2713 Repositories
Python image-to-text Libraries

DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification Created by Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, Ch
 414 Jan 1, 2023
414 Jan 1, 2023

This is an implementation for the CVPR2020 paper "Learning Invariant Representation for Unsupervised Image Restoration"
Learning Invariant Representation for Unsupervised Image Restoration (CVPR 2020) Introduction This is an implementation for the paper "Learning Invari
 88 Nov 7, 2022
88 Nov 7, 2022

Textual is a TUI (Text User Interface) framework for Python using Rich as a renderer.
Textual is a TUI (Text User Interface) framework for Python using Rich as a renderer. The end goal is to be able to rapidly create rich termin
 17k Jan 2, 2023
17k Jan 2, 2023

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
Text to ASCII and ASCII to text
Text2ASCII Description This python script (converter.py) contains two functions: encode() is used to return a list of Integer, one item per character
 4 Jan 22, 2022
4 Jan 22, 2022

A Python app which can convert normal text to Handwritten text.
Text to HandWritten Text ✍️ Converter Watch Tutorial for this project Usage:- Clone my repository. Open CMD in working directory. Run following comman
 5 Dec 11, 2022
5 Dec 11, 2022
A simple programming language for manipulating images.
f-stop A simple programming language for manipulating images. Examples OPEN "image.png" AS image RESIZE image (300, 300) SAVE image "out.jpg" CLOSE im
 6 Oct 27, 2022
6 Oct 27, 2022

Rubik's cube assistant on Flask webapp
webcube Rubik's cube assistant on Flask webapp. This webapp accepts the six faces of your cube and gives you the voice instructions as a response. Req
 56 Nov 22, 2022
56 Nov 22, 2022

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
 152 Jan 2, 2023
152 Jan 2, 2023

A framework for detecting, highlighting and correcting grammatical errors on natural language text.
Gramformer Human and machine generated text often suffer from grammatical and/or typographical errors. It can be spelling, punctuation, grammatical or
 1.3k Jan 8, 2023
1.3k Jan 8, 2023

Fine-Tune EleutherAI GPT-Neo to Generate Netflix Movie Descriptions in Only 47 Lines of Code Using Hugginface And DeepSpeed
GPT-Neo-2.7B Fine-Tuning Example Using HuggingFace & DeepSpeed Installation cd venv/bin ./pip install -r ../../requirements.txt ./pip install deepspe
 180 Jan 5, 2023
180 Jan 5, 2023
Deep Text Search is an AI-powered multilingual text search and recommendation engine with state-of-the-art transformer-based multilingual text embedding (50+ languages).
Deep Text Search - AI Based Text Search & Recommendation System Deep Text Search is an AI-powered multilingual text search and recommendation engine w
 19 Sep 29, 2022
19 Sep 29, 2022

Rich.tui is a TUI (Text User Interface) framework for Python using Rich as a renderer.
rich.tui Rich.tui is a TUI (Text User Interface) framework for Python using Rich as a renderer. The end goal is to be able to rapidly create rich term
17.1k Jan 4, 2023
SparseML is a libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models
SparseML is a toolkit that includes APIs, CLIs, scripts and libraries that apply state-of-the-art sparsification algorithms such as pruning and quantization to any neural network. General, recipe-driven approaches built around these algorithms enable the simplification of creating faster and smaller models for the ML performance community at large.
 1.5k Dec 30, 2022
1.5k Dec 30, 2022
Learned image compression
Overview Pytorch code of our recent work A Unified End-to-End Framework for Efficient Deep Image Compression. We first release the code for Variationa
 163 Dec 4, 2022
163 Dec 4, 2022
Code for CVPR2021 "Visualizing Adapted Knowledge in Domain Transfer". Visualization for domain adaptation. #explainable-ai
Visualizing Adapted Knowledge in Domain Transfer @inproceedings{hou2021visualizing, title={Visualizing Adapted Knowledge in Domain Transfer}, auth
 80 Dec 25, 2022
80 Dec 25, 2022
Deep Image Search - AI-Based Image Search Engine
Deep Image Search is an AI-based image search engine that includes deep transfer learning features Extraction and tree-based vectorized search technique.
144 Jan 5, 2023

