37 Repositories
Python namuwiki-corpus Libraries
Finally, some decent sample sentences
tts-dataset-prompts This repository aims to be a decent set of sentences for people looking to clone their own voices (e.g. using Tacotron 2). Each se
 19 Dec 13, 2022
19 Dec 13, 2022
File-based TF-IDF: Calculates keywords in a document, using a word corpus.
File-based TF-IDF Calculates keywords in a document, using a word corpus. Why? Because I found myself with hundreds of plain text files, with no way t
 1 Feb 11, 2022
1 Feb 11, 2022
Gold standard corpus annotated with verb-preverb connections for Hungarian.
Hungarian Preverb Corpus A gold standard corpus manually annotated with verb-preverb connections for Hungarian. corpus The corpus consist of the follo
 3 Jan 27, 2022
3 Jan 27, 2022
A notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository
We provide a notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository. The notebook also shows how to segment the corpus using BPE tokenization which can be used to train an English-Hindi MT System.
 9 Oct 13, 2022
9 Oct 13, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss This is official implement of "
 87 Dec 24, 2022
87 Dec 24, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
 26 Jan 16, 2022
26 Jan 16, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
118 Jan 6, 2023
YACLC - Yet Another Chinese Learner Corpus
汉语学习者文本多维标注数据集YACLC V1.0 中文 | English 汉语学习者文本多维标注数据集(Yet Another Chinese Learner
 47 Dec 15, 2022
47 Dec 15, 2022
Crawl BookCorpus
These are scripts to reproduce BookCorpus by yourself.
 590 Jan 3, 2023
590 Jan 3, 2023
Chatbot in 200 lines of code using TensorLayer
Seq2Seq Chatbot This is a 200 lines implementation of Twitter/Cornell-Movie Chatbot, please read the following references before you read the code: Pr
 820 Dec 17, 2022
820 Dec 17, 2022
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration This is the official repository for the EMNLP 2021 long pa
 70 Dec 11, 2022
70 Dec 11, 2022

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022
AWS documentation corpus for zero-shot open-book question answering.
aws-documentation We present the AWS documentation corpus, an open-book QA dataset, which contains 25,175 documents along with 100 matched questions a
 2 Jul 7, 2022
2 Jul 7, 2022

Video Corpus Moment Retrieval with Contrastive Learning (SIGIR 2021)
Video Corpus Moment Retrieval with Contrastive Learning PyTorch implementation for the paper "Video Corpus Moment Retrieval with Contrastive Learning"
 42 Dec 29, 2022
42 Dec 29, 2022
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL, and utterance id
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL
 3 Dec 26, 2022
3 Dec 26, 2022

SimplEx - Explaining Latent Representations with a Corpus of Examples
SimplEx - Explaining Latent Representations with a Corpus of Examples Code Author: Jonathan Crabbé ([email protected]) This repository contains the imp
 14 Dec 15, 2022
14 Dec 15, 2022
PASTRIE: A Corpus of Prepositions Annotated with Supersense Tags in Reddit International English
PASTRIE Official release of the corpus described in the paper: Michael Kranzlein, Emma Manning, Siyao Peng, Shira Wein, Aryaman Arora, and Nathan Schn
 4 Dec 2, 2021
4 Dec 2, 2021
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss This is official implement of "
87 Dec 24, 2022
A cross-document event and entity coreference resolution system, trained and evaluated on the ECB+ corpus.
A Comprehensive Comparison of Word Embeddings in Event & Entity Coreference Resolution. Introduction This repo contains experimental code derived from
 2 May 9, 2022
2 May 9, 2022
![[2021 MultiMedia] CONQUER: Contextual Query-aware Ranking for Video Corpus Moment Retrieval](https://github.com/houzhijian/CONQUER/raw/master/figures/problem_definition.png)
[2021 MultiMedia] CONQUER: Contextual Query-aware Ranking for Video Corpus Moment Retrieval
CONQUER: Contexutal Query-aware Ranking for Video Corpus Moment Retreival PyTorch implementation of CONQUER: Contexutal Query-aware Ranking for Video
 23 Dec 26, 2022
23 Dec 26, 2022
NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking
pretrain4ir_tutorial NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking 用作NLPIR实验室, Pre-training
 12 Apr 7, 2022
12 Apr 7, 2022
SinglepassTextCluster, an TextCluster tools based on Singlepass cluster algorithm that use tfidf vector and doc2vec,which can be used for individual real-time corpus cluster task。基于single-pass算法思想的自动文本聚类小组件,内置tfidf和doc2vec两种文本向量方法,可自动输出聚类数目、类簇文档集合和簇类大小,用于自有实时数据的聚类任务。
项目的背景 SinglepassTextCluster, an TextCluster tool based on Singlepass cluster algorithm that use tfidf vector and doc2vec,which can be used for individ
 34 Dec 18, 2022
34 Dec 18, 2022
Official code of our work, AVATAR: A Parallel Corpus for Java-Python Program Translation.
AVATAR Official code of our work, AVATAR: A Parallel Corpus for Java-Python Program Translation. AVATAR stands for jAVA-pyThon progrAm tRanslation. AV
 26 Dec 3, 2022
26 Dec 3, 2022
This repository contains the code for "Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP".
Self-Diagnosis and Self-Debiasing This repository contains the source code for Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based
 62 Dec 12, 2022
62 Dec 12, 2022
문장단위로 분절된 나무위키 데이터셋. Releases에서 다운로드 받거나, tfds-korean을 통해 다운로드 받으세요.
Namuwiki corpus 문장단위로 미리 분절된 나무위키 코퍼스. 목적이 LM등에서 사용하기 위한 데이터셋이라, 링크/이미지/테이블 등등이 잘려있습니다. 문장 단위 분절은 kss를 활용하였습니다. 라이선스는 나무위키에 명시된 바와 같이 CC BY-NC-SA 2.0
 16 Apr 2, 2022
16 Apr 2, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022

