346 Repositories
Python microphone-audio-capture Libraries

Official repository accompanying a CVPR 2022 paper EMOCA: Emotion Driven Monocular Face Capture And Animation. EMOCA takes a single image of a face as input and produces a 3D reconstruction. EMOCA sets the new standard on reconstructing highly emotional images in-the-wild
EMOCA: Emotion Driven Monocular Face Capture and Animation Radek Daněček · Michael J. Black · Timo Bolkart CVPR 2022 This repository is the official i
 339 Dec 30, 2022
339 Dec 30, 2022

A python script to dump all the challenges locally of a CTFd-based Capture the Flag.
A python script to dump all the challenges locally of a CTFd-based Capture the Flag. Features Connects and logins to a remote CTFd instance. Dumps all
 77 Dec 7, 2022
77 Dec 7, 2022

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023

A lightweight yet powerful audio-to-MIDI converter with pitch bend detection
Basic Pitch is a Python library for Automatic Music Transcription (AMT), using lightweight neural network developed by Spotify's Audio Intelligence La
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
RAVE: Realtime Audio Variational autoEncoder Official implementation of RAVE: A variational autoencoder for fast and high-quality neural audio synthes
 587 Jan 1, 2023
587 Jan 1, 2023

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022 [Project page | Video] Getting sta
 51 Nov 29, 2022
51 Nov 29, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Classification models 1D Zoo - Keras and TF.Keras
Classification models 1D Zoo - Keras and TF.Keras This repository contains 1D variants of popular CNN models for classification like ResNets, DenseNet
 12 Jan 6, 2023
12 Jan 6, 2023

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022

Audio-analytics for music-producers! Automate tedious tasks such as musical scale detection, BPM rate classification and audio file conversion.
Click here to be re-directed to the Beat Inspect Streamlit Web-App You are a music producer? Let's get in touch via LinkedIn Fundamental Analytics for
 11 Dec 27, 2022
11 Dec 27, 2022
Hack Camera, Microphone, Location, Clipboard With Just a Link. Also, Get Many Details About Victim's Device. And So On...
An Automated Tool to Hack Victim's Camera, Microphone, Location, Clipboard. Has 2 Extra Features. Version 1.1 Update Fixed Some Major Bugs Data Saving
 36 Jan 7, 2023
36 Jan 7, 2023
Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution.
convolver Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution. Created by Sean Higley [email protected]
 1 Feb 23, 2022
1 Feb 23, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022

MoCap-Solver: A Neural Solver for Optical Motion Capture Data
MoCap-Solver is a data-driven-based robust marker denoising method, which takes raw mocap markers as input and outputs corresponding clean markers and skeleton motions.
 55 Dec 28, 2022
55 Dec 28, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022

Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
 58 Dec 24, 2022
58 Dec 24, 2022

TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
TONet Introduction The official implementation of "TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music", in ICASSP 2022 We
 29 Dec 1, 2022
29 Dec 1, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
13 Feb 8, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022
YoutubeDownloader - Repo for downloading YT audio and videos
YoutubeDownloader Downloads video/playlist/audio from youtube url. install all t
 2 Feb 17, 2022
2 Feb 17, 2022

Automatically capture your Ookla Speedtest metrics and display them in a Grafana dashboard
Speedtest All-In-One Automatically capture your Ookla Speedtest metrics and display them in a Grafana dashboard. Getting Started About This Code This
 2 Feb 22, 2022
2 Feb 22, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023

camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
 1 Jun 21, 2022
1 Jun 21, 2022
MoRecon - A tool for reconstructing missing frames in motion capture data.
MoRecon - A tool for reconstructing missing frames in motion capture data.
 38 Dec 3, 2022
38 Dec 3, 2022
This Open-Source project is great for sensor capture and storage solutions.
Phase 1 This project helps developers in the creation of extended realities that communicate with Arduino and require the security of blockchain stora
 10 Dec 28, 2022
10 Dec 28, 2022