Framework for joint representation learning, evaluation through multimodal registration and comparison with image translation based approaches
CoMIR: Contrastive Multimodal Image Representation for Registration Framework 🖼 Registration of images in different modalities with Deep Learning 🤖
 55 Dec 9, 2022
55 Dec 9, 2022
Code of U2Fusion: a unified unsupervised image fusion network for multiple image fusion tasks, including multi-modal, multi-exposure and multi-focus image fusion.
U2Fusion Code of U2Fusion: a unified unsupervised image fusion network for multiple image fusion tasks, including multi-modal (VIS-IR, medical), multi
 129 Dec 11, 2022
129 Dec 11, 2022

Implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT : Cross-Attention Multi-Scale Vision Transformer for Image Classification This is an unofficial PyTorch implementation of CrossViT: Cross-Att
 103 Nov 25, 2022
103 Nov 25, 2022

This project provides an unsupervised framework for mining and tagging quality phrases on text corpora with pretrained language models (KDD'21).
UCPhrase: Unsupervised Context-aware Quality Phrase Tagging To appear on KDD'21...[pdf] This project provides an unsupervised framework for mining and
 146 Dec 22, 2022
146 Dec 22, 2022
A PyTorch implementation of paper "Learning Shared Semantic Space for Speech-to-Text Translation", ACL (Findings) 2021
Chimera: Learning Shared Semantic Space for Speech-to-Text Translation This is a Pytorch implementation for the "Chimera" paper Learning Shared Semant
 43 Dec 28, 2022
43 Dec 28, 2022

Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
 12.6k Jan 9, 2023
12.6k Jan 9, 2023
Simple, hackable offline speech to text - using the VOSK-API.
Nerd Dictation Offline Speech to Text for Desktop Linux. This is a utility that provides simple access speech to text for using in Linux without being
 844 Jan 7, 2023
844 Jan 7, 2023
Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
ImageProcessingTransformer Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
 61 Jan 1, 2023
61 Jan 1, 2023
Medical Image Segmentation using Squeeze-and-Expansion Transformers
Medical Image Segmentation using Squeeze-and-Expansion Transformers Introduction This repository contains the code of the IJCAI'2021 paper 'Medical Im
 172 Dec 20, 2022
172 Dec 20, 2022
A list of hyperspectral image super-solution resources collected by Junjun Jiang
A list of hyperspectral image super-resolution resources collected by Junjun Jiang. If you find that important resources are not included, please feel free to contact me.
 301 Jan 5, 2023
301 Jan 5, 2023
This is the official implementation of TrivialAugment and a mini-library for the application of multiple image augmentation strategies including RandAugment and TrivialAugment.
Trivial Augment This is the official implementation of TrivialAugment (https://arxiv.org/abs/2103.10158), as was used for the paper. TrivialAugment is
 94 Dec 30, 2022
94 Dec 30, 2022
Deep Image Search is an AI-based image search engine that includes deep transfor learning features Extraction and tree-based vectorized search.
Deep Image Search - AI-Based Image Search Engine Deep Image Search is an AI-based image search engine that includes deep transfer learning features Ex
139 Jan 1, 2023
VMD Audio/Text control with natural language
This repository is a proof of principle for performing Molecular Dynamics analysis, in this case with the program VMD, via natural language commands.
 13 Jun 9, 2022
13 Jun 9, 2022
Extract MNIST handwritten digits dataset binary file into bmp images
MNIST-dataset-extractor Extract MNIST handwritten digits dataset binary file into bmp images More info at http://yann.lecun.com/exdb/mnist/ Dependenci
 6 May 24, 2021
6 May 24, 2021
Code for reproducing our analysis in the paper titled: Image Cropping on Twitter: Fairness Metrics, their Limitations, and the Importance of Representation, Design, and Agency
Image Crop Analysis This is a repo for the code used for reproducing our Image Crop Analysis paper as shared on our blog post. If you plan to use this
 239 Jan 2, 2023
239 Jan 2, 2023

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022

Non-Official Pytorch implementation of "Face Identity Disentanglement via Latent Space Mapping" https://arxiv.org/abs/2005.07728 Using StyleGAN2 instead of StyleGAN
Face Identity Disentanglement via Latent Space Mapping - Implement in pytorch with StyleGAN 2 Description Pytorch implementation of the paper Face Ide
 58 Dec 24, 2022
58 Dec 24, 2022
PyTorch code for our paper "Attention in Attention Network for Image Super-Resolution"
Under construction... Attention in Attention Network for Image Super-Resolution (A2N) This repository is an PyTorch implementation of the paper "Atten
 71 Dec 30, 2022
71 Dec 30, 2022
Image data augmentation scheduler for albumentations transforms
albu_scheduler Scheduler for albumentations transforms based on PyTorch schedulers interface Usage TransformMultiStepScheduler import albumentations a
 19 Aug 4, 2021
19 Aug 4, 2021

