173 Repositories
Python speaker-encoder Libraries
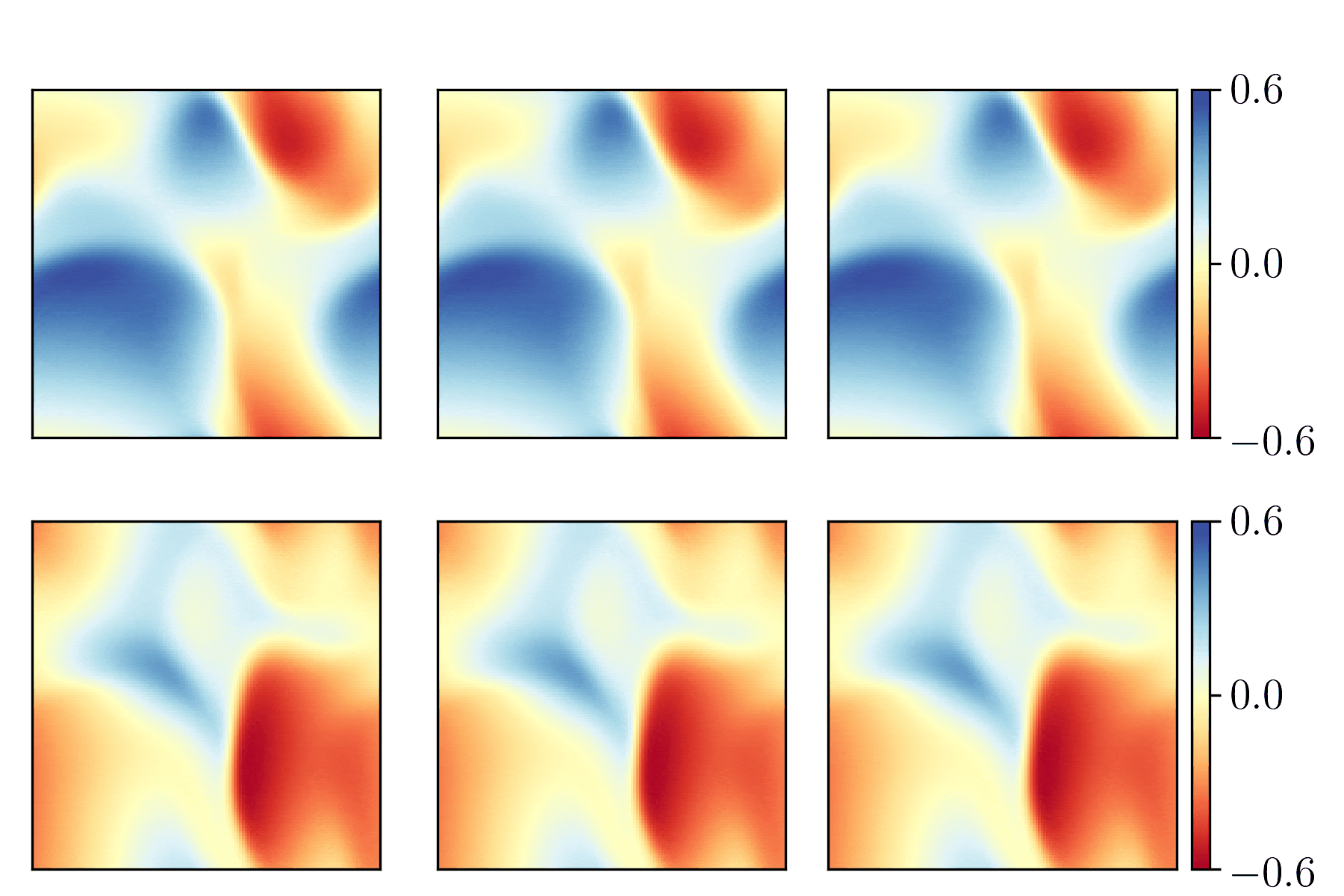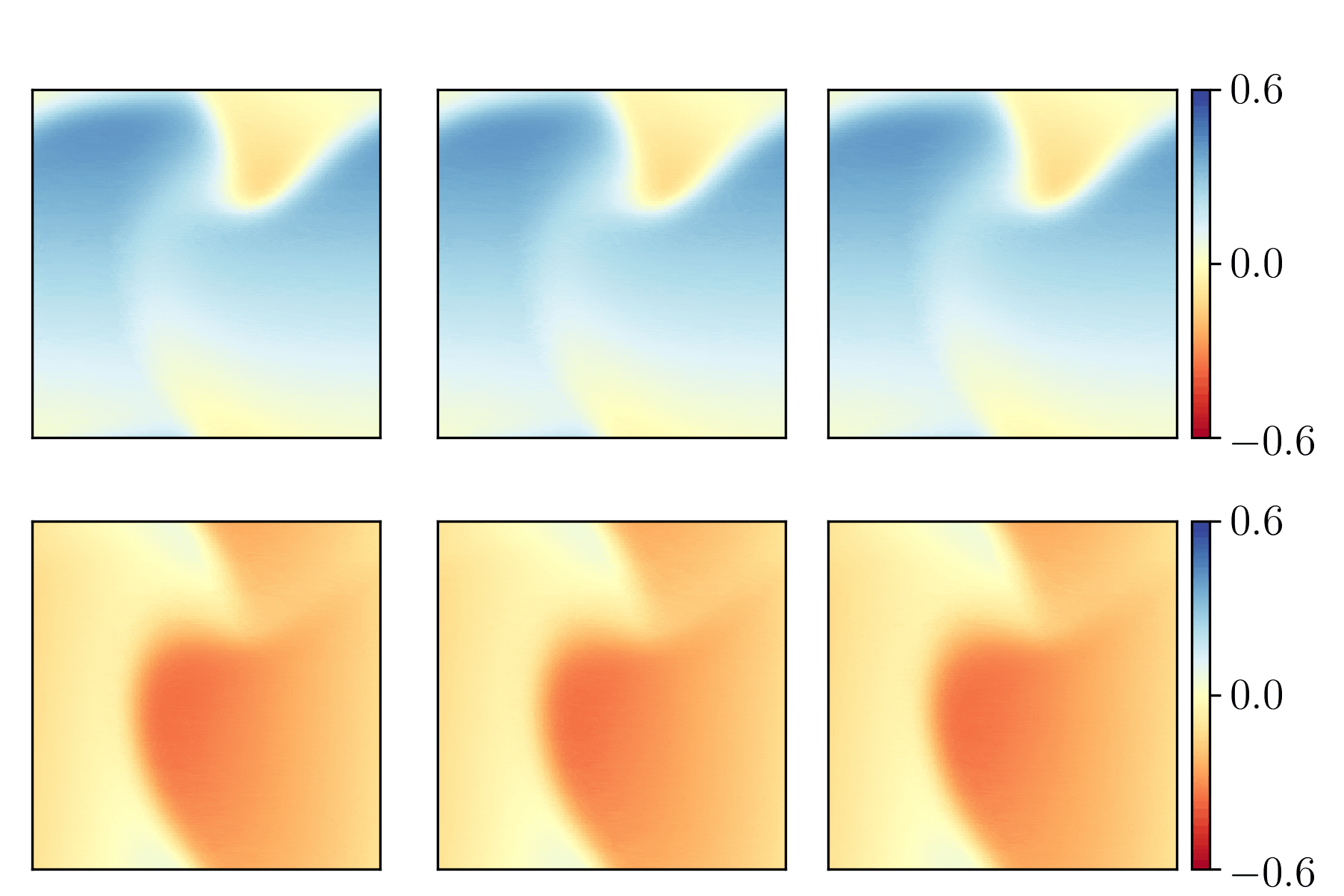