Django Query Capture can check the query situation at a glance, notice slow queries, and notice where N+1 occurs.
django-query-capture Overview Django Query Capture can check the query situation at a glance, notice slow queries, and notice where N+1 occurs. Some r
 80 Nov 22, 2022
80 Nov 22, 2022
Audio Retrieval with Natural Language Queries: A Benchmark Study
Audio Retrieval with Natural Language Queries: A Benchmark Study Paper | Project page | Text-to-audio search demo This repository is the implementatio
 21 Oct 31, 2022
21 Oct 31, 2022
This is the source code for the experiments related to the paper Unsupervised Audio Source Separation Using Differentiable Parametric Source Models
Unsupervised Audio Source Separation Using Differentiable Parametric Source Models This is the source code for the experiments related to the paper Un
 30 Oct 19, 2022
30 Oct 19, 2022

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
An NVDA add-on to split screen reader and audio from other programs to different sound channels
An NVDA add-on to split screen reader and audio from other programs to different sound channels (add-on idea credit: Tony Malykh)
 7 Dec 25, 2022
7 Dec 25, 2022
A tool for retrieving audio in the past
Rewinder A tool for retrieving audio in the past. Ever felt like, I need to remember that discussion which happened 10 min back. Now you can! Rewind a
 1 Jan 24, 2022
1 Jan 24, 2022
In this project, we'll be making our own screen recorder in Python using some libraries.
Screen Recorder in Python Project Description: In this project, we'll be making our own screen recorder in Python using some libraries. Requirements:
 4 Jan 24, 2022
4 Jan 24, 2022

Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution
Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution Figure: Example visualization of the method and baseline as a
 16 Dec 23, 2022
16 Dec 23, 2022

Audio2Face - Audio To Face With Python
Audio2Face Discription We create a project that transforms audio to blendshape w
724 Dec 26, 2022
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning My
 3 Apr 10, 2022
3 Apr 10, 2022
TikTok - TikTok Bot to download video or audio from TikTok
TikTok - TikTok Bot to download video or audio from TikTok
 51 Mar 4, 2022
51 Mar 4, 2022
Blender 2.80+ Timelapse Capture Tool Addon
SimpleTimelapser Blender 2.80+ Timelapse Capture Tool Addon Developed for Blender 3.0.0, tested working on 2.80.0 It's no ZBrush undo history but it's
 4 Jan 19, 2022
4 Jan 19, 2022
A2DP agent for promiscuous/permissive audio sinc.
Promiscuous Bluetooth audio sinc A2DP agent for promiscuous/permissive audio sinc for Linux. Once installed, a Bluetooth client, such as a smart phone
 4 May 27, 2022
4 May 27, 2022

Animal Sound Classification (Cats Vrs Dogs Audio Sentiment Classification)
this is a simple artificial neural network model using deep learning and torch-audio to classify cats and dog sounds.
 3 Dec 5, 2022
3 Dec 5, 2022

Terminal-based music player written in Python for the best music in the world 🎵 🎧 💻
audius-terminal-player Terminal-based music player written in Python for the best music in the world 🎵 🎧 💻 Browse and listen to Audius from the com
 21 Jul 23, 2022
21 Jul 23, 2022
Opencv-image-filters - A camera to capture videos in real time by placing filters using Python with the help of the Tkinter and OpenCV libraries
Opencv-image-filters - A camera to capture videos in real time by placing filters using Python with the help of the Tkinter and OpenCV libraries
 1 Jan 13, 2022
1 Jan 13, 2022

NeROIC: Neural Object Capture and Rendering from Online Image Collections
NeROIC: Neural Object Capture and Rendering from Online Image Collections This repository is for the source code for the paper NeROIC: Neural Object C
 647 Dec 27, 2022
647 Dec 27, 2022
API Server for VoIP analysis (CDR + Audio CODECs)
Swagger generated server Overview This server was generated by the swagger-codegen project. By using the OpenAPI-Spec from a remote server, you can ea
 1 Jan 11, 2022
1 Jan 11, 2022
A wrapper around ffmpeg to make it work in a concurrent and memory-buffered fashion.
Media Fixer Have you ever had a film or TV show that your TV wasn't able to play its audio? Well this program is for you. Media Fixer is a program whi
 3 May 4, 2022
3 May 4, 2022
A simple program to make MSI Modern 15 speaker and microphone mute led work.
MSI Modern 15 sound led fixup for linux A simple program to fix the MSI Modern 15 speaker and microphone mute LEDs. Installation Requirements pulsectl
 4 Oct 18, 2022
4 Oct 18, 2022
A Python package for time series augmentation
tsaug tsaug is a Python package for time series augmentation. It offers a set of augmentation methods for time series, as well as a simple API to conn
 278 Jan 1, 2023
278 Jan 1, 2023
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023

