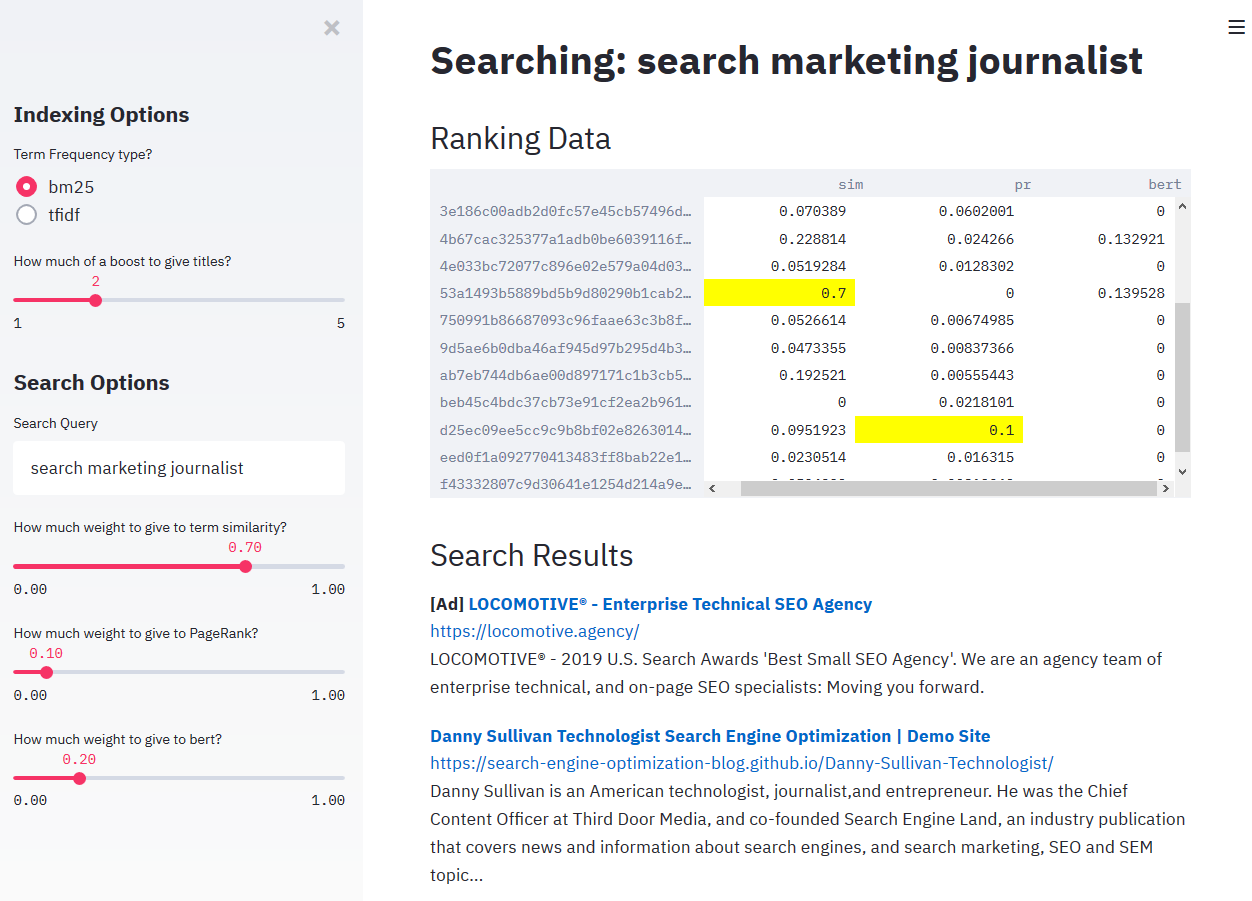
Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index.
TechSEO Crawler Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index. Play with the r
 57 Nov 24, 2022
57 Nov 24, 2022
Amazon scraper using scrapy, a python framework for crawling websites.
#Amazon-web-scraper This is a python program, which use scrapy python framework to crawl all pages of the product and scrap products data. This progra
 1 Dec 26, 2021
1 Dec 26, 2021
Pythonic Crawling / Scraping Framework based on Non Blocking I/O operations.
Pythonic Crawling / Scraping Framework Built on Eventlet Features High Speed WebCrawler built on Eventlet. Supports relational databases engines like
 173 Dec 5, 2022
173 Dec 5, 2022
Screen scraping and web crawling framework
Pomp Pomp is a screen scraping and web crawling framework. Pomp is inspired by and similar to Scrapy, but has a simpler implementation that lacks the
 61 Jun 21, 2021
61 Jun 21, 2021
Python3 script to dump employee information from XING API
XingDumper Python 3 script to dump company employees from XING API. Perfect OSINT tool ;-) The results contain firstname, lastname, position, gender,
 11 Dec 26, 2022
11 Dec 26, 2022
Scrapy uses Request and Response objects for crawling web sites.