Official repository for "Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems"
Action-Based Conversations Dataset (ABCD) This respository contains the code and data for ABCD (Chen et al., 2021) Introduction Whereas existing goal-
 49 Oct 9, 2022
49 Oct 9, 2022

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022
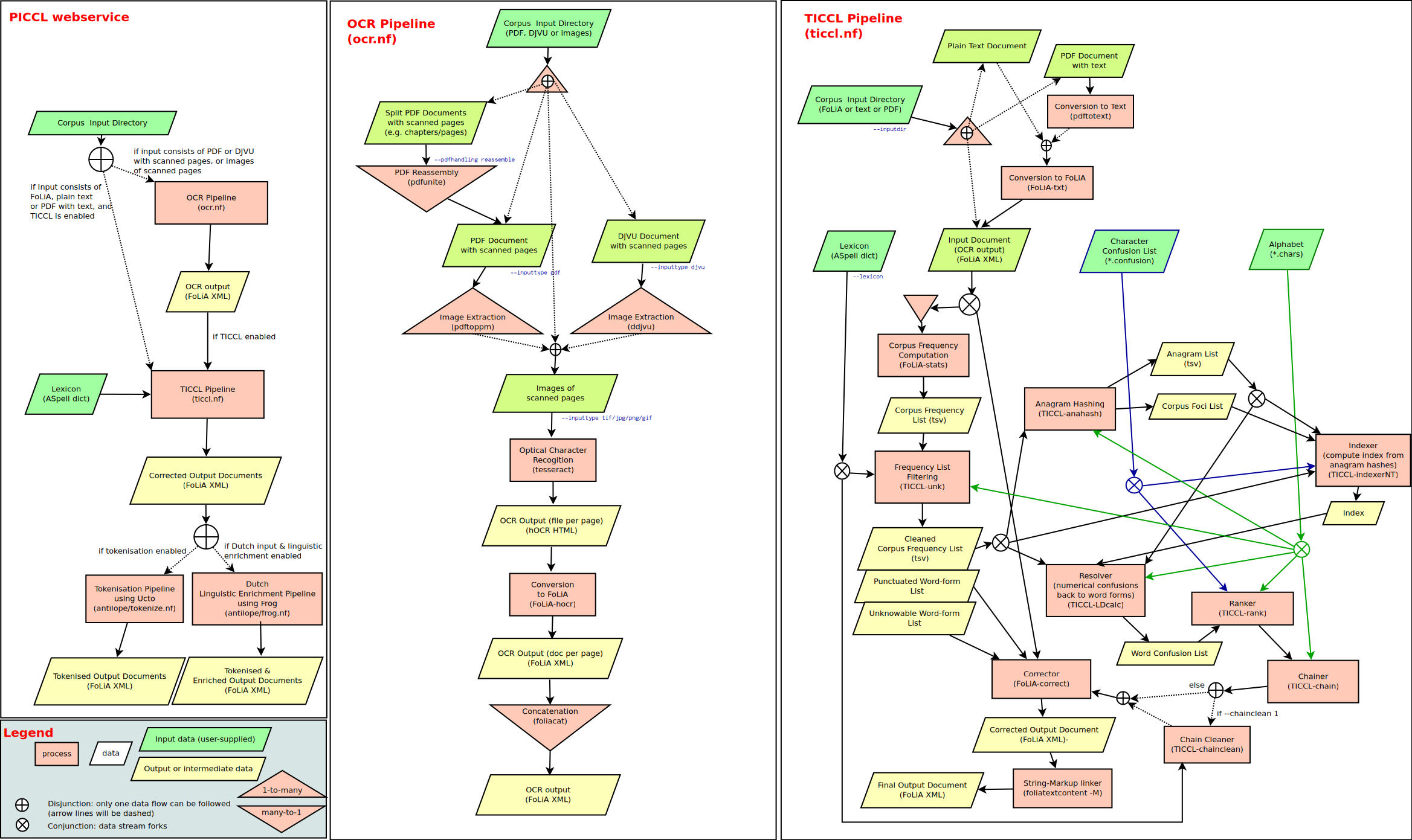
A set of workflows for corpus building through OCR, post-correction and normalisation
PICCL: Philosophical Integrator of Computational and Corpus Libraries PICCL offers a workflow for corpus building and builds on a variety of tools. Th
 41 Dec 27, 2022
41 Dec 27, 2022

Python tools for the corpus analysis of popular music.
CATCHY Corpus Analysis Tools for Computational Hook discovery Python tools for the corpus analysis of popular music recordings. The tools can be used
 20 Aug 20, 2022
20 Aug 20, 2022
Python library for handling audio datasets.
AUDIOMATE Audiomate is a library for easy access to audio datasets. It provides the datastructures for accessing/loading different datasets in a gener
 121 Nov 27, 2022
121 Nov 27, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
227 Jan 2, 2023
Colibri core is an NLP tool as well as a C++ and Python library for working with basic linguistic constructions such as n-grams and skipgrams (i.e patterns with one or more gaps, either of fixed or dynamic size) in a quick and memory-efficient way. At the core is the tool ``colibri-patternmodeller`` whi ch allows you to build, view, manipulate and query pattern models.
Colibri Core by Maarten van Gompel, [email protected], Radboud University Nijmegen Licensed under GPLv3 (See http://www.gnu.org/licenses/gpl-3.0.html
 122 Nov 17, 2022
122 Nov 17, 2022