1726 Repositories
Python text-style-transfer-benchmark Libraries
py-trans is a Free Python library for translate text into different languages.
Free Python library to translate text into different languages.
 13 Aug 27, 2022
13 Aug 27, 2022
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
 29 Dec 20, 2022
29 Dec 20, 2022
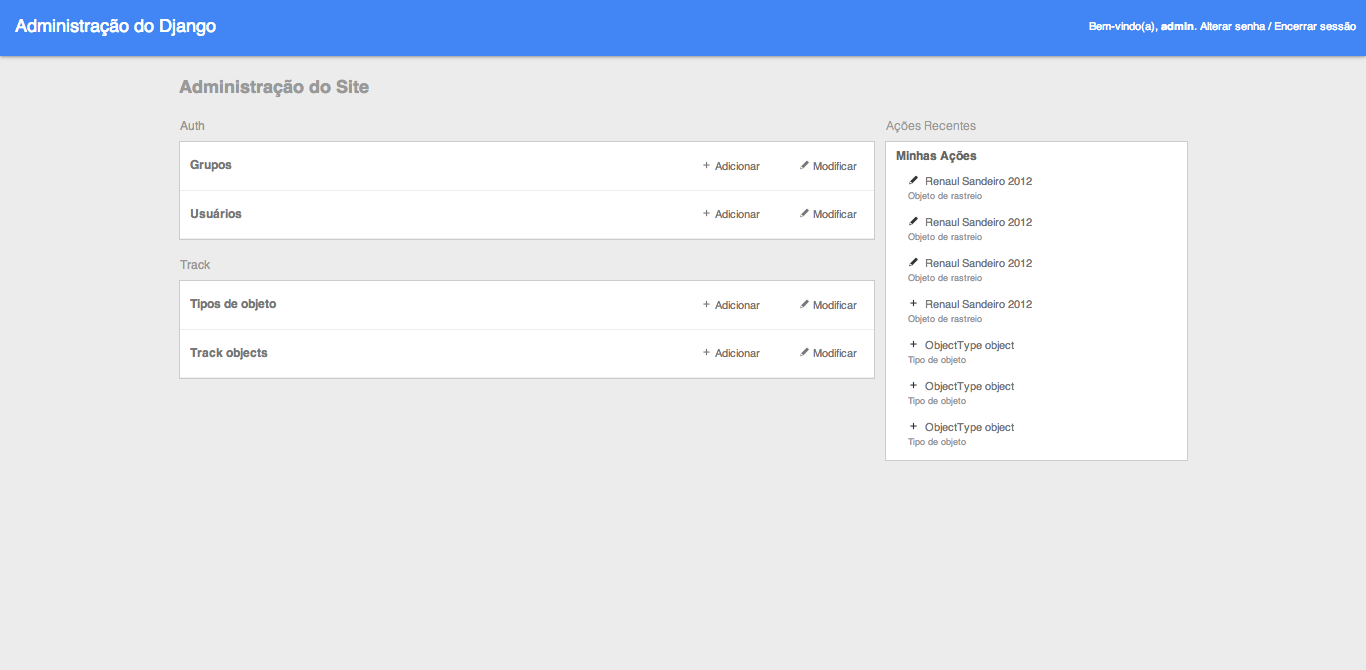
A new style for Django admin
Djamin Djamin a new and clean styles for Django admin based in Google projects styles. Quick start Install djamin: pip install -e git://github.com/her
 236 Dec 15, 2022
236 Dec 15, 2022

This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking".
SCT This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking" The spatial-channel Transformer (SCT) enhan
 27 Nov 23, 2022
27 Nov 23, 2022
A new style for Django admin
Djamin Djamin a new and clean styles for Django admin based in Google projects styles. Quick start Install djamin: pip install -e git://github.com/her
236 Dec 15, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022