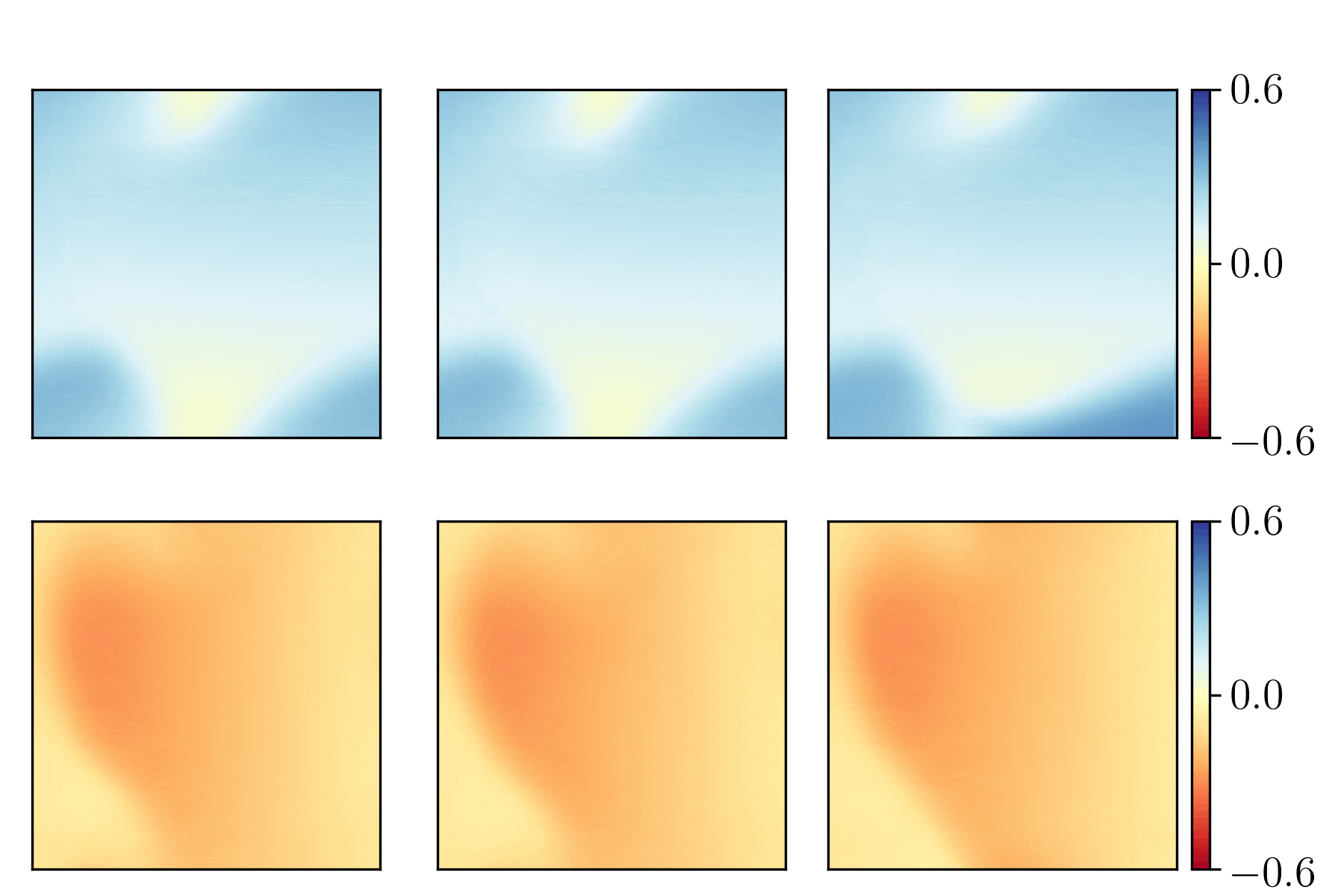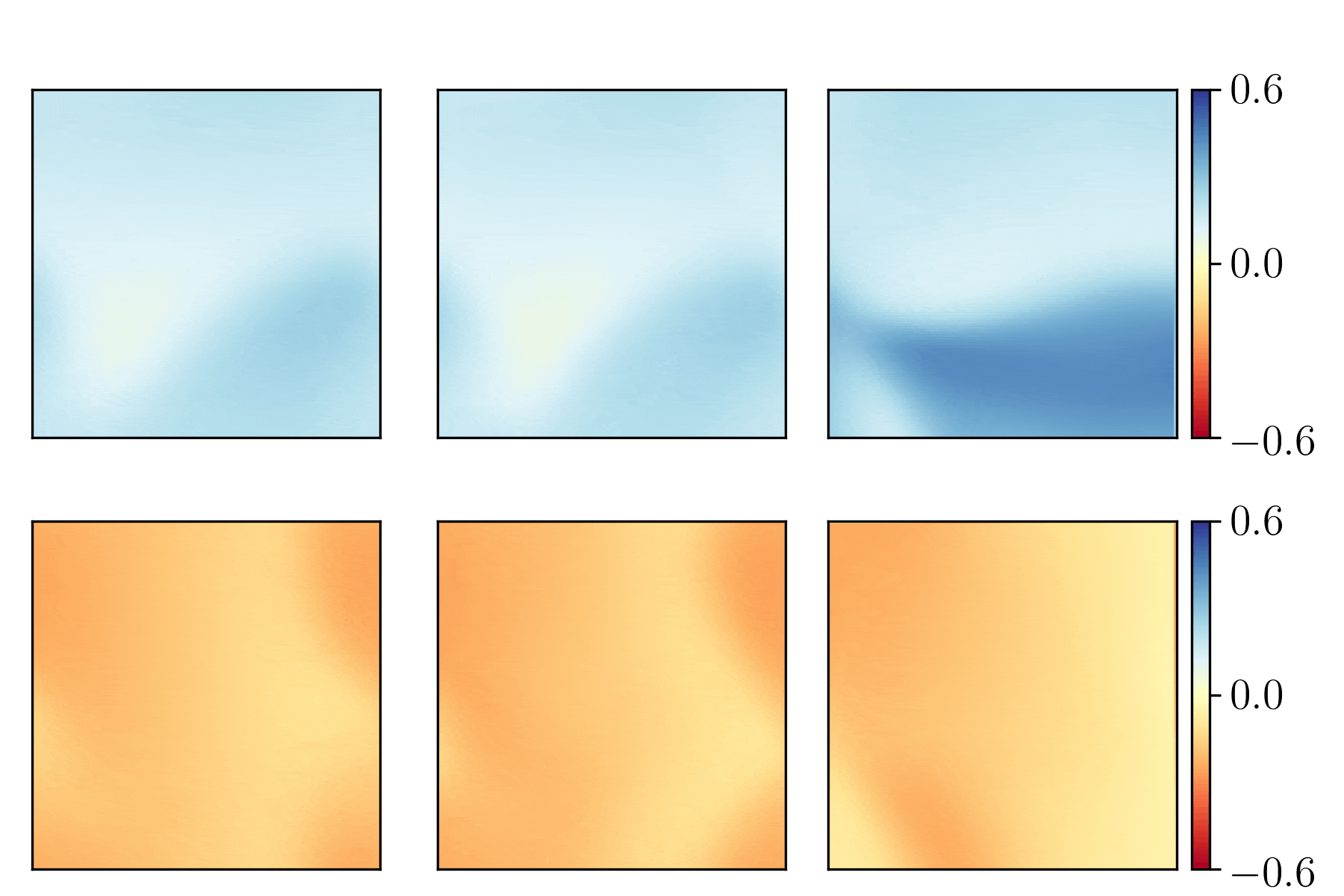
Physics-informed convolutional-recurrent neural networks for solving spatiotemporal PDEs
PhyCRNet Physics-informed convolutional-recurrent neural networks for solving spatiotemporal PDEs Paper link: [ArXiv] By: Pu Ren, Chengping Rao, Yang
 11 Aug 23, 2022
11 Aug 23, 2022

