2441 Repositories
Python video-to-image-converter Libraries
Automatically segment in-video YouTube sponsorships.
SponsorBlock Auto Segment [Model Download] Automatically segment in-video YouTube sponsorships. Trained on a large dataset of YouTube sponsor transcri
 7 Aug 22, 2022
7 Aug 22, 2022
🐥Flappy Birds🐤 Video game. With your help I can go through🚀 the pipes. All UI is made with 🐍Pygame🐍
🐠 Flappy Fish 🐢 I am Flappy Fish 🐟 . With your help I can jump through the pipes and experience an interesting and exciting flight deep into the fi
 2 Jan 14, 2022
2 Jan 14, 2022

VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations
VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations 3D-aware Image Synthesis via Learning Structural and Textura
 116 Dec 26, 2022
116 Dec 26, 2022

High-Resolution Image Synthesis with Latent Diffusion Models
Latent Diffusion Models arXiv | BibTeX High-Resolution Image Synthesis with Latent Diffusion Models Robin Rombach*, Andreas Blattmann*, Dominik Lorenz
 5.6k Dec 30, 2022
5.6k Dec 30, 2022
Create a Video Membership app using FastAPI & NoSQL
Video Membership Create a Video Membership app using FastAPI & NoSQL. In this series, we're going to explore building a membership application using F
 69 Dec 25, 2022
69 Dec 25, 2022
Python library that finds the size / type of an image given its URI by fetching as little as needed
FastImage This is an implementation of the excellent Ruby library FastImage - but for Python. FastImage finds the size or type of an image given its u
 28 Mar 1, 2022
28 Mar 1, 2022

Albert launcher extension for converting units of length, mass, speed, temperature, time, current, luminosity, printing measurements, molecular substance, and more
unit-converter-albert-ext Extension for converting units of length, mass, speed, temperature, time, current, luminosity, printing measurements, molecu
 2 Jan 13, 2022
2 Jan 13, 2022

Turn any live video stream or locally stored video into a dataset of interesting samples for ML training, or any other type of analysis.
Sieve Video Data Collection Example Find samples that are interesting within hours of raw video, for free and completely automatically using Sieve API
 72 Aug 1, 2022
72 Aug 1, 2022

A Simple YouTube Video Downloader With Python
Simple YouTube Video Downloader Simple YouTube Video Downloader is an open source project with a very simple UI that tries to speed up the process of
 2 Jan 3, 2022
2 Jan 3, 2022

Official PyTorch repo for JoJoGAN: One Shot Face Stylization
JoJoGAN: One Shot Face Stylization This is the PyTorch implementation of JoJoGAN: One Shot Face Stylization. Abstract: While there have been recent ad
 1.3k Dec 29, 2022
1.3k Dec 29, 2022

This repository contains a CBIR system that uses swin transformer to extract image's feature.
Swin-transformer based CBIR This repository contains a CBIR(content-based image retrieval) system. Here we use Swin-transformer to extract query image
 12 Nov 17, 2022
12 Nov 17, 2022

PyTorch implementation of Super SloMo by Jiang et al.
Super-SloMo PyTorch implementation of "Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation" by Jiang H., Sun
 2.9k Jan 3, 2023
2.9k Jan 3, 2023
CleverCSV is a Python package for handling messy CSV files.
CleverCSV is a Python package for handling messy CSV files. It provides a drop-in replacement for the builtin CSV module with improved dialect detection, and comes with a handy command line application for working with CSV files.
 1k Dec 19, 2022
1k Dec 19, 2022

Codes for “A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection”
DSAMNet The pytorch implementation for "A Deeply-supervised Attention Metric-based Network and an Open Aerial Image Dataset for Remote Sensing Change
 41 Dec 14, 2022
41 Dec 14, 2022

Code release for the paper “Worldsheet Wrapping the World in a 3D Sheet for View Synthesis from a Single Image”, ICCV 2021.
Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image This repository contains the code for the following paper: R. Hu,
 37 Jan 4, 2023
37 Jan 4, 2023

This repository contains the code used in the paper "Prompt-Based Multi-Modal Image Segmentation".
Prompt-Based Multi-Modal Image Segmentation This repository contains the code used in the paper "Prompt-Based Multi-Modal Image Segmentation". The sys
 305 Dec 30, 2022
305 Dec 30, 2022