Phy-Q: A Benchmark for Physical Reasoning
Phy-Q: A Benchmark for Physical Reasoning Cheng Xue*, Vimukthini Pinto*, Chathura Gamage* Ekaterina Nikonova, Peng Zhang, Jochen Renz School of Comput
 29 Dec 19, 2022
29 Dec 19, 2022
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
 19 Oct 28, 2022
19 Oct 28, 2022
`.](https://user-images.githubusercontent.com/4941909/132251464-0f6c48b2-f6ca-4ef7-9c76-39a78fbdd67c.png)
A Sublime Text plugin that displays inline images for single-line comments formatted like `// `.
Inline Images Sometimes ASCII art is not enough. Sometimes an image says more than a thousand words. This Sublime Text plugin can display images inlin
 8 Jul 1, 2022
8 Jul 1, 2022
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
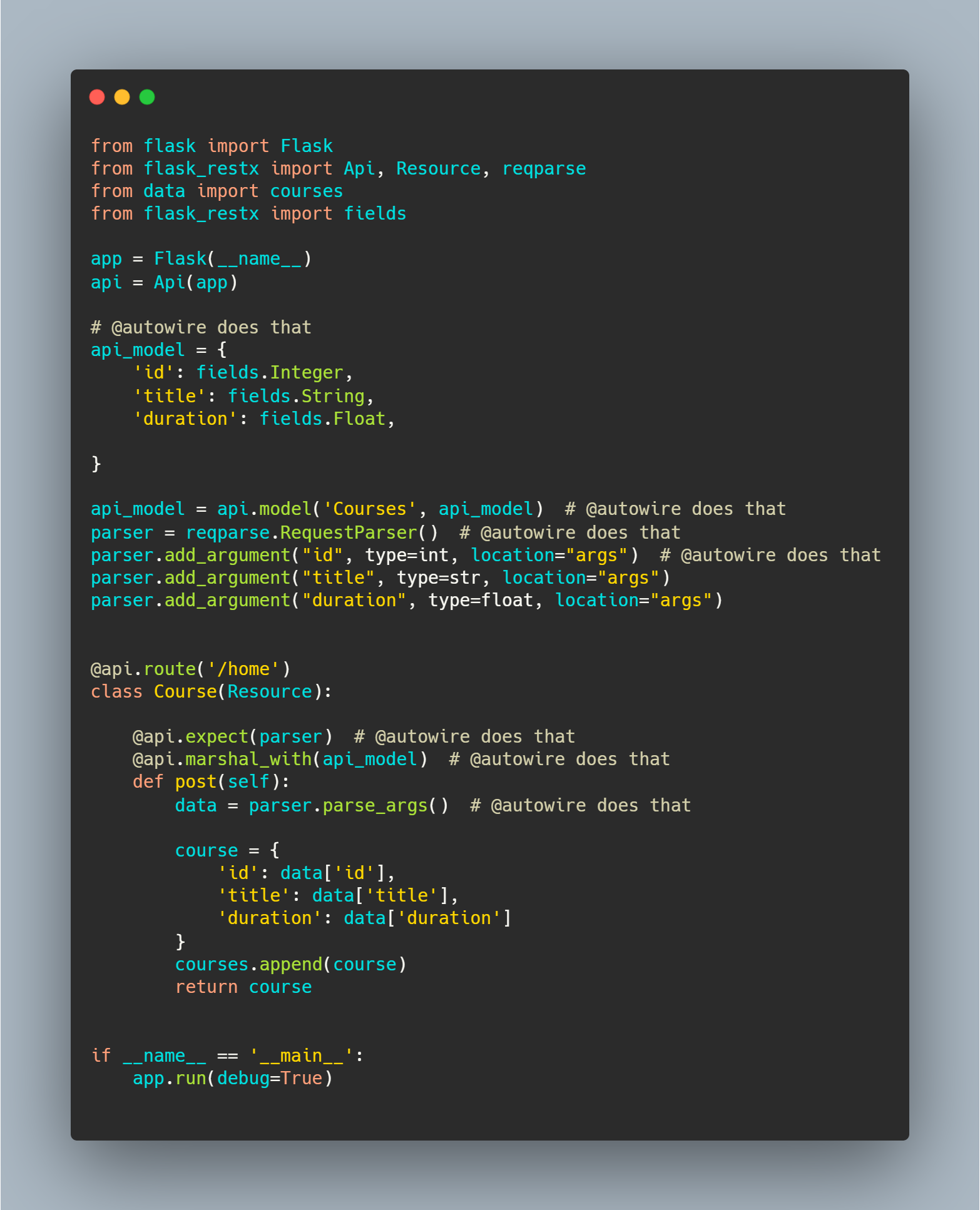
A Fast API style support for Flask. Gives you MyPy types with the flexibility of flask
Flask-Fastx Flask-Fastx is a Fast API style support for Flask. It Gives you MyPy types with the flexibility of flask. Compatibility Flask-Fastx requir
 18 Nov 26, 2022
18 Nov 26, 2022
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
ood-text-emnlp Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them" Files fine_tune.py is used to finetune the GPT-2 mo
19 Oct 28, 2022
Related resources for our EMNLP 2021 paper Plan-then-Generate: Controlled Data-to-Text Generation via Planning
Plan-then-Generate: Controlled Data-to-Text Generation via Planning Authors: Yixuan Su, David Vandyke, Sihui Wang, Yimai Fang, and Nigel Collier Code
 61 Jan 3, 2023
61 Jan 3, 2023