Pytorch implementation of "Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling"
RNN-for-Joint-NLU Pytorch implementation of "Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling"
 194 Dec 28, 2022
194 Dec 28, 2022

SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
 24 May 20, 2022
24 May 20, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
 237 Jan 2, 2023
237 Jan 2, 2023
Code and data form the paper BERT Got a Date: Introducing Transformers to Temporal Tagging
BERT Got a Date: Introducing Transformers to Temporal Tagging Satya Almasian*, Dennis Aumiller*, and Michael Gertz Heidelberg University Contact us vi
 54 Dec 4, 2022
54 Dec 4, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022

Code for the paper "Adversarial Generator-Encoder Networks"
This repository contains code for the paper "Adversarial Generator-Encoder Networks" (AAAI'18) by Dmitry Ulyanov, Andrea Vedaldi, Victor Lempitsky. Pr
 279 Jun 26, 2022
279 Jun 26, 2022

Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
 187 Jan 6, 2023
187 Jan 6, 2023
Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
185 Jan 1, 2023

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022
DeepLabv3+:Encoder-Decoder with Atrous Separable Convolution语义分割模型在tensorflow2当中的实现
DeepLabv3+:Encoder-Decoder with Atrous Separable Convolution语义分割模型在tensorflow2当中的实现 目录 性能情况 Performance 所需环境 Environment 注意事项 Attention 文件下载 Download
 31 Nov 25, 2022
31 Nov 25, 2022
![[ICCV 2021] Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation](https://github.com/ziniuwan/maed/raw/master/doc/figs/net_arch.png)
[ICCV 2021] Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation
MAED: Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation Getting Started Our codes are implemented and tested with pyth
 176 Dec 15, 2022
176 Dec 15, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022

GAN encoders in PyTorch that could match PGGAN, StyleGAN v1/v2, and BigGAN. Code also integrates the implementation of these GANs.
MTV-TSA: Adaptable GAN Encoders for Image Reconstruction via Multi-type Latent Vectors with Two-scale Attentions. This is the official code release fo
 37 Dec 24, 2022
37 Dec 24, 2022
Look Who’s Talking: Active Speaker Detection in the Wild
Look Who's Talking: Active Speaker Detection in the Wild Dependencies pip install -r requirements.txt In addition to the Python dependencies, ffmpeg
 60 Dec 8, 2022
60 Dec 8, 2022

Let Xiao Ai speakers control third-party devices
A stupid way to extend miot/xiaoai. Demo for Panasonic Bath Bully FV-RB20VL1 逆向 Panasonic Smart China,获得控制浴霸的请求信息(HTTP 请求),详见 apps/panasonic.py; 2. 通过
 14 Jul 7, 2022
14 Jul 7, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
 20 Dec 29, 2022
20 Dec 29, 2022

An application that maps an image of a LaTeX math equation to LaTeX code.
Convert images of LaTex math equations into LaTex code.
 1.3k Jan 6, 2023
1.3k Jan 6, 2023
PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Dec 30, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022