StyleSwin: Transformer-based GAN for High-resolution Image Generation
StyleSwin This repo is the official implementation of "StyleSwin: Transformer-based GAN for High-resolution Image Generation". By Bowen Zhang, Shuyang
 349 Dec 28, 2022
349 Dec 28, 2022

Official repository for "Deep Recurrent Neural Network with Multi-scale Bi-directional Propagation for Video Deblurring".
RNN-MBP Deep Recurrent Neural Network with Multi-scale Bi-directional Propagation for Video Deblurring (AAAI-2022) by Chao Zhu, Hang Dong, Jinshan Pan
 22 Aug 31, 2022
22 Aug 31, 2022

Semantically Contrastive Learning for Low-light Image Enhancement
Semantically Contrastive Learning for Low-light Image Enhancement Here, we propose an effective semantically contrastive learning paradigm for Low-lig
 9 Dec 21, 2021
9 Dec 21, 2021

Official Pytorch implementation of the paper: "Locally Shifted Attention With Early Global Integration"
Locally-Shifted-Attention-With-Early-Global-Integration Pretrained models You can download all the models from here. Training Imagenet python -m torch
 14 Apr 15, 2022
14 Apr 15, 2022
Dumps the payload.bin image found in Android update images.
payload dumper Dumps the payload.bin image found in Android update images. Has significant performance gains over other tools due to using multiproces
 7 Nov 17, 2022
7 Nov 17, 2022
A unet implementation for Image semantic segmentation
Unet-pytorch a unet implementation for Image semantic segmentation 参考网上的Unet做分割的代码,做了一个针对kaggle地盐识别的,请去以下地址获取数据集: https://www.kaggle.com/c/tgs-salt-id
 3 Jun 29, 2022
3 Jun 29, 2022

Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions Accepted by AAAI 2022 [arxiv] Wenyu Liu, Gaofeng Ren, Runsheng Yu, Shi Guo, Jia
 245 Dec 16, 2022
245 Dec 16, 2022

No-reference Image Quality Assessment(NIQA) Algorithms (BRISQUE, NIQE, PIQE, RankIQA, MetaIQA)
No-Reference Image Quality Assessment Algorithms No-reference Image Quality Assessment(NIQA) is a task of evaluating an image without a reference imag
 26 Jan 4, 2023
26 Jan 4, 2023
Implementation for paper "STAR: A Structure-aware Lightweight Transformer for Real-time Image Enhancement" (ICCV 2021).
STAR-pytorch Implementation for paper "STAR: A Structure-aware Lightweight Transformer for Real-time Image Enhancement" (ICCV 2021). CVF (pdf) STAR-DC
 43 Dec 21, 2022
43 Dec 21, 2022
Official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.
GLIDE This is the official codebase for running the small, filtered-data GLIDE model from GLIDE: Towards Photorealistic Image Generation and Editing w
 2.9k Jan 4, 2023
2.9k Jan 4, 2023

Depth image based mouse cursor visual haptic
Depth image based mouse cursor visual haptic How to run it. Install pyqt5. Install python modules pip install Pillow pip install numpy For illustrati
 17 Dec 20, 2022
17 Dec 20, 2022

High-Resolution Image Synthesis with Latent Diffusion Models
Latent Diffusion Models Requirements A suitable conda environment named ldm can be created and activated with: conda env create -f environment.yaml co
5.6k Jan 4, 2023
The code for paper "Contrastive Spatio-Temporal Pretext Learning for Self-supervised Video Representation" which is accepted by AAAI 2022
Contrastive Spatio Temporal Pretext Learning for Self-supervised Video Representation (AAAI 2022) The code for paper "Contrastive Spatio-Temporal Pret
 8 Jun 30, 2022
8 Jun 30, 2022