My published benchmark for a Kaggle Simulations Competition
Lux AI Working Title Bot Please refer to the Kaggle notebook for the comment section. The comment section contains my explanation on my code structure
 29 Aug 22, 2022
29 Aug 22, 2022

An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix
An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix, with glyphs based on cwTeXFangSong. The font is optimised fo
 98 Jan 7, 2023
98 Jan 7, 2023

Feed forward VQGAN-CLIP model, where the goal is to eliminate the need for optimizing the latent space of VQGAN for each input prompt
Feed forward VQGAN-CLIP model, where the goal is to eliminate the need for optimizing the latent space of VQGAN for each input prompt. This is done by
 135 Dec 30, 2022
135 Dec 30, 2022
Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet.
Sonnet finder Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet. Usage This is a Python scrip
 11 Sep 25, 2022
11 Sep 25, 2022
Telegram bot to extract text from image
OCR Bot @Image_To_Text_OCR_Bot A star ⭐ from you means a lot to us! Telegram bot to extract text from image Usage Deploy to Heroku Tap on above button
 25 Nov 24, 2022
25 Nov 24, 2022

Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
 105 Jan 3, 2023
105 Jan 3, 2023
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Text-AutoAugment (TAA) This repository contains the code for our paper Text AutoAugment: Learning Compositional Augmentation Policy for Text Classific
105 Jan 3, 2023
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
 23 Nov 30, 2022
23 Nov 30, 2022
Tutorial to pretrain & fine-tune a 🤗 Flax T5 model on a TPUv3-8 with GCP
Pretrain and Fine-tune a T5 model with Flax on GCP This tutorial details how pretrain and fine-tune a FlaxT5 model from HuggingFace using a TPU VM ava
 41 Nov 18, 2022
41 Nov 18, 2022
Python lib for Simple PDF text extraction
Python lib for Simple PDF text extraction
 651 Jan 1, 2023
651 Jan 1, 2023

This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Technique for Text Classification
The baseline code is for EDA: Easy Data Augmentation techniques for boosting performance on text classification tasks
 81 Dec 9, 2022
81 Dec 9, 2022
Model Quantization Benchmark
MQBench Update V0.0.2 Fix academic prepare setting. More deployable prepare process. Fix setup.py. Fix deploy on SNPE. Fix convert_deploy bug. Add Qua
 500 Jan 6, 2023
500 Jan 6, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that data.
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that
 29 Aug 9, 2022
29 Aug 9, 2022

Generate text line images for training deep learning OCR model (e.g. CRNN)
Generate text line images for training deep learning OCR model (e.g. CRNN)
 532 Jan 6, 2023
532 Jan 6, 2023
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
 30 Dec 12, 2022
30 Dec 12, 2022

Python 3 patcher for Sublime Text v4107-4114 Windows x64
sublime-text-4-patcher Python 3 patcher for Sublime Text v4107-4114 Windows x64 Credits for signatures and patching logic goes to https://github.com/l
 187 Dec 27, 2022
187 Dec 27, 2022

