84 Repositories
Python mil-creative-captioning Libraries

RuDOLPH: One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP
[Paper] [Хабр] [Model Card] [Colab] [Kaggle] RuDOLPH 🦌 🎄 ☃️ One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP Russian Diffusio
 232 Jan 4, 2023
232 Jan 4, 2023

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023
Easily display all of your creative avatars to keep them consistent across websites.
PyAvatar Easily display all of your creative avatars to keep them consistent across websites. Key Features • Download • How To Use • Support • Contrib
 2 Oct 2, 2022
2 Oct 2, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023
End-to-end image captioning with EfficientNet-b3 + LSTM with Attention
Image captioning End-to-end image captioning with EfficientNet-b3 + LSTM with Attention Model is seq2seq model. In the encoder pretrained EfficientNet
 2 Feb 10, 2022
2 Feb 10, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
A boosting-based Multiple Instance Learning (MIL) package that includes MIL-Boost and MCIL-Boost
A boosting-based Multiple Instance Learning (MIL) package that includes MIL-Boost and MCIL-Boost
 27 Aug 8, 2022
27 Aug 8, 2022

Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
 1 Jan 23, 2022
1 Jan 23, 2022

Image Captioning on google cloud platform based on iot
Image-Captioning-on-google-cloud-platform-based-on-iot - Image Captioning on google cloud platform based on iot
 1 Jan 20, 2022
1 Jan 20, 2022
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
 7 Jan 13, 2022
7 Jan 13, 2022
Joy is a tiny creative coding library in Python.
Joy Joy is a tiny creative coding library in Python. Installation The easiest way to install it is download joy.py and place it in your directory. The
 181 Dec 4, 2022
181 Dec 4, 2022
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
19 Dec 12, 2022
RuDOLPH: One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP
[Paper] [Хабр] [Model Card] [Colab] [Kaggle] RuDOLPH 🦌 🎄 ☃️ One Hyper-Modal Tr
 230 Dec 31, 2022
230 Dec 31, 2022
Creative Applications of Deep Learning w/ Tensorflow
Creative Applications of Deep Learning w/ Tensorflow This repository contains lecture transcripts and homework assignments as Jupyter Notebooks for th
 1.5k Dec 30, 2022
1.5k Dec 30, 2022

End-to-End Dense Video Captioning with Parallel Decoding (ICCV 2021)
PDVC Official implementation for End-to-End Dense Video Captioning with Parallel Decoding (ICCV 2021) [paper] [valse论文速递(Chinese)] This repo supports:
 118 Dec 16, 2022
118 Dec 16, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023
![[CVPR 2021] Scan2Cap: Context-aware Dense Captioning in RGB-D Scans](https://github.com/daveredrum/Scan2Cap/raw/main/demo/Scan2Cap.gif)
[CVPR 2021] Scan2Cap: Context-aware Dense Captioning in RGB-D Scans
Scan2Cap: Context-aware Dense Captioning in RGB-D Scans Introduction We introduce the task of dense captioning in 3D scans from commodity RGB-D sensor
 79 Nov 7, 2022
79 Nov 7, 2022
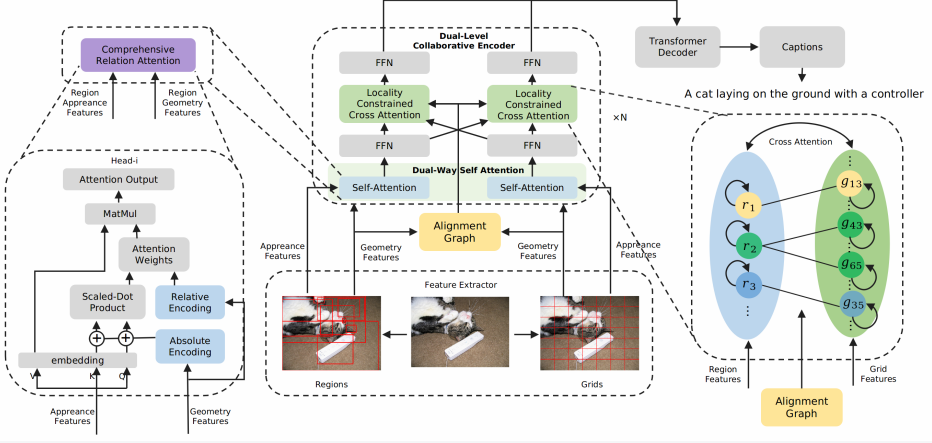
Official pytorch implementation of paper Dual-Level Collaborative Transformer for Image Captioning (AAAI 2021).
Dual-Level Collaborative Transformer for Image Captioning This repository contains the reference code for the paper Dual-Level Collaborative Transform
 160 Dec 11, 2022
160 Dec 11, 2022
Official pytorch implementation of the AAAI 2021 paper Semantic Grouping Network for Video Captioning
Semantic Grouping Network for Video Captioning Hobin Ryu, Sunghun Kang, Haeyong Kang, and Chang D. Yoo. AAAI 2021. [arxiv] Environment Ubuntu 16.04 CU
 43 Nov 25, 2022
43 Nov 25, 2022
LaBERT - A length-controllable and non-autoregressive image captioning model.
Length-Controllable Image Captioning (ECCV2020) This repo provides the implemetation of the paper Length-Controllable Image Captioning. Install conda
 53 Nov 13, 2022
53 Nov 13, 2022
PyTorch code for: Learning to Generate Grounded Visual Captions without Localization Supervision
Learning to Generate Grounded Visual Captions without Localization Supervision This is the PyTorch implementation of our paper: Learning to Generate G
 41 Nov 17, 2022
41 Nov 17, 2022
ECCV2020 paper: Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards. Code and Data.
This repo contains some of the codes for the following paper Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards. Code
 56 Dec 8, 2022
56 Dec 8, 2022
Moer Grounded Image Captioning by Distilling Image-Text Matching Model
Moer Grounded Image Captioning by Distilling Image-Text Matching Model Requirements Python 3.7 Pytorch 1.2 Prepare data Please use git clone --recurse
60 Dec 16, 2022