A basic duplicate image detection service using perceptual image hash functions and nearest neighbor search, implemented using faiss, fastapi, and imagehash
Duplicate Image Detection Getting Started Install dependencies pip install -r requirements.txt Run service python main.py Testing Test with pytest How
 21 Nov 11, 2022
21 Nov 11, 2022
You can draw the corresponding bounding box into the image and save it according to the result file (txt format) run by the tracker.
You can draw the corresponding bounding box into the image and save it according to the result file (txt format) run by the tracker.
 42 Dec 6, 2022
42 Dec 6, 2022
Video Stream: an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat
Video Stream is an Advanced Telegram Bot that's allow you to play Video & Music on Telegram Group Video Chat 🧪 Get SESSION_NAME from below: Pyrogram
 6 Feb 8, 2022
6 Feb 8, 2022
MISSFormer: An Effective Medical Image Segmentation Transformer
MISSFormer Code for paper "MISSFormer: An Effective Medical Image Segmentation Transformer". Please read our preprint at the following link: paper_add
 22 Dec 24, 2022
22 Dec 24, 2022
Streaming over lightweight data transformations
Description Data augmentation libarary for Deep Learning, which supports images, segmentation masks, labels and keypoints. Furthermore, SOLT is fast a
 256 Jan 8, 2023
256 Jan 8, 2023
computer vision, image processing and machine learning on the web browser or node.
Image processing and Machine learning labs computer vision, image processing and machine learning on the web browser or node note Fast Fourier Trans
 487 Nov 11, 2022
487 Nov 11, 2022
Build and Push docker image in Python (luigi + docker-py)
Docker build images workflow in Python Since docker hub stopped building images for free accounts, I've been looking for another way to do it. I could
 2 Dec 15, 2022
2 Dec 15, 2022
Скрипт который выводит видео в консоль. Ничего лишнего)
video-to-ascii Скрипт который выводит видео в консоль. Ничего лишнего) Требования Минимальное разрешение экрана: 1280x720 Видео в качестве 360p 10-45f
 155 Nov 28, 2022
155 Nov 28, 2022
A warping based image translation model focusing on upper body synthesis.
Pose2Img Upper body image synthesis from skeleton(Keypoints). Sub module in the ICCV-2021 paper "Speech Drives Templates: Co-Speech Gesture Synthesis
 15 Nov 10, 2022
15 Nov 10, 2022

Auto-Lama combines object detection and image inpainting to automate object removals
Auto-Lama Auto-Lama combines object detection and image inpainting to automate object removals. It is build on top of DE:TR from Facebook Research and
 44 Dec 9, 2022
44 Dec 9, 2022

An end-to-end image translation model with weight-map for color constancy
CCUnet An end-to-end image translation model with weight-map for color constancy 1. Download the dataset (take Colorchecker_recommended dataset as an
 1 Dec 21, 2021
1 Dec 21, 2021
Pytorch implementation of the paper Improving Text-to-Image Synthesis Using Contrastive Learning
T2I_CL This is the official Pytorch implementation of the paper Improving Text-to-Image Synthesis Using Contrastive Learning Requirements Linux Python
 42 Dec 31, 2022
42 Dec 31, 2022
A Telegram bot to transcribe audio, video and image into text.
Transcriber Bot A Telegram bot to transcribe audio, video and image into text. Deploy to Heroku Local Deploying Install the FFmpeg. Make sure you have
 10 Dec 19, 2022
10 Dec 19, 2022
An Telegram Bot By @ZauteKm To Stream Videos In Telegram Voice Chat Of Both Groups & Channels. Supports Live Streams, YouTube Videos & Telegram Media !!
Telegram Video Stream Bot (Py-TgCalls) An Telegram Bot By @ZauteKm To Stream Videos In Telegram Voice Chat Of Both Groups & Channels. Supports Live St
 14 Oct 21, 2022
14 Oct 21, 2022
Single Image Random Dot Stereogram for Tensorflow
TensorFlow-SIRDS Single Image Random Dot Stereogram for Tensorflow SIRDS is a means to present 3D data in a 2D image. It allows for scientific data di
 5 Aug 10, 2022
5 Aug 10, 2022

TensorFlow Implementation of Unsupervised Cross-Domain Image Generation
Domain Transfer Network (DTN) TensorFlow implementation of Unsupervised Cross-Domain Image Generation. Requirements Python 2.7 TensorFlow 0.12 Pickle
 864 Dec 30, 2022
864 Dec 30, 2022

TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
902 Nov 29, 2022

Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Super Resolution Examples We run this script under TensorFlow 2.0 and the TensorLayer2.0+. For TensorLayer 1.4 version, please check release. 🚀 🚀 🚀
 2.9k Jan 8, 2023
2.9k Jan 8, 2023