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022
A bot can be used to broadcast your messages ( Text & Media ) to the Subscribers
Broadcast Bot A Telegram bot to send messages and medias to the subscribers directly through bot. Authorized users of the bot can send messages (Texts
 8 Oct 21, 2022
8 Oct 21, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
Mail classification with tensorflow and MS Exchange Server (ham or spam).
Mail classification with tensorflow and MS Exchange Server (ham or spam).
 1 Sep 11, 2021
1 Sep 11, 2021
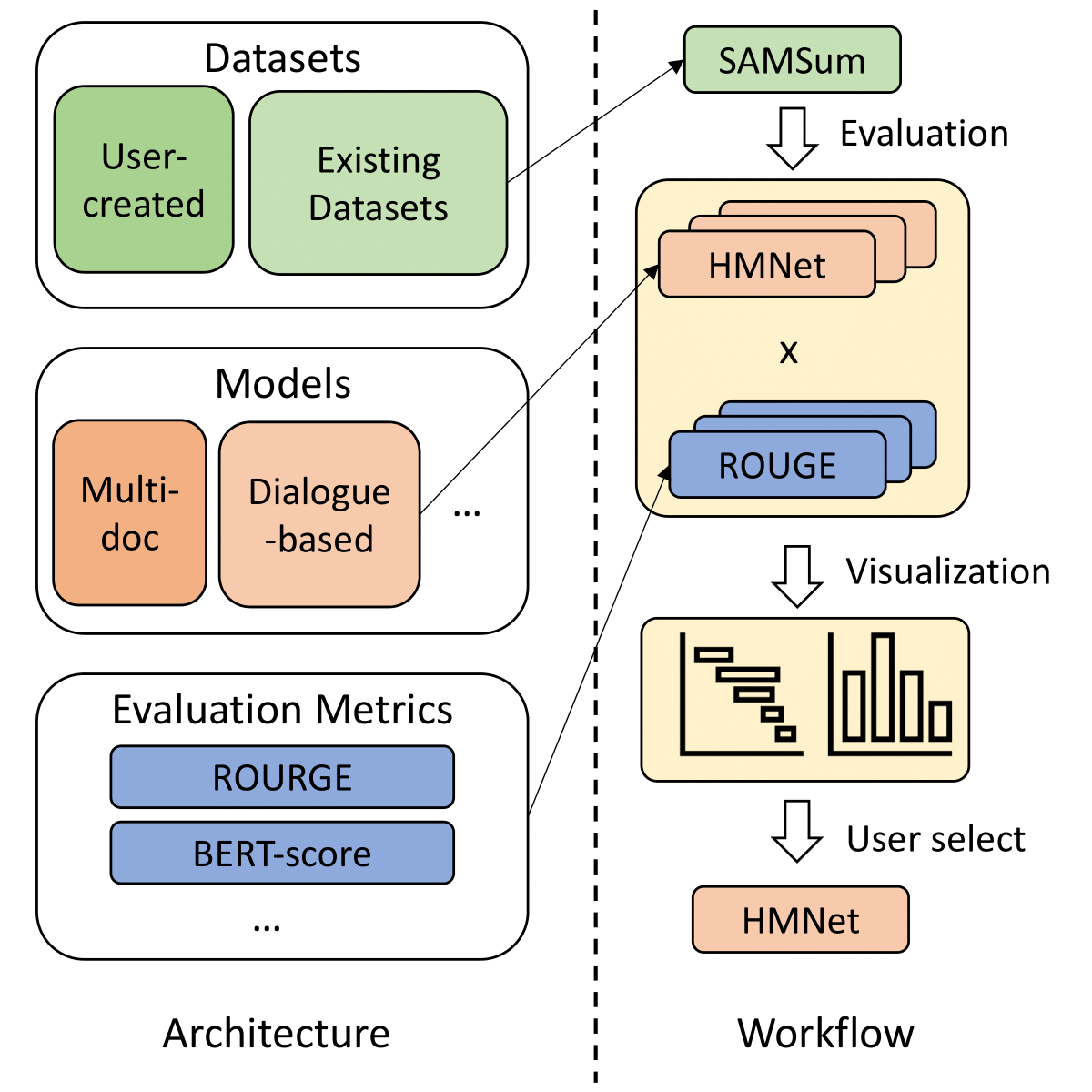
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022
CPU benchmark by calculating Pi, powered by Python3
cpu-benchmark Info: CPU benchmark by calculating Pi, powered by Python 3. Algorithm The program calculates pi with an accuracy of 10,000 decimal place
 20 Jan 3, 2023
20 Jan 3, 2023