A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval (arXiv) Repository to contain the code, models, data for end-to-end
 225 Dec 25, 2022
225 Dec 25, 2022
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution (CVPR2021)
MASA-SR Official PyTorch implementation of our CVPR2021 paper MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Re
 126 Dec 20, 2022
126 Dec 20, 2022

Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
Learning to Reconstruct 3D Manhattan Wireframes From a Single Image This repository contains the PyTorch implementation of the paper: Yichao Zhou, Hao
 50 Dec 27, 2022
50 Dec 27, 2022
Finding an Unsupervised Image Segmenter in each of your Deep Generative Models
Finding an Unsupervised Image Segmenter in each of your Deep Generative Models Description Recent research has shown that numerous human-interpretable
 61 Oct 17, 2022
61 Oct 17, 2022

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022
![[CVPRW 2021] Code for Region-Adaptive Deformable Network for Image Quality Assessment](https://github.com/IIGROUP/RADN/raw/main/Figures/architecture.png)
[CVPRW 2021] Code for Region-Adaptive Deformable Network for Image Quality Assessment
RADN [CVPRW 2021] Code for Region-Adaptive Deformable Network for Image Quality Assessment [Paper on arXiv] Overview Update [2021/5/7] add codes for W
 53 Dec 28, 2022
53 Dec 28, 2022

Text to Image Generation with Semantic-Spatial Aware GAN
text2image This repository includes the implementation for Text to Image Generation with Semantic-Spatial Aware GAN This repo is not completely. Netwo
 124 Dec 30, 2022
124 Dec 30, 2022
A collection of Korean Text Datasets ready to use using Tensorflow-Datasets.
tfds-korean A collection of Korean Text Datasets ready to use using Tensorflow-Datasets. TensorFlow-Datasets를 이용한 한국어/한글 데이터셋 모음입니다. Dataset Catalog |
 20 Jul 11, 2022
20 Jul 11, 2022

Code for Referring Image Segmentation via Cross-Modal Progressive Comprehension, CVPR2020.
CMPC-Refseg Code of our CVPR 2020 paper Referring Image Segmentation via Cross-Modal Progressive Comprehension. Shaofei Huang*, Tianrui Hui*, Si Liu,
 55 Dec 1, 2022
55 Dec 1, 2022
A PaddlePaddle version image model zoo.
Paddle-Image-Models English | 简体中文 A PaddlePaddle version image model zoo. Install Package Install by pip: $ pip install ppim Install by wheel package
 131 Dec 7, 2022
131 Dec 7, 2022
Implementation of Stochastic Image-to-Video Synthesis using cINNs.
Stochastic Image-to-Video Synthesis using cINNs Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR202
 135 Dec 28, 2022
135 Dec 28, 2022

HINet: Half Instance Normalization Network for Image Restoration
HINet: Half Instance Normalization Network for Image Restoration Liangyu Chen, Xin Lu, Jie Zhang, Xiaojie Chu, Chengpeng Chen Paper: https://arxiv.org
 303 Dec 31, 2022
303 Dec 31, 2022

PyMatting: A Python Library for Alpha Matting
Given an input image and a hand-drawn trimap (top row), alpha matting estimates the alpha channel of a foreground object which can then be composed onto a different background (bottom row).
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

Unofficial implementation of MLP-Mixer: An all-MLP Architecture for Vision
MLP-Mixer: An all-MLP Architecture for Vision This repo contains PyTorch implementation of MLP-Mixer: An all-MLP Architecture for Vision. Usage : impo
175 Dec 23, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition Released the code of RepMLP together with an example o
 260 Jan 3, 2023
260 Jan 3, 2023

Code from the paper "High-Performance Brain-to-Text Communication via Handwriting"
High-Performance Brain-to-Text Communication via Handwriting Overview This repo is associated with this manuscript, preprint and dataset. The code can
 306 Jan 3, 2023
306 Jan 3, 2023

Resources for the "Evaluating the Factual Consistency of Abstractive Text Summarization" paper
Evaluating the Factual Consistency of Abstractive Text Summarization Authors: Wojciech Kryściński, Bryan McCann, Caiming Xiong, and Richard Socher Int
 165 Dec 21, 2022
165 Dec 21, 2022