Useful PDF-related productivity tool.
Luftmensch 1.4.7 (Español) | 1.4.3 (English) Version 1.4.7 (Español) released in October 2021. Version 1.4.3 (English) released in September 2021. 🏮
 8 Dec 29, 2022
8 Dec 29, 2022
Django models and endpoints for working with large images -- tile serving
Django Large Image Models and endpoints for working with large images in Django -- specifically geared towards geospatial tile serving. DISCLAIMER: th
 42 Dec 17, 2022
42 Dec 17, 2022

Turning images into '9-pan' palettes using KMeans clustering from sklearn.
img2palette Turning images into '9-pan' palettes using KMeans clustering from sklearn. Requirements We require: Pillow, for opening and processing ima
 2 Jan 1, 2022
2 Jan 1, 2022
Inverse Rendering for Complex Indoor Scenes: Shape, Spatially-Varying Lighting and SVBRDF From a Single Image
Inverse Rendering for Complex Indoor Scenes: Shape, Spatially-Varying Lighting and SVBRDF From a Single Image (Project page) Zhengqin Li, Mohammad Sha
 209 Jan 5, 2023
209 Jan 5, 2023
InverseRenderNet: Learning single image inverse rendering, CVPR 2019.
InverseRenderNet: Learning single image inverse rendering !! Check out our new work InverseRenderNet++ paper and code, which improves the inverse rend
 141 Dec 20, 2022
141 Dec 20, 2022
![[CVPR 2020] Local Class-Specific and Global Image-Level Generative Adversarial Networks for Semantic-Guided Scene Generation](https://github.com/Ha0Tang/LGGAN/raw/master/imgs/framework.jpg)
[CVPR 2020] Local Class-Specific and Global Image-Level Generative Adversarial Networks for Semantic-Guided Scene Generation
Contents Local and Global GAN Cross-View Image Translation Semantic Image Synthesis Acknowledgments Related Projects Citation Contributions Collaborat
 131 Dec 7, 2022
131 Dec 7, 2022
![[CVPR 2019 Oral] Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation](https://github.com/Ha0Tang/SelectionGAN/raw/master/imgs/motivation.jpg)
[CVPR 2019 Oral] Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation
SelectionGAN for Guided Image-to-Image Translation CVPR Paper | Extended Paper | Guided-I2I-Translation-Papers Citation If you use this code for your
424 Dec 2, 2022
Project repo for Learning Category-Specific Mesh Reconstruction from Image Collections
Learning Category-Specific Mesh Reconstruction from Image Collections Angjoo Kanazawa*, Shubham Tulsiani*, Alexei A. Efros, Jitendra Malik University
 438 Dec 22, 2022
438 Dec 22, 2022

Learning 3D Part Assembly from a Single Image
Learning 3D Part Assembly from a Single Image This repository contains a PyTorch implementation of the paper: Learning 3D Part Assembly from A Single
 18 Dec 21, 2022
18 Dec 21, 2022
High-Resolution 3D Human Digitization from A Single Image.
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (CVPR 2020) News: [2020/06/15] Demo with Google Colab (i
8.4k Dec 29, 2022
Convert human motion from video to .bvh
video_to_bvh Convert human motion from video to .bvh with Google Colab Usage 1. Open video_to_bvh.ipynb in Google Colab Go to https://colab.research.g
 306 Dec 10, 2022
306 Dec 10, 2022

Efficient 3D human pose estimation in video using 2D keypoint trajectories
3D human pose estimation in video with temporal convolutions and semi-supervised training This is the implementation of the approach described in the
3.1k Dec 29, 2022

WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region (Paper and DataSet). [New] Note that all the emails about the download permission o
 71 Dec 22, 2022
71 Dec 22, 2022
A python program to download one or multiple videos from YouTube.
YouTube-Video-Downloader A python program to download one or multiple videos from YouTube. Quick Start guide First Clone The Project git clone https:/
 1 Sep 11, 2022
1 Sep 11, 2022
Spatio-Temporal Entropy Model (STEM) for end-to-end leaned video compression.
Spatio-Temporal Entropy Model A Pytorch Reproduction of Spatio-Temporal Entropy Model (STEM) for end-to-end leaned video compression. More details can
 16 Nov 28, 2022
16 Nov 28, 2022
Automatically remove the mosaics in images and videos, or add mosaics to them.
Automatically remove the mosaics in images and videos, or add mosaics to them.
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
Deep Learning segmentation suite designed for 2D microscopy image segmentation
Deep Learning segmentation suite dessigned for 2D microscopy image segmentation This repository provides researchers with a code to try different enco
 7 Nov 3, 2022
7 Nov 3, 2022
Mixed Transformer UNet for Medical Image Segmentation
MT-UNet Update 2021/11/19 Thank you for your interest in our work. We have uploaded the code of our MTUNet to help peers conduct further research on i
 92 Dec 25, 2022
92 Dec 25, 2022