A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval project page | arXiv | webvid-data Repository containing the code,
 225 Dec 25, 2022
225 Dec 25, 2022
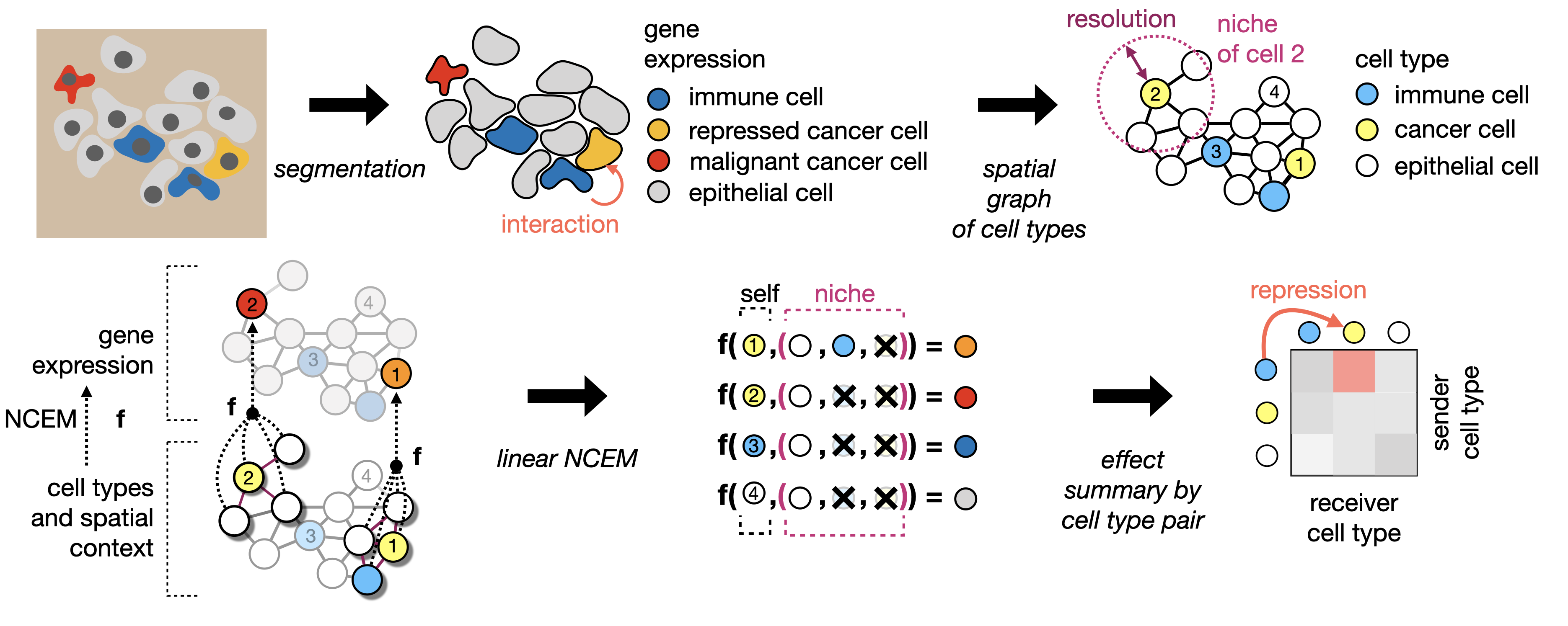
Learning cell communication from spatial graphs of cells
ncem Features Repository for the manuscript Fischer, D. S., Schaar, A. C. and Theis, F. Learning cell communication from spatial graphs of cells. 2021
 77 Dec 30, 2022
77 Dec 30, 2022

PyTorch implementation of Densely Connected Time Delay Neural Network
Densely Connected Time Delay Neural Network PyTorch implementation of Densely Connected Time Delay Neural Network (D-TDNN) in our paper "Densely Conne
 64 Oct 11, 2022
64 Oct 11, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
What is MUSE? MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (16 languages) of Universal Sentence Encoder (USE). MUS
47 Sep 5, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023

Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
 12.6k Jan 9, 2023
12.6k Jan 9, 2023

Uncertainty-aware Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving
SalsaNext: Fast, Uncertainty-aware Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving Abstract In this paper, we introduce SalsaNext f
 308 Jan 4, 2023
308 Jan 4, 2023