An original implementation of "Noisy Channel Language Model Prompting for Few-Shot Text Classification"
Channel LM Prompting (and beyond) This includes an original implementation of Sewon Min, Mike Lewis, Hannaneh Hajishirzi, Luke Zettlemoyer. "Noisy Cha
 92 Jan 7, 2023
92 Jan 7, 2023
The CLRS Algorithmic Reasoning Benchmark
Learning representations of algorithms is an emerging area of machine learning, seeking to bridge concepts from neural networks with classical algorithms.
 251 Jan 5, 2023
251 Jan 5, 2023
Trex is a tool to match semantically similar functions based on transfer learning.
Trex is a tool to match semantically similar functions based on transfer learning.
 62 Dec 28, 2022
62 Dec 28, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 54 Aug 30, 2021
54 Aug 30, 2021
CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms
CARLA - Counterfactual And Recourse Library CARLA is a python library to benchmark counterfactual explanation and recourse models. It comes out-of-the
 200 Dec 28, 2022
200 Dec 28, 2022

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task。涵盖68个领域、共计916万词的专业词典知识库,可用于文本分类、知识增强、领域词汇库扩充等自然语言处理应用。
 357 Dec 24, 2022
357 Dec 24, 2022

PyTorch Implementation of CycleGAN and SSGAN for Domain Transfer (Minimal)
MNIST-to-SVHN and SVHN-to-MNIST PyTorch Implementation of CycleGAN and Semi-Supervised GAN for Domain Transfer. Prerequites Python 3.5 PyTorch 0.1.12
 401 Dec 30, 2022
401 Dec 30, 2022
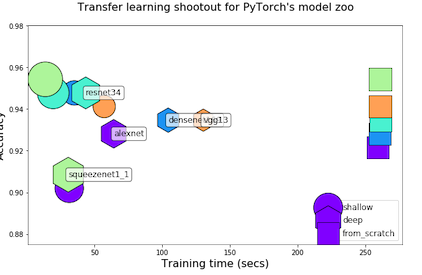
Transfer Learning Shootout for PyTorch's model zoo (torchvision)
pytorch-retraining Transfer Learning shootout for PyTorch's model zoo (torchvision). Load any pretrained model with custom final layer (num_classes) f
 169 Jun 29, 2022
169 Jun 29, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

Generate vibrant and detailed images using only text.
CLIP Guided Diffusion From RiversHaveWings. Generate vibrant and detailed images using only text. See captions and more generations in the Gallery See
 401 Dec 28, 2022
401 Dec 28, 2022

Simple torch.nn.module implementation of Alias-Free-GAN style filter and resample
Alias-Free-Torch Simple torch module implementation of Alias-Free GAN. This repository including Alias-Free GAN style lowpass sinc filter @filter.py A
 64 Dec 22, 2022
64 Dec 22, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022
![[Preprint]](https://github.com/VITA-Group/Deep_GCN_Benchmarking/raw/main/figs/combo.png)
[Preprint] "Bag of Tricks for Training Deeper Graph Neural Networks A Comprehensive Benchmark Study" by Tianlong Chen*, Kaixiong Zhou*, Keyu Duan, Wenqing Zheng, Peihao Wang, Xia Hu, Zhangyang Wang
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study Codes for [Preprint] Bag of Tricks for Training Deeper Graph
 101 Dec 29, 2022
101 Dec 29, 2022
Pip-package for trajectory benchmarking from "Be your own Benchmark: No-Reference Trajectory Metric on Registered Point Clouds", ECMR'21
Map Metrics for Trajectory Quality Map metrics toolkit provides a set of metrics to quantitatively evaluate trajectory quality via estimating consiste
 31 Oct 28, 2022
31 Oct 28, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023
Extract knowledge from raw text
Extract knowledge from raw text This repository is a nearly copy-paste of "From Text to Knowledge: The Information Extraction Pipeline" with some cosm
 10 Dec 3, 2022
10 Dec 3, 2022
Code release for NeurIPS 2020 paper "Co-Tuning for Transfer Learning"
CoTuning Official implementation for NeurIPS 2020 paper Co-Tuning for Transfer Learning. [News] 2021/01/13 The COCO 70 dataset used in the paper is av
 35 Sep 23, 2022
35 Sep 23, 2022

Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer Summary Explorer is a tool to visually inspect the summaries from several state-of-the-art neural summarization models across multipl
 42 Aug 14, 2022
42 Aug 14, 2022

Reference code for the paper CAMS: Color-Aware Multi-Style Transfer.
CAMS: Color-Aware Multi-Style Transfer Mahmoud Afifi1, Abdullah Abuolaim*1, Mostafa Hussien*2, Marcus A. Brubaker1, Michael S. Brown1 1York University
 36 Dec 4, 2022
36 Dec 4, 2022
This Telegram bot allows you to create direct links with pre-filled text to WhatsApp Chats
WhatsApp API Bot Telegram bot to create direct links with pre-filled text for WhatsApp Chats You can check our bot here. The bot is based on the API p
 17 Aug 20, 2022
17 Aug 20, 2022
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
42 Aug 14, 2022
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023

Official Implementation of Domain-Aware Universal Style Transfer
Domain Aware Universal Style Transfer Official Pytorch Implementation of 'Domain Aware Universal Style Transfer' (ICCV 2021) Domain Aware Universal St
 80 Dec 30, 2022
80 Dec 30, 2022

A "gym" style toolkit for building lightweight Neural Architecture Search systems
A "gym" style toolkit for building lightweight Neural Architecture Search systems
 12 Nov 5, 2022
12 Nov 5, 2022

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Text based command line webcam photobooth app
Skunkbooth Why See it in action Usage Installation Run Media location Contributing Install Poetry Clone the repo Activate poetry shell Install dev dep
 45 Dec 26, 2022
45 Dec 26, 2022

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022

The pytorch implementation of the paper "text-guided neural image inpainting" at MM'2020
TDANet: Text-Guided Neural Image Inpainting, MM'2020 (Oral) MM | ArXiv This repository implements the paper "Text-Guided Neural Image Inpainting" by L
 75 Dec 22, 2022
75 Dec 22, 2022

Database Reasoning Over Text project for ACL paper
Database Reasoning over Text This repository contains the code for the Database Reasoning Over Text paper, to appear at ACL2021. Work is performed in
 320 Dec 12, 2022
320 Dec 12, 2022

FedScale: Benchmarking Model and System Performance of Federated Learning
FedScale: Benchmarking Model and System Performance of Federated Learning (Paper) This repository contains scripts and instructions of building FedSca
 268 Jan 1, 2023
268 Jan 1, 2023

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
 47 Dec 18, 2022
47 Dec 18, 2022
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022

ALFRED - A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
ALFRED A Benchmark for Interpreting Grounded Instructions for Everyday Tasks Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han,
 204 Dec 15, 2022
204 Dec 15, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Dec 29, 2022
1.3k Dec 29, 2022
Full-text multi-table search application for Django. Easy to install and use, with good performance.
django-watson django-watson is a fast multi-model full-text search plugin for Django. It is easy to install and use, and provides high quality search
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

End-to-end text to speech system using gruut and onnx. There are 40 voices available across 8 languages.
End to end text to speech system using gruut and onnx
 673 Dec 28, 2022
673 Dec 28, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022
Export solved codewars kata challenges to a text file.
Codewars Kata Exporter Note:this is not totally my work.i've edited the project to make more easier and faster for me.you can find the original work h
 4 Aug 13, 2021
4 Aug 13, 2021