Official implement of Paper:A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sening images
A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images 深度监督影像融合网络DSIFN用于高分辨率双时相遥感影像变化检测 Of
 135 Dec 19, 2022
135 Dec 19, 2022

Unofficial implementation of Google's FNet: Mixing Tokens with Fourier Transforms
FNet: Mixing Tokens with Fourier Transforms Pytorch implementation of Fnet : Mixing Tokens with Fourier Transforms. Citation: @misc{leethorp2021fnet,
218 Jan 5, 2023

CellProfiler is a open-source application for biological image analysis
CellProfiler is a free open-source software designed to enable biologists without training in computer vision or programming to quantitatively measure phenotypes from thousands of images automatically.
 732 Dec 23, 2022
732 Dec 23, 2022

Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and convert them into audio. Here I have used Google-text-to-speech library popularly known as gTTS library to convert text file to .mp3 file. Hope you like my project!
Text to speech (using Python) Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and co
 19 Jun 30, 2022
19 Jun 30, 2022

Implementation of ResMLP, an all MLP solution to image classification, in Pytorch
ResMLP - Pytorch Implementation of ResMLP, an all MLP solution to image classification out of Facebook AI, in Pytorch Install $ pip install res-mlp-py
178 Dec 2, 2022
This is the codebase for Diffusion Models Beat GANS on Image Synthesis.
This is the codebase for Diffusion Models Beat GANS on Image Synthesis.
 3k Dec 26, 2022
3k Dec 26, 2022
A framework for cleaning Chinese dialog data
A framework for cleaning Chinese dialog data
 136 Dec 20, 2022
136 Dec 20, 2022
Code from the paper "High-Performance Brain-to-Text Communication via Handwriting"
Code from the paper "High-Performance Brain-to-Text Communication via Handwriting"
305 Dec 22, 2022
This is a Computer vision package that makes its easy to run Image processing and AI functions. At the core it uses OpenCV and Mediapipe libraries.
CVZone This is a Computer vision package that makes its easy to run Image processing and AI functions. At the core it uses OpenCV and Mediapipe librar
 648 Dec 30, 2022
648 Dec 30, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
 161 Dec 19, 2022
161 Dec 19, 2022

Vision Transformer for 3D medical image registration (Pytorch).
ViT-V-Net: Vision Transformer for Volumetric Medical Image Registration keywords: vision transformer, convolutional neural networks, image registratio
 192 Dec 20, 2022
192 Dec 20, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
Official implementation of Deep Convolutional Dictionary Learning for Image Denoising.
DCDicL for Image Denoising Hongyi Zheng*, Hongwei Yong*, Lei Zhang, "Deep Convolutional Dictionary Learning for Image Denoising," in CVPR 2021. (* Equ
 91 Dec 21, 2022
91 Dec 21, 2022
Word2Wave: a framework for generating short audio samples from a text prompt using WaveGAN and COALA.
Word2Wave is a simple method for text-controlled GAN audio generation. You can either follow the setup instructions below and use the source code and CLI provided in this repo or you can have a play around in the Colab notebook provided. Note that, in both cases, you will need to train a WaveGAN model first
 91 Dec 23, 2022
91 Dec 23, 2022

Euporie is a text-based user interface for running and editing Jupyter notebooks
Euporie is a text-based user interface for running and editing Jupyter notebooks
 781 Jan 1, 2023
781 Jan 1, 2023
Integrating the Best of TF into PyTorch, for Machine Learning, Natural Language Processing, and Text Generation. This is part of the CASL project: http://casl-project.ai/
Texar-PyTorch is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar
 726 Dec 30, 2022
726 Dec 30, 2022

Pytorch implementation of Tacotron
Tacotron-pytorch A pytorch implementation of Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model. Requirements Install python 3 Install pytorc
 203 Dec 2, 2022
203 Dec 2, 2022
A PyTorch Implementation of End-to-End Models for Speech-to-Text
speech Speech is an open-source package to build end-to-end models for automatic speech recognition. Sequence-to-sequence models with attention, Conne
 647 Dec 25, 2022
647 Dec 25, 2022

A simple command line tool for text to image generation, using OpenAI's CLIP and a BigGAN.
Ryan Murdock has done it again, combining OpenAI's CLIP and the generator from a BigGAN! This repository wraps up his work so it is easily accessible to anyone who owns a GPU.
2.3k Jan 9, 2023
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
 17k Jan 1, 2023
17k Jan 1, 2023