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022

Non-Official Pytorch implementation of "Face Identity Disentanglement via Latent Space Mapping" https://arxiv.org/abs/2005.07728 Using StyleGAN2 instead of StyleGAN
Face Identity Disentanglement via Latent Space Mapping - Implement in pytorch with StyleGAN 2 Description Pytorch implementation of the paper Face Ide
 58 Dec 24, 2022
58 Dec 24, 2022
A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval (arXiv) Repository to contain the code, models, data for end-to-end
225 Dec 25, 2022
A Telegram bot to convert videos into x265/x264 format via ffmpeg.
Video Encoder Bot A Telegram bot to convert videos into x265/x264 format via ffmpeg. Configuration Add values in environment variables or add them in
 82 Jan 3, 2023
82 Jan 3, 2023
Collaborative variational bandwidth auto-encoder (VBAE) for recommender systems.
Collaborative Variational Bandwidth Auto-encoder The codes are associated with the following paper: Collaborative Variational Bandwidth Auto-encoder f
 14 Dec 11, 2022
14 Dec 11, 2022
Simple GUI menu for micropython using a rotary encoder and basic display.
Micropython encoder based menu This is a simple menu system written in micropython. It uses a switch, a rotary encoder and an OLED display.
 80 Jan 7, 2023
80 Jan 7, 2023
simplejson is a simple, fast, extensible JSON encoder/decoder for Python
simplejson simplejson is a simple, fast, complete, correct and extensible JSON http://json.org encoder and decoder for Python 3.3+ with legacy suppo
 1.5k Jan 5, 2023
1.5k Jan 5, 2023
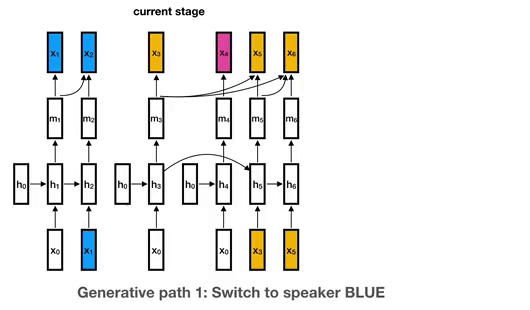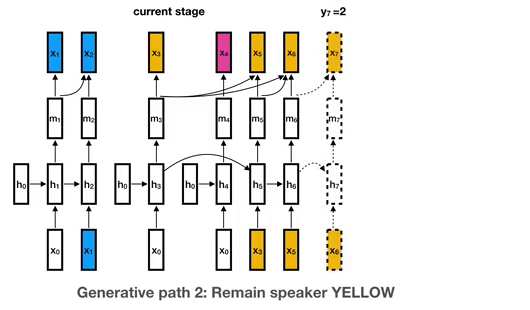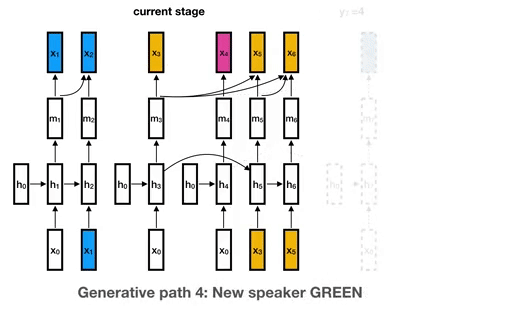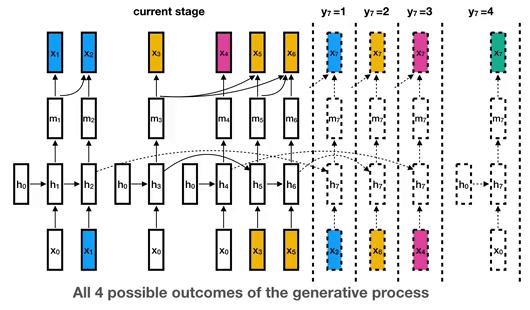
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
 1000 Apr 19, 2021
1000 Apr 19, 2021
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model Edresson Casanova, Christopher Shulby, Eren Gölge, Nicolas Michael Müller, Frede
 92 Dec 9, 2022
92 Dec 9, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
 6.5k Jan 8, 2023
6.5k Jan 8, 2023

Official Implementation for "ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement" https://arxiv.org/abs/2104.02699
ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement Recently, the power of unconditional image synthesis has significantly advanced th
 967 Jan 4, 2023
967 Jan 4, 2023
Official implementation for Likelihood Regret: An Out-of-Distribution Detection Score For Variational Auto-encoder at NeurIPS 2020
Likelihood-Regret Official implementation of Likelihood Regret: An Out-of-Distribution Detection Score For Variational Auto-encoder at NeurIPS 2020. T
 33 Oct 12, 2022
33 Oct 12, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
《LXMERT: Learning Cross-Modality Encoder Representations from Transformers》(EMNLP 2020)
The Most Important Thing. Our code is developed based on: LXMERT: Learning Cross-Modality Encoder Representations from Transformers
 53 Dec 16, 2022
53 Dec 16, 2022