Meshed-Memory Transformer for Image Captioning. CVPR 2020
M²: Meshed-Memory Transformer This repository contains the reference code for the paper Meshed-Memory Transformer for Image Captioning (CVPR 2020). Pl
 422 Dec 28, 2022
422 Dec 28, 2022
![Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]](https://github.com/JDAI-CV/image-captioning/raw/master/images/framework.jpg)
Implementation of 'X-Linear Attention Networks for Image Captioning' [CVPR 2020]
Introduction This repository is for X-Linear Attention Networks for Image Captioning (CVPR 2020). The original paper can be found here. Please cite wi
 240 Dec 17, 2022
240 Dec 17, 2022
![[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning](https://github.com/alasdairtran/transform-and-tell/raw/master/figures/teaser.png)
[CVPR 2020] Transform and Tell: Entity-Aware News Image Captioning
Transform and Tell: Entity-Aware News Image Captioning This repository contains the code to reproduce the results in our CVPR 2020 paper Transform and
 85 Dec 13, 2022
85 Dec 13, 2022
WeakVRD-Captioning - Implementation of paper Improving Image Captioning with Better Use of Caption
WeakVRD-Captioning - Implementation of paper Improving Image Captioning with Better Use of Caption
 30 Oct 28, 2022
30 Oct 28, 2022
PyTorch code for MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning
MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning PyTorch code for our ACL 2020 paper "MART: Memory-Augmented Recur
 151 Jan 6, 2023
151 Jan 6, 2023
Code for paper Adaptively Aligned Image Captioning via Adaptive Attention Time
Adaptively Aligned Image Captioning via Adaptive Attention Time This repository includes the implementation for Adaptively Aligned Image Captioning vi
 45 Aug 27, 2022
45 Aug 27, 2022
Implementation of the Object Relation Transformer for Image Captioning
Object Relation Transformer This is a PyTorch implementation of the Object Relation Transformer published in NeurIPS 2019. You can find the paper here
 158 Dec 24, 2022
158 Dec 24, 2022
Unsupervised captioning - Code for Unsupervised Image Captioning
Unsupervised Image Captioning by Yang Feng, Lin Ma, Wei Liu, and Jiebo Luo Introduction Most image captioning models are trained using paired image-se
 207 Dec 24, 2022
207 Dec 24, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022

GoodNews Everyone! Context driven entity aware captioning for news images
This is the code for a CVPR 2019 paper, called GoodNews Everyone! Context driven entity aware captioning for news images. Enjoy! Model preview: Huge T
 117 Dec 19, 2022
117 Dec 19, 2022
This repository focus on Image Captioning & Video Captioning & Seq-to-Seq Learning & NLP
Awesome-Visual-Captioning Table of Contents ACL-2021 CVPR-2021 AAAI-2021 ACMMM-2020 NeurIPS-2020 ECCV-2020 CVPR-2020 ACL-2020 AAAI-2020 ACL-2019 NeurI
 362 Jan 3, 2023
362 Jan 3, 2023

Show-attend-and-tell - TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022

Deep-Learning-Image-Captioning - Implementing convolutional and recurrent neural networks in Keras to generate sentence descriptions of images
Deep Learning - Image Captioning with Convolutional and Recurrent Neural Nets ========================================================================
 23 Apr 6, 2022
23 Apr 6, 2022