Requests and Responses¶ Scrapy uses Request and Response objects for crawling web sites. Typically, Request objects are generated in the spiders and p
 1 Nov 3, 2021
1 Nov 3, 2021
Crawler do site Fundamentus.com com o uso do framework scrapy, tanto da aba detalhada como a de resumo.
Crawler do site Fundamentus.com com o uso do framework scrapy, tanto da aba detalhada como a de resumo. (Todas as infomações)
 3 Oct 4, 2022
3 Oct 4, 2022
Scraping news from Ucsal portal with Scrapy.
NewsScraping Esse é um projeto de raspagem das últimas noticias, de 2021, do portal da universidade Ucsal http://noosfero.ucsal.br/institucional Tecno
 0 Sep 30, 2021
0 Sep 30, 2021
API to parse tibia.com content into python objects.
Tibia.py An API to parse Tibia.com content into object oriented data. No fetching is done by this module, you must provide the html content. Features:
 25 Oct 31, 2022
25 Oct 31, 2022
declutters url lists for crawling/pentesting
uro Using a URL list for security testing can be painful as there are a lot of URLs that have uninteresting/duplicate content; uro aims to solve that.
 677 Jan 7, 2023
677 Jan 7, 2023

mlscraper: Scrape data from HTML pages automatically with Machine Learning
🤖 Scrape data from HTML websites automatically with Machine Learning
 798 Dec 29, 2022
798 Dec 29, 2022

Python code to crawl computer vision papers from top CV conferences. Currently it supports CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, SIGGRAPH
Python code to crawl computer vision papers from top CV conferences. Currently it supports CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, SIGGRAPH. It leverages selenium, a website testing framework to crawl the titles and pdf urls from the conference website, and download them one by one with some simple anti-anti-crawler tricks.
 39 Nov 21, 2022
39 Nov 21, 2022
Automatically detect changes made to the official Telegram sites.
🕷 Telegram Web Crawler This project is developed to automatically detect changes made to the official Telegram sites. This is necessary for anticipat
 115 Dec 31, 2022
115 Dec 31, 2022
Web crawling framework based on asyncio.
Web crawling framework for everyone. Written with asyncio, uvloop and aiohttp. Requirements Python3.5+ Installation pip install gain pip install uvloo
 2k Jan 5, 2023
2k Jan 5, 2023
A high-level distributed crawling framework.
Cola: high-level distributed crawling framework Overview Cola is a high-level distributed crawling framework, used to crawl pages and extract structur
 1.5k Dec 24, 2022
1.5k Dec 24, 2022
Async Python 3.6+ web scraping micro-framework based on asyncio
Ruia 🕸️ Async Python 3.6+ web scraping micro-framework based on asyncio. ⚡ Write less, run faster. Overview Ruia is an async web scraping micro-frame
 1.6k Jan 1, 2023
1.6k Jan 1, 2023
News, full-text, and article metadata extraction in Python 3. Advanced docs:
Newspaper3k: Article scraping & curation Inspired by requests for its simplicity and powered by lxml for its speed: "Newspaper is an amazing python li
 12.3k Jan 7, 2023
12.3k Jan 7, 2023
Scrapy, a fast high-level web crawling & scraping framework for Python.
Scrapy Overview Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pag
 45.5k Jan 7, 2023
45.5k Jan 7, 2023
TuShare is a utility for crawling historical data of China stocks
TuShare Tushare Pro版已发布,请访问新的官网了解和查询数据接口! https://tushare.pro TuShare是实现对股票/期货等金融数据从数据采集、清洗加工 到 数据存储过程的工具,满足金融量化分析师和学习数据分析的人在数据获取方面的需求,它的特点是数据覆盖范围广,接口
 11.9k Dec 30, 2022
11.9k Dec 30, 2022
News, full-text, and article metadata extraction in Python 3. Advanced docs:
Newspaper3k: Article scraping & curation Inspired by requests for its simplicity and powered by lxml for its speed: "Newspaper is an amazing python li
12.3k Jan 1, 2023
A high-level distributed crawling framework.
Cola: high-level distributed crawling framework Overview Cola is a high-level distributed crawling framework, used to crawl pages and extract structur
1.5k Jan 4, 2023