Ensembling Off-the-shelf Models for GAN Training
Vision-aided GAN video (3m) | website | paper Can the collective knowledge from a large bank of pretrained vision models be leveraged to improve GAN t
 345 Dec 28, 2022
345 Dec 28, 2022
![[ICCV 2021] Target Adaptive Context Aggregation for Video Scene Graph Generation](https://github.com/MCG-NJU/TRACE/raw/main/gt_vidvrd.png)
[ICCV 2021] Target Adaptive Context Aggregation for Video Scene Graph Generation
Target Adaptive Context Aggregation for Video Scene Graph Generation This is a PyTorch implementation for Target Adaptive Context Aggregation for Vide
 44 Dec 14, 2022
44 Dec 14, 2022
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
[AAAI 2022] Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding Official Pytorch implementation of Negative Sample Matter
69 Dec 26, 2022

Code for Deep Single-image Portrait Image Relighting
Deep Single-Image Portrait Relighting [Project Page] Hao Zhou, Sunil Hadap, Kalyan Sunkavalli, David W. Jacobs. In ICCV, 2019 Overview Test script for
 438 Jan 5, 2023
438 Jan 5, 2023

Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation
Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation [Arxiv] [Video] Evaluation code for Unrestricted Facial Geometry Reconstr
 242 Dec 30, 2022
242 Dec 30, 2022
Code for TIP 2017 paper --- Illumination Decomposition for Photograph with Multiple Light Sources.
Illumination_Decomposition Code for TIP 2017 paper --- Illumination Decomposition for Photograph with Multiple Light Sources. This code implements the
 7 Nov 15, 2020
7 Nov 15, 2020

Code for "Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose"
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose We provide PyTorch implementations for our arxiv paper "Audio-dr
 497 Jan 9, 2023
497 Jan 9, 2023
AudioDVP:Photorealistic Audio-driven Video Portraits
AudioDVP This is the official implementation of Photorealistic Audio-driven Video Portraits. Major Requirements Ubuntu = 18.04 PyTorch = 1.2 GCC =
 232 Jan 3, 2023
232 Jan 3, 2023
This is the official PyTorch implementation of the CVPR 2020 paper "TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting".
TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting Project Page | YouTube | Paper This is the official PyTorch implementation of the C
 330 Dec 11, 2022
330 Dec 11, 2022

This repository contains the source code for the paper First Order Motion Model for Image Animation
!!! Check out our new paper and framework improved for articulated objects First Order Motion Model for Image Animation This repository contains the s
 13k Jan 9, 2023
13k Jan 9, 2023

Code for the paper Progressive Pose Attention for Person Image Generation in CVPR19 (Oral).
Pose-Transfer Code for the paper Progressive Pose Attention for Person Image Generation in CVPR19(Oral). The paper is available here. Video generation
 679 Jan 4, 2023
679 Jan 4, 2023
Converts a base copy of Pokemon BDSP's masterdatas into a more readable and editable Pokemon Showdown Format.
Showdown-BDSP-Converter Converts a base copy of Pokemon BDSP's masterdatas into a more readable and editable Pokemon Showdown Format. Download the lat
 2 Jan 2, 2022
2 Jan 2, 2022

Industrial Image Anomaly Localization Based on Gaussian Clustering of Pre-trained Feature
Industrial Image Anomaly Localization Based on Gaussian Clustering of Pre-trained Feature Q. Wan, L. Gao, X. Li and L. Wen, "Industrial Image Anomaly
 6 Dec 25, 2022
6 Dec 25, 2022

Tool to create a Phunk image with a custom background
Create Phunk image Tool to create a Phunk image with a custom background Installation Clone the repo git clone https://github.com/albanow/etherscan_sa
 6 Mar 31, 2022
6 Mar 31, 2022