A demo for end-to-end English and Chinese text spotting using ABCNet.
ABCNet_Chinese A demo for end-to-end English and Chinese text spotting using ABCNet. This is an old model that was trained a long ago, which serves as
 45 Oct 4, 2022
45 Oct 4, 2022
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark We propose a benchmark to evaluate different quantization algorithms on vari
494 Dec 29, 2022
Text-Based Ideal Points
Text-Based Ideal Points Source code for the paper: Text-Based Ideal Points by Keyon Vafa, Suresh Naidu, and David Blei (ACL 2020). Update (June 29, 20
 37 Oct 9, 2022
37 Oct 9, 2022

PyTorch implementation of paper: AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer, ICCV 2021.
AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer [Paper] [PyTorch Implementation] [Paddle Implementation] Overview This reposit
 148 Dec 30, 2022
148 Dec 30, 2022

Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
 17.1k Jan 8, 2023
17.1k Jan 8, 2023
Code for "Finetuning Pretrained Transformers into Variational Autoencoders"
transformers-into-vaes Code for Finetuning Pretrained Transformers into Variational Autoencoders (our submission to NLP Insights Workshop 2021). Gathe
 22 Nov 26, 2022
22 Nov 26, 2022
ThinkTwice: A Two-Stage Method for Long-Text Machine Reading Comprehension
ThinkTwice ThinkTwice is a retriever-reader architecture for solving long-text machine reading comprehension. It is based on the paper: ThinkTwice: A
 4 Aug 6, 2021
4 Aug 6, 2021
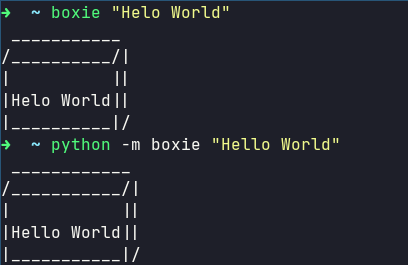
📦 A command line utility to put text in a box.
boxie A command line utility to put text in a box. Installation pip install boxie If you are on Linux you may need to use sudo to access this globally
 10 Jun 30, 2022
10 Jun 30, 2022

Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized
VQGAN-CLIP-Docker About Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized This is a stripped and minimal dependency repository for running loca
 73 Sep 11, 2022
73 Sep 11, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
 52 Jun 21, 2022
52 Jun 21, 2022
API for the GPT-J language model 🦜. Including a FastAPI backend and a streamlit frontend
gpt-j-api 🦜 An API to interact with the GPT-J language model. You can use and test the model in two different ways: Streamlit web app at http://api.v
 276 Dec 31, 2022
276 Dec 31, 2022

Pytorch implementation of CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation"
MUST-GAN Code | paper The Pytorch implementation of our CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generat
 46 Dec 26, 2022
46 Dec 26, 2022

Google Project: Search and auto-complete sentences within given input text files, manipulating data with complex data-structures.
Auto-Complete Google Project In this project there is an implementation for one feature of Google's search engines - AutoComplete. Autocomplete, or wo
 10 Jun 20, 2022
10 Jun 20, 2022
Hierarchical Metadata-Aware Document Categorization under Weak Supervision (WSDM'21)
Hierarchical Metadata-Aware Document Categorization under Weak Supervision This project provides a weakly supervised framework for hierarchical metada
 53 Sep 17, 2022
53 Sep 17, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
 37 Dec 4, 2022
37 Dec 4, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
 25 Nov 15, 2022
25 Nov 15, 2022
ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge (ManiSkill Challenge), a large-scale learning-from-demonstrations benchmark for object manipulation.
ManiSkill-Learn ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge, a large-scale learning-from-dem
 48 Dec 30, 2022
48 Dec 30, 2022
Code Repo for the ACL21 paper "Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning"
Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning This is the Github repository of our paper, "Common S
 19 Nov 30, 2022
19 Nov 30, 2022

Code for our CVPR 2021 Paper "Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes".
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes (CVPR 2021) Project page | Paper | Colab | Colab for Drawing App Rethinking Style
 153 Jan 4, 2023
153 Jan 4, 2023

Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP
Segmentation in Style: Unsupervised Semantic Image Segmentation with Stylegan and CLIP Abstract: We introduce a method that allows to automatically se
 134 Dec 19, 2022
134 Dec 19, 2022