Image captioning - Tensorflow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Introduction This neural system for image captioning is roughly based on the paper "Show, Attend and Tell: Neural Image Caption Generation with Visual
 749 Dec 28, 2022
749 Dec 28, 2022
Videocaptioning.pytorch - A simple implementation of video captioning
pytorch implementation of video captioning recommend installing pytorch and pyth
 2 Jan 1, 2022
2 Jan 1, 2022
Multilingual Image Captioning
Multilingual Image Captioning Authors: Bhavitvya Malik, Gunjan Chhablani Demo Link: https://huggingface.co/spaces/flax-community/multilingual-image-ca
 32 Nov 25, 2022
32 Nov 25, 2022

Learn how modern web applications and microservice architecture work as you complete a creative assignment
Micro-service Создание микросервиса Цель работы Познакомиться с механизмом работы современных веб-приложений и микросервисной архитектуры в процессе в
 1 Dec 19, 2021
1 Dec 19, 2021
TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
902 Nov 29, 2022

Code for the TPAMI paper: "Syntax Customized Video Captioning by Imitating Exemplar Sentences"
Syntax-Customized-Video-Captioning Code for the TPAMI paper: "Syntax Customized Video Captioning by Imitating Exemplar Sentences". This is my second w
 3 Dec 5, 2022
3 Dec 5, 2022

Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
10 Dec 4, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
 938 Dec 26, 2022
938 Dec 26, 2022
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022
Code for the paper "Controllable Video Captioning with an Exemplar Sentence"
SMCG Code for the paper "Controllable Video Captioning with an Exemplar Sentence" Introduction We investigate a novel and challenging task, namely con
10 Dec 4, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Image Captioning using CNN ,LSTM and Attention
Image Captioning using CNN ,LSTM and Attention This is a deeplearning model which tries to summarize an image into a text . Installation Install this
 1 Dec 16, 2021
1 Dec 16, 2021
A simple python oriented telegram bot to give out creative font style's
Font-Bot A simple python oriented telegram bot to give out creative font style's REQUIREMENTS tgcrypto pyrogram==1.2.9 Installation Fork this reposito
 4 Jan 30, 2022
4 Jan 30, 2022

Weakly Supervised Dense Event Captioning in Videos, i.e. generating multiple sentence descriptions for a video in a weakly-supervised manner.
WSDEC This is the official repo for our NeurIPS paper Weakly Supervised Dense Event Captioning in Videos. Description Repo directories ./: global conf
 96 Nov 1, 2022
96 Nov 1, 2022

Automatic Video Captioning Evaluation Metric --- EMScore
Automatic Video Captioning Evaluation Metric --- EMScore Overview For an illustration, EMScore can be computed as: Installation modify the encode_text
 17 Nov 28, 2022
17 Nov 28, 2022

Simple image captioning model
CLIP prefix captioning. Inference Notebook: 🥳 New: 🥳 Our technical papar is finally out! Official implementation for the paper "ClipCap: CLIP Prefix
 141 Nov 20, 2021
141 Nov 20, 2021
A transformer-based method for Healthcare Image Captioning in Vietnamese
vieCap4H Challenge 2021: A transformer-based method for Healthcare Image Captioning in Vietnamese This repo GitHub contains our solution for vieCap4H
 4 May 5, 2022
4 May 5, 2022
Machine-in-the-Loop Rewriting for Creative Image Captioning
Machine-in-the-Loop Rewriting for Creative Image Captioning Data Annotated sources of data used in the paper: Data Source URL Mohammed et al. Link Gor
 6 Jul 24, 2022
6 Jul 24, 2022

Styled text-to-drawing synthesis method. Featured at the 2021 NeurIPS Workshop on Machine Learning for Creativity and Design
Styled text-to-drawing synthesis method. Featured at the 2021 NeurIPS Workshop on Machine Learning for Creativity and Design
 247 Dec 23, 2022
247 Dec 23, 2022
Image captioning service for healthcare domains in Vietnamese using VLP
Image captioning service for healthcare domains in Vietnamese using VLP This service is a web service that provides image captioning services for heal
 2 Nov 4, 2021
2 Nov 4, 2021
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
 5.1k Jan 4, 2023
5.1k Jan 4, 2023
A Deep Learning based project for creating line art portraits.
ArtLine The main aim of the project is to create amazing line art portraits. Sounds Intresting,let's get to the pictures!! Model-(Smooth) Model-(Quali
 3.3k Jan 7, 2023
3.3k Jan 7, 2023
BeeRef — A Simple Reference Image Viewer
BeeRef — A Simple Reference Image Viewer BeeRef lets you quickly arrange your reference images and view them while you create. Its minimal interface i
 245 Dec 25, 2022
245 Dec 25, 2022
An Image Captioning codebase
An Image Captioning codebase This is a codebase for image captioning research. It supports: Self critical training from Self-critical Sequence Trainin
 1.1k Oct 18, 2021
1.1k Oct 18, 2021
Simple image captioning model - CLIP prefix captioning.
Simple image captioning model - CLIP prefix captioning.
688 Jan 4, 2023
The backend part of the simple password manager project made for the creative challenge.
SimplePasswordManagerBackend The backend part of the simple password manager project. Your task will be to showcase your creativity on our channel by
 5 Dec 28, 2021
5 Dec 28, 2021
Optimized code based on M2 for faster image captioning training
Transformer Captioning This repository contains the code for Transformer-based image captioning. Based on meshed-memory-transformer, we further optimi
16 Dec 16, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022
An unreferenced image captioning metric (ACL-21)
UMIC This repository provides an unferenced image captioning metric from our ACL 2021 paper UMIC: An Unreferenced Metric for Image Captioning via Cont
 14 Nov 20, 2022
14 Nov 20, 2022
Unofficial pytorch implementation for Self-critical Sequence Training for Image Captioning. and others.
An Image Captioning codebase This is a codebase for image captioning research. It supports: Self critical training from Self-critical Sequence Trainin
906 Jan 3, 2023