Ensembling Off-the-shelf Models for GAN Training
Data-Efficient GANs with DiffAugment project | paper | datasets | video | slides Generated using only 100 images of Obama, grumpy cats, pandas, the Br
 1.2k Dec 26, 2022
1.2k Dec 26, 2022
pyYotubemanager is full web automated bot capable of General tasks like:- Uploading a Video , Downloading , adding Title , Description , Listing types , adding Thumbnail
PyYoutubemanager Explore the docs » View Demo · Report Bug · Request Feature About The Project PyYotubemanager is full web automated bot capable of Ge
 4 Jun 29, 2022
4 Jun 29, 2022

Download YouTube videos/music and images in MP4, JPG with this tool.
ABOUT THE TOOL Download YouTube videos, music and images in MP4, JPG with this tool, with an easy to understand interface. This tool works with both,
 5 Jan 2, 2023
5 Jan 2, 2023

Wonkey - an open source programming language for the creation of cross-platform video games
Wonkey Programming Language Wonkey is an open source programming language for the creation of cross-platform video games, highly inspired by the “Blit
 110 Nov 9, 2022
110 Nov 9, 2022
Using pytorch to implement unet network for liver image segmentation.
Using pytorch to implement unet network for liver image segmentation.
 1 Dec 17, 2021
1 Dec 17, 2021

Virtual Dance Reality Stage: a feature that offers you to share a stage with another user virtually
Portrait Segmentation using Tensorflow This script removes the background from an input image. You can read more about segmentation here Setup The scr
 291 Dec 24, 2022
291 Dec 24, 2022

A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization
University1652-Baseline [Paper] [Slide] [Explore Drone-view Data] [Explore Satellite-view Data] [Explore Street-view Data] [Video Sample] [中文介绍] This
 335 Jan 6, 2023
335 Jan 6, 2023

Unofficial implementation of Google's FNet: Mixing Tokens with Fourier Transforms
FNet: Mixing Tokens with Fourier Transforms Pytorch implementation of Fnet : Mixing Tokens with Fourier Transforms. Citation: @misc{leethorp2021fnet,
 217 Dec 5, 2022
217 Dec 5, 2022
GANformer: Generative Adversarial Transformers
GANformer: Generative Adversarial Transformers Drew A. Hudson* & C. Lawrence Zitnick Update: We released the new GANformer2 paper! *I wish to thank Ch
 1k Dec 16, 2021
1k Dec 16, 2021
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning. CVPR 2018
Large Scale Fine-Grained Categorization and Domain-Specific Transfer Learning Tensorflow code and models for the paper: Large Scale Fine-Grained Categ
 187 Oct 1, 2022
187 Oct 1, 2022

Implementation of Research Paper "Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation"
Zero-DCE and Zero-DCE++(Lite architechture for Mobile and edge Devices) Papers Abstract The paper presents a novel method, Zero-Reference Deep Curve E
 15 Dec 10, 2022
15 Dec 10, 2022
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Jul 30, 2022
4 Jul 30, 2022
[ACM MM 2021] Yes, "Attention is All You Need", for Exemplar based Colorization
Transformer for Image Colorization This is an implemention for Yes, "Attention Is All You Need", for Exemplar based Colorization, and the current soft
 30 Dec 7, 2022
30 Dec 7, 2022
A self-hosted streaming platform with Discord authentication, auto-recording and more!
A self-hosted streaming platform with Discord authentication, auto-recording and more!
 331 Dec 27, 2022
331 Dec 27, 2022

SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation
SeqFormer: a Frustratingly Simple Model for Video Instance Segmentation SeqFormer SeqFormer: a Frustratingly Simple Model for Video Instance Segmentat
 298 Dec 22, 2022
298 Dec 22, 2022

Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation in TensorFlow 2
Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation in TensorFlow 2 Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexan
 1 Dec 16, 2021
1 Dec 16, 2021
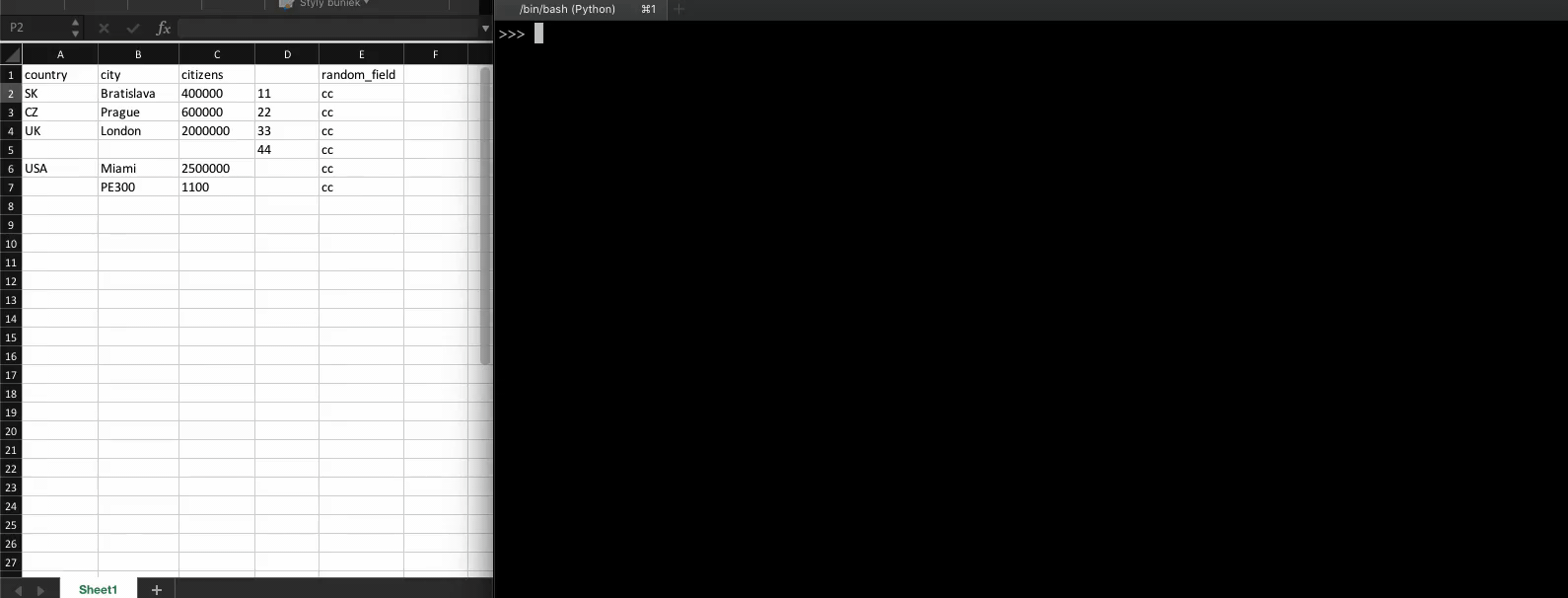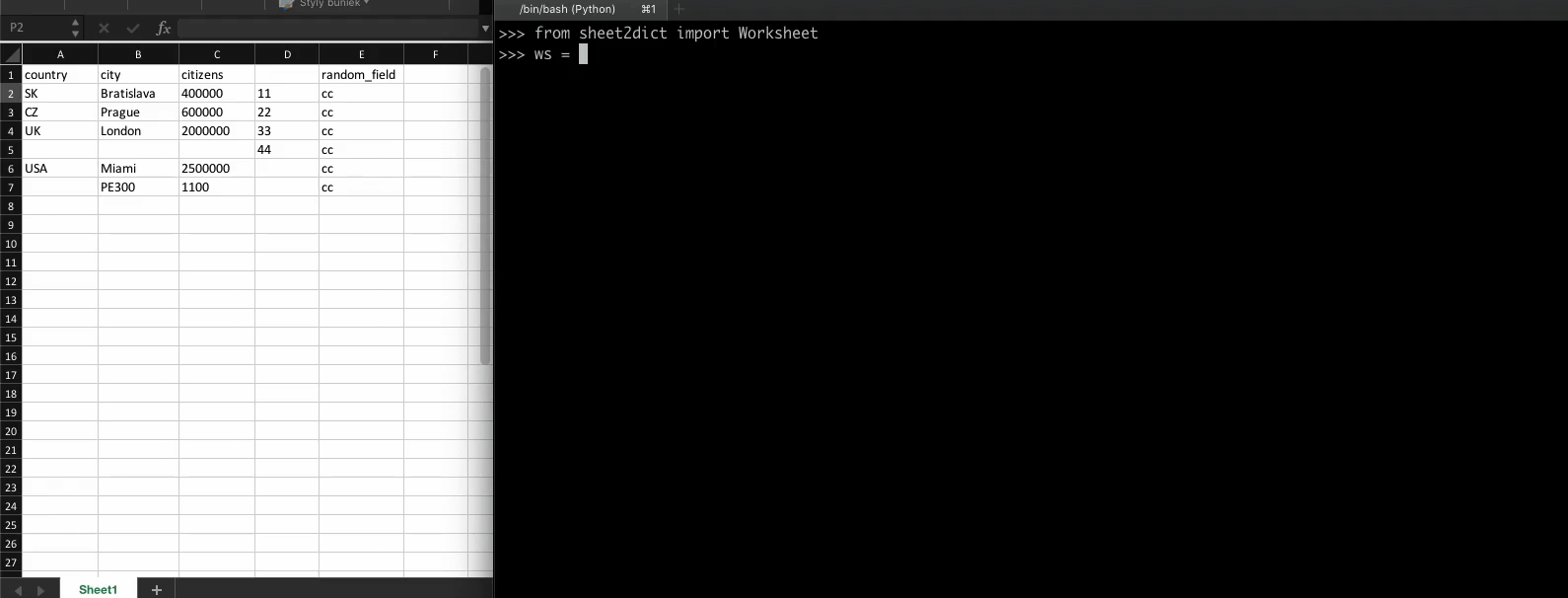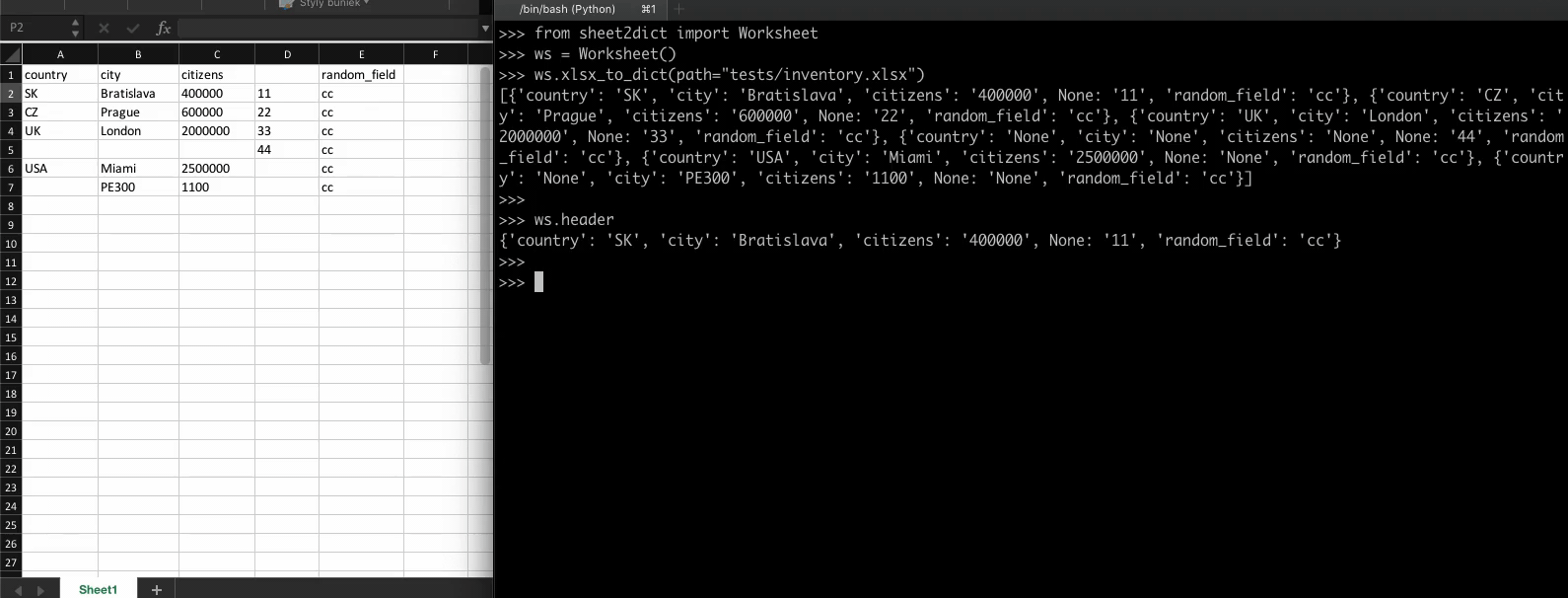