Code for "Unsupervised Layered Image Decomposition into Object Prototypes" paper
DTI-Sprites Pytorch implementation of "Unsupervised Layered Image Decomposition into Object Prototypes" paper Check out our paper and webpage for deta
 40 Dec 22, 2022
40 Dec 22, 2022
A Distributional Approach To Controlled Text Generation
A Distributional Approach To Controlled Text Generation This is the repository code for the ICLR 2021 paper "A Distributional Approach to Controlled T
 102 Jan 7, 2023
102 Jan 7, 2023

AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data [WIP] Unofficial Pytorch implementation of AdaSpeech 2. Requirements : All code written i
63 Dec 28, 2022
Text Generation by Learning from Demonstrations
Text Generation by Learning from Demonstrations The README was last updated on March 7, 2021. The repo is based on fairseq (v0.9.?). Paper arXiv Prere
 38 Oct 21, 2022
38 Oct 21, 2022
[EMNLP 2020] Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Contextual Action Language Model (CALM) and the ClubFloyd Dataset Code and data for paper Keep CALM and Explore: Language Models for Action Generation
 43 Dec 16, 2022
43 Dec 16, 2022
Domain Generalization with MixStyle, ICLR'21.
MixStyle This repo contains the code of our ICLR'21 paper, "Domain Generalization with MixStyle". The OpenReview link is https://openreview.net/forum?
 208 Dec 28, 2022
208 Dec 28, 2022

Official implementation of "Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets" (CVPR2021)
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets This is the official implementation of "Towards Good Pract
 52 Nov 22, 2022
52 Nov 22, 2022

A simple image/video to Desmos graph converter run locally
Desmos Bezier Renderer A simple image/video to Desmos graph converter run locally Sample Result Setup Install dependencies apt update apt install git
 339 Dec 23, 2022
339 Dec 23, 2022
Joji convert a text to corresponding emoji if emoji is available
Joji Joji convert a text to corresponding emoji if emoji is available How it Works ? 1. There is a json file with emoji names as keys and correspondin
 28 Nov 26, 2022
28 Nov 26, 2022

Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
Vision Longformer This project provides the source code for the vision longformer paper. Multi-Scale Vision Longformer: A New Vision Transformer for H
 209 Dec 30, 2022
209 Dec 30, 2022

Range Image-based LiDAR Localization for Autonomous Vehicles Using Mesh Maps
Range Image-based 3D LiDAR Localization This repo contains the code for our ICRA2021 paper: Range Image-based LiDAR Localization for Autonomous Vehicl
 208 Dec 15, 2022
208 Dec 15, 2022
Pytorch implementation of CoCon: A Self-Supervised Approach for Controlled Text Generation
COCON_ICLR2021 This is our Pytorch implementation of COCON. CoCon: A Self-Supervised Approach for Controlled Text Generation (ICLR 2021) Alvin Chan, Y
 79 Dec 18, 2022
79 Dec 18, 2022

Invert and perturb GAN images for test-time ensembling
GAN Ensembling Project Page | Paper | Bibtex Ensembling with Deep Generative Views. Lucy Chai, Jun-Yan Zhu, Eli Shechtman, Phillip Isola, Richard Zhan
 93 Dec 8, 2022
93 Dec 8, 2022

TorchFlare is a simple, beginner-friendly, and easy-to-use PyTorch Framework train your models effortlessly.
TorchFlare TorchFlare is a simple, beginner-friendly and an easy-to-use PyTorch Framework train your models without much effort. It provides an almost
 85 Dec 26, 2022
85 Dec 26, 2022
![The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]](https://github.com/Paranioar/SGRAF/raw/main/fig/model.png)
The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]
SGRAF PyTorch implementation for AAAI2021 paper of “Similarity Reasoning and Filtration for Image-Text Matching”. It is built on top of the SCAN and C
 149 Dec 22, 2022
149 Dec 22, 2022
NLPretext packages in a unique library all the text preprocessing functions you need to ease your NLP project.
NLPretext packages in a unique library all the text preprocessing functions you need to ease your NLP project.
 114 Dec 15, 2022
114 Dec 15, 2022