Official PyTorch implementation for Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers, a novel method to visualize any Transformer-based network. Including examples for DETR, VQA.
PyTorch Implementation of Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers 1 Using Colab Please notic
 489 Jan 7, 2023
489 Jan 7, 2023
Understanding and Improving Encoder Layer Fusion in Sequence-to-Sequence Learning (ICLR 2021)
Understanding and Improving Encoder Layer Fusion in Sequence-to-Sequence Learning (ICLR 2021) Citation Please cite as: @inproceedings{liu2020understan
 22 Nov 25, 2022
22 Nov 25, 2022
A selectional auto-encoder approach for document image binarization
The code of this repository was used for the following publication. If you find this code useful please cite our paper: @article{Gallego2019, title =
 89 Nov 18, 2022
89 Nov 18, 2022
kaldi-asr/kaldi is the official location of the Kaldi project.
Kaldi Speech Recognition Toolkit To build the toolkit: see ./INSTALL. These instructions are valid for UNIX systems including various flavors of Linux
 12.3k Jan 5, 2023
12.3k Jan 5, 2023
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we can speed-up training/inference progress, optimizer further by using fake-quantize aware and pruning, make TTS models can be run faster than real-time and be able to deploy on mobile devices or embedded systems.
 3k Jan 4, 2023
3k Jan 4, 2023

QT Py Media Knob using rotary encoder & neopixel ring
QTPy-Knob QT Py USB Media Knob using rotary encoder & neopixel ring The QTPy-Knob features: Media knob for volume up/down/mute with "qtpy-knob.py" Cir
 56 Dec 30, 2022
56 Dec 30, 2022
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
 496 Dec 31, 2022
496 Dec 31, 2022
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
492 Dec 28, 2022
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
Sockeye This package contains the Sockeye project, an open-source sequence-to-sequence framework for Neural Machine Translation based on Apache MXNet
986 Feb 17, 2021
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
2.1k Dec 31, 2022

TransGAN: Two Transformers Can Make One Strong GAN
[Preprint] "TransGAN: Two Transformers Can Make One Strong GAN", Yifan Jiang, Shiyu Chang, Zhangyang Wang
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
Sockeye This package contains the Sockeye project, an open-source sequence-to-sequence framework for Neural Machine Translation based on Apache MXNet
1.1k Dec 27, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
1.5k Dec 26, 2022
simplejson is a simple, fast, extensible JSON encoder/decoder for Python
simplejson simplejson is a simple, fast, complete, correct and extensible JSON http://json.org encoder and decoder for Python 3.3+ with legacy suppo
1.5k Dec 31, 2022
Ultra fast JSON decoder and encoder written in C with Python bindings
UltraJSON UltraJSON is an ultra fast JSON encoder and decoder written in pure C with bindings for Python 3.6+. Install with pip: $ python -m pip insta
 3.9k Jan 2, 2023
3.9k Jan 2, 2023
Transformer-based Text Auto-encoder (T-TA) using TensorFlow 2.
T-TA (Transformer-based Text Auto-encoder) This repository contains codes for Transformer-based Text Auto-encoder (T-TA, paper: Fast and Accurate Deep
 13 Dec 13, 2022
13 Dec 13, 2022
Ultra fast JSON decoder and encoder written in C with Python bindings
UltraJSON UltraJSON is an ultra fast JSON encoder and decoder written in pure C with bindings for Python 3.6+. Install with pip: $ python -m pip insta
3.9k Dec 31, 2022
Yet Another Sequence Encoder - Encode sequences to vector of vector in python !
Yase Yet Another Sequence Encoder - encode sequences to vector of vectors in python ! Why Yase ? Yase enable you to encode any sequence which can be r
 12 Aug 19, 2021
12 Aug 19, 2021