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022
improvement of CLIP features over the traditional resnet features on the visual question answering, image captioning, navigation and visual entailment tasks.
CLIP-ViL In our paper "How Much Can CLIP Benefit Vision-and-Language Tasks?", we show the improvement of CLIP features over the traditional resnet fea
 310 Dec 28, 2022
310 Dec 28, 2022

Python版OpenCVのTracking APIのサンプルです。DaSiamRPNアルゴリズムまで対応しています。
OpenCV-Object-Tracker-Sample Python版OpenCVのTracking APIのサンプルです。 Requirement opencv-contrib-python 4.5.3.56 or later Algorithm 2021/07/16時点でOpenCVには以
 36 Jan 1, 2023
36 Jan 1, 2023
Codes for paper "Towards Diverse Paragraph Captioning for Untrimmed Videos". CVPR 2021
Towards Diverse Paragraph Captioning for Untrimmed Videos This repository contains PyTorch implementation of our paper Towards Diverse Paragraph Capti
 61 Oct 11, 2022
61 Oct 11, 2022
Semi-Autoregressive Transformer for Image Captioning
Semi-Autoregressive Transformer for Image Captioning Requirements Python 3.6 Pytorch 1.6 Prepare data Please use git clone --recurse-submodules to clo
23 Dec 9, 2022

Source code for "MusCaps: Generating Captions for Music Audio" (IJCNN 2021)
MusCaps: Generating Captions for Music Audio Ilaria Manco1 2, Emmanouil Benetos1, Elio Quinton2, Gyorgy Fazekas1 1 Queen Mary University of London, 2
 57 Dec 7, 2022
57 Dec 7, 2022
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
5.1k Dec 26, 2022
Syntax-Aware Action Targeting for Video Captioning
Syntax-Aware Action Targeting for Video Captioning Code for SAAT from "Syntax-Aware Action Targeting for Video Captioning" (Accepted to CVPR 2020). Th
 59 Oct 13, 2022
59 Oct 13, 2022

Diverse Image Captioning with Context-Object Split Latent Spaces (NeurIPS 2020)
Diverse Image Captioning with Context-Object Split Latent Spaces This repository is the PyTorch implementation of the paper: Diverse Image Captioning
 34 Nov 21, 2022
34 Nov 21, 2022
Code for Multiple Instance Active Learning for Object Detection, CVPR 2021
MI-AOD Language: 简体中文 | English Introduction This is the code for Multiple Instance Active Learning for Object Detection (The PDF is not available tem
 269 Dec 21, 2022
269 Dec 21, 2022

Code for Multiple Instance Active Learning for Object Detection, CVPR 2021
Language: 简体中文 | English Introduction This is the code for Multiple Instance Active Learning for Object Detection, CVPR 2021. Installation A Linux pla
269 Dec 21, 2022
MyPaint is a simple drawing and painting program that works well with Wacom-style graphics tablets.
MyPaint A fast and dead-simple painting app for artists Features Infinite canvas Extremely configurable brushes Distraction-free fullscreen mode Exten
 2.3k Jan 1, 2023
2.3k Jan 1, 2023
An Analysis Toolkit for Natural Language Generation (Translation, Captioning, Summarization, etc.)
VizSeq is a Python toolkit for visual analysis on text generation tasks like machine translation, summarization, image captioning, speech translation
310 Feb 1, 2021
An Analysis Toolkit for Natural Language Generation (Translation, Captioning, Summarization, etc.)
VizSeq is a Python toolkit for visual analysis on text generation tasks like machine translation, summarization, image captioning, speech translation
409 Oct 28, 2022