A self-supervised learning framework for audio-visual speech
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Self-Supervised A
431 Jan 7, 2023
CTF (Capture The Flag) started from DEFCON CTF, a competitive game among computer security enthusiasts
CTF Wiki 中文 English Welcome to CTF Wiki! CTF (Capture The Flag) started from DEFCON CTF, a competitive game among computer security enthusiasts, origi
 6.4k Jan 3, 2023
6.4k Jan 3, 2023
BART aids transcribe tasks by taking a source audio file and creating automatic repeated loops, allowing transcribers to listen to fragments multiple times
BART (Beyond Audio Replay Technology) aids transcribe tasks by taking a source audio file and creating automatic repeated loops, allowing transcribers to listen to fragments multiple times (with possible overlap between segments).
 2 Feb 4, 2022
2 Feb 4, 2022
Space robot - (Course Project) Using the space robot to capture the target satellite that is disabled and spinning, then stabilize and fix it up
Space robot - (Course Project) Using the space robot to capture the target satellite that is disabled and spinning, then stabilize and fix it up
 3 Jan 7, 2022
3 Jan 7, 2022

Automagically synchronize subtitles with video.
FFsubsync Language-agnostic automatic synchronization of subtitles with video, so that subtitles are aligned to the correct starting point within the
 5.7k Jan 6, 2023
5.7k Jan 6, 2023
Code for the paper "Jukebox: A Generative Model for Music"
Status: Archive (code is provided as-is, no updates expected) Jukebox Code for "Jukebox: A Generative Model for Music" Paper Blog Explorer Colab Insta
 6k Jan 2, 2023
6k Jan 2, 2023
User-friendly packet captures
capture-packets: User-friendly packet captures Please read before using All network traffic occurring on your machine is captured (unless you specify
 2 Feb 5, 2022
2 Feb 5, 2022
🎵 Python sound notifications made easy
chime Python sound notifications made easy. Table of contents Table of contents Motivation Installation Basic usage Theming IPython/Jupyter magic Exce
 231 Jan 9, 2023
231 Jan 9, 2023

Audio-to-symbolic Arrangement via Cross-modal Music Representation Learning
Automatic Audio-to-symbolic Arrangement This is the repository of the project "Audio-to-symbolic Arrangement via Cross-modal Music Representation Lear
 6 Jan 5, 2022
6 Jan 5, 2022
Audio2midi - Automatic Audio-to-symbolic Arrangement
Automatic Audio-to-symbolic Arrangement This is the repository of the project "A
24 Dec 5, 2022

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

WaveFake: A Data Set to Facilitate Audio DeepFake Detection
WaveFake: A Data Set to Facilitate Audio DeepFake Detection This is the code repository for our NeurIPS 2021 (Track on Datasets and Benchmarks) paper
 27 Dec 22, 2022
27 Dec 22, 2022
Rocks vc Userbot: A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group
⭐️ Rocks VC Userbot ⭐️ Telegram Userbot To Play Audio And Video Song On VC Chat
 10 Jul 18, 2022
10 Jul 18, 2022

Highlight Translator can help you translate the words quickly and accurately.
Highlight Translator can help you translate the words quickly and accurately. By only highlighting, copying, or screenshoting the content you want to translate anywhere on your computer (ex. PDF, PPT, WORD etc.), the translated results will then be automatically displayed before you.
 48 Dec 21, 2022
48 Dec 21, 2022
Youtube video downloader and info extractor for python.
tube_dl Tube_dl is a Simple Youtube video downloader for Python. A Modular approach to bypass and download Youtube Videos and Playlist from Youtube us
 16 Jul 9, 2022
16 Jul 9, 2022
Library for Python 3 to communicate with the Google Chromecast.
pychromecast Library for Python 3.6+ to communicate with the Google Chromecast. It currently supports: Auto discovering connected Chromecasts on the n
 2.4k Jan 2, 2023
2.4k Jan 2, 2023
 42 Oct 5, 2022
42 Oct 5, 2022

A timer for bird lovers, plays a random birdcall while displaying its image and info.
Birdcall Timer A timer for bird lovers. Siriema hatchling by Junior Peres Junior Background My partner needed a customizable timer for sitting and sta
 1 Jul 8, 2022
1 Jul 8, 2022

A stable and Fast telegram video convertor bot which can compress, convert(video into audio and other video formats), rename with permanent thumbnail and trim.
ᴠɪᴅᴇᴏ ᴄᴏɴᴠᴇʀᴛᴏʀ A stable and Fast telegram video convertor bot which can compress, convert(video into audio and other video formats), rename and trim.
 183 Jan 4, 2023
183 Jan 4, 2023
An implementation of the Contrast Predictive Coding (CPC) method to train audio features in an unsupervised fashion.
CPC_audio This code implements the Contrast Predictive Coding algorithm on audio data, as described in the paper Unsupervised Pretraining Transfers we
283 Dec 30, 2022
Code for Paper: Self-supervised Learning of Motion Capture
Self-supervised Learning of Motion Capture This is code for the paper: Hsiao-Yu Fish Tung, Hsiao-Wei Tung, Ersin Yumer, Katerina Fragkiadaki, Self-sup
 87 Jul 25, 2022
87 Jul 25, 2022

Code for the paper: Audio-Visual Scene Analysis with Self-Supervised Multisensory Features
[Paper] [Project page] This repository contains code for the paper: Andrew Owens, Alexei A. Efros. Audio-Visual Scene Analysis with Self-Supervised Mu
 202 Dec 13, 2022
202 Dec 13, 2022
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
6 Jun 20, 2022
Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio.
YouTube-Downloader Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio. G
 2 Dec 27, 2021
2 Dec 27, 2021
Easily download audio described movies and TV shows found on audiovault.net
AudioVault Downloader A convenient downloader for audio described movies and TV shows found on the Audio Vault. get latest binary release for Windows
 5 Feb 10, 2022
5 Feb 10, 2022
EmoTag helps you train emotion detection model for Chinese audios
emoTag emoTag helps you train emotion detection model for Chinese audios. Environment pip install -r requirement.txt Data We used Emotional Speech Dat
 4 Sep 7, 2022
4 Sep 7, 2022
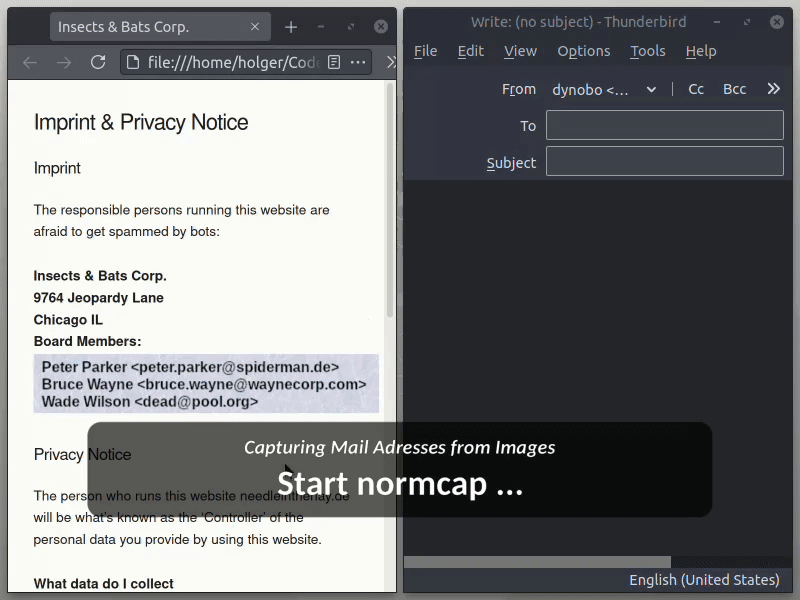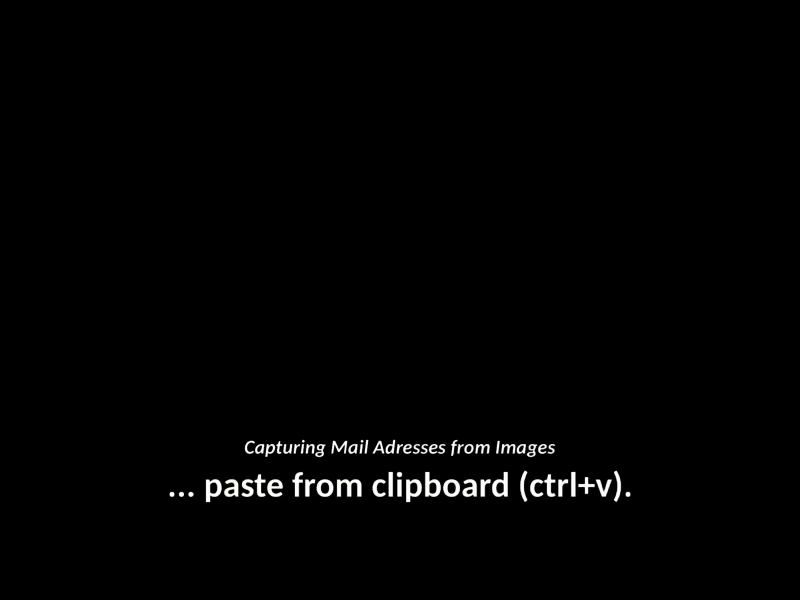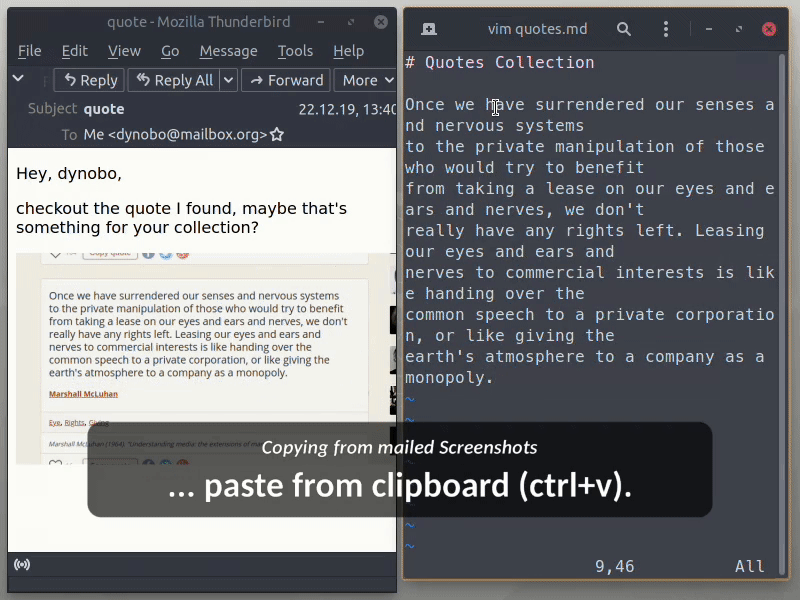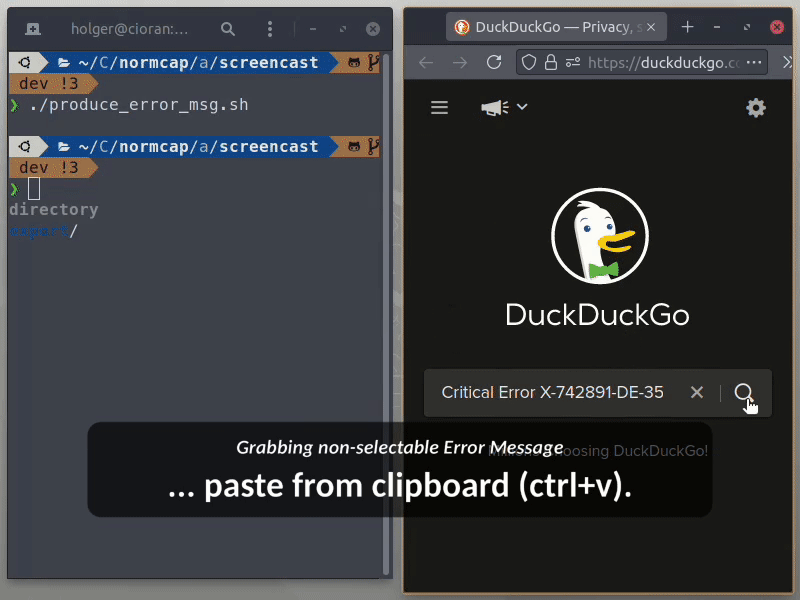
OCR powered screen-capture tool to capture information instead of images
NormCap OCR powered screen-capture tool to capture information instead of images. Links: Repo | PyPi | Releases | Changelog | FAQs Content: Quickstart
 575 Dec 31, 2022
575 Dec 31, 2022
A python library for working with praat, textgrids, time aligned audio transcripts, and audio files.
praatIO Questions? Comments? Feedback? A library for working with praat, time aligned audio transcripts, and audio files that comes with batteries inc
 224 Dec 19, 2022
224 Dec 19, 2022
A collection of python scripts for extracting and analyzing acoustics from audio files.
pyAcoustics A collection of python scripts for extracting and analyzing acoustics from audio files. Contents 1 Common Use Cases 2 Major revisions 3 Fe
74 Dec 26, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

Audio pitch-shifting & re-sampling utility, based on the EMU SP-1200
Pitcher.py Free & OS emulation of the SP-12 & SP-1200 signal chain (now with GUI) Pitch shift / bitcrush / resample audio files Written and tested in
 13 Oct 3, 2022
13 Oct 3, 2022

Differential rendering based motion capture blender project.
TraceArmature Summary TraceArmature is currently a set of python scripts that allow for high fidelity motion capture through the use of AI pose estima
 4 May 27, 2022
4 May 27, 2022
PcapXray - A Network Forensics Tool - To visualize a Packet Capture offline as a Network Diagram
PcapXray - A Network Forensics Tool - To visualize a Packet Capture offline as a Network Diagram including device identification, highlight important communication and file extraction
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
VIsually-Pivoted Audio and(N) Text
VIP-ANT: VIsually-Pivoted Audio and(N) Text Code for the paper Connecting the Dots between Audio and Text without Parallel Data through Visual Knowled
 16 Nov 4, 2022
16 Nov 4, 2022
A Telegram bot to transcribe audio, video and image into text.
Transcriber Bot A Telegram bot to transcribe audio, video and image into text. Deploy to Heroku Local Deploying Install the FFmpeg. Make sure you have
 10 Dec 19, 2022
10 Dec 19, 2022
Wav2Vec for speech recognition, classification, and audio classification
Soxan در زبان پارسی به نام سخن This repository consists of models, scripts, and notebooks that help you to use all the benefits of Wav2Vec 2.0 in your
 140 Dec 15, 2022
140 Dec 15, 2022
Python script for downloading audio from YouTube songs/videos.
Python script for downloading audio from YouTube songs/videos. All you have to do is specify the path to your folder and then type song's/video's name and the sound will be downloaded into your folder.
 0 Oct 5, 2022
0 Oct 5, 2022
Make an audio file (really) long-winded
longwind Make an audio file (really) long-winded Daily repetitions are an illusion anyway.
 2 Sep 12, 2022
2 Sep 12, 2022

Use .csv files to record, play and evaluate motion capture data.
Purpose These scripts allow you to record mocap data to, and play from .csv files. This approach facilitates parsing of body movement data in statisti
 21 Dec 12, 2022
21 Dec 12, 2022

An implementation of "Learning human behaviors from motion capture by adversarial imitation"
Merel-MoCap-GAIL An implementation of Merel et al.'s paper on generative adversarial imitation learning (GAIL) using motion capture (MoCap) data: Lear
 34 Nov 12, 2022
34 Nov 12, 2022
pyo is a Python module written in C to help digital signal processing script creation.
pyo is a Python module written in C to help digital signal processing script creation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023

Code for "Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose"
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose We provide PyTorch implementations for our arxiv paper "Audio-dr
 497 Jan 9, 2023
497 Jan 9, 2023

DECA: Detailed Expression Capture and Animation (SIGGRAPH 2021)
DECA: Detailed Expression Capture and Animation (SIGGRAPH2021) input image, aligned reconstruction, animation with various poses & expressions This is
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
![MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]](https://github.com/uniBruce/Mead/raw/master/Figures/mead.png)
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020] by Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wa
 112 Dec 28, 2022
112 Dec 28, 2022