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023

CVPR 2021: "The Spatially-Correlative Loss for Various Image Translation Tasks"
Spatially-Correlative Loss arXiv | website We provide the Pytorch implementation of "The Spatially-Correlative Loss for Various Image Translation Task
 89 Jan 4, 2023
89 Jan 4, 2023
CorNet Correlation Networks for Extreme Multi-label Text Classification
CorNet Correlation Networks for Extreme Multi-label Text Classification Prerequisites python==3.6.3 pytorch==1.2.0 torchgpipe==0.0.5 click==7.0 ruamel
 38 Dec 31, 2022
38 Dec 31, 2022

Code for Dual Contrastive Learning for Unsupervised Image-to-Image Translation, NTIRE, CVPRW 2021.
arXiv Dual Contrastive Learning Adversarial Generative Networks (DCLGAN) We provide our PyTorch implementation of DCLGAN, which is a simple yet powerf
 119 Dec 4, 2022
119 Dec 4, 2022

Two-Stage Peer-Regularized Feature Recombination for Arbitrary Image Style Transfer
Two-Stage Peer-Regularized Feature Recombination for Arbitrary Image Style Transfer Paper on arXiv Public PyTorch implementation of two-stage peer-reg
 38 Oct 14, 2022
38 Oct 14, 2022
PyKale is a PyTorch library for multimodal learning and transfer learning as well as deep learning and dimensionality reduction on graphs, images, texts, and videos
PyKale is a PyTorch library for multimodal learning and transfer learning as well as deep learning and dimensionality reduction on graphs, images, texts, and videos. By adopting a unified pipeline-based API design, PyKale enforces standardization and minimalism, via reusing existing resources, reducing repetitions and redundancy, and recycling learning models across areas.
 370 Dec 27, 2022
370 Dec 27, 2022
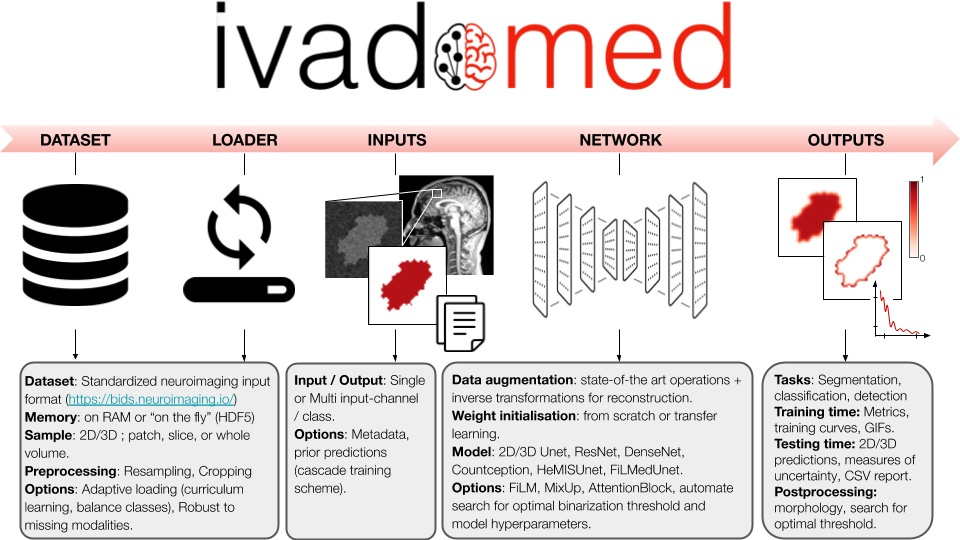
ivadomed is an integrated framework for medical image analysis with deep learning.
Repository on the collaborative IVADO medical imaging project between the Mila and NeuroPoly labs.
 144 Dec 19, 2022
144 Dec 19, 2022
Code for the paper "Improving Vision-and-Language Navigation with Image-Text Pairs from the Web" (ECCV 2020)
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh
 44 Dec 14, 2022
44 Dec 14, 2022
Reimplementation of the paper `Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words? (ACL2020)`
Human Attention for Text Classification Re-implementation of the paper Human Attention Maps for Text Classification: Do Humans and Neural Networks Foc
 15 Dec 13, 2021
15 Dec 13, 2021

codes for Image Inpainting with External-internal Learning and Monochromic Bottleneck
Image Inpainting with External-internal Learning and Monochromic Bottleneck This repository is for the CVPR 2021 paper: 'Image Inpainting with Externa
 97 Nov 29, 2022
97 Nov 29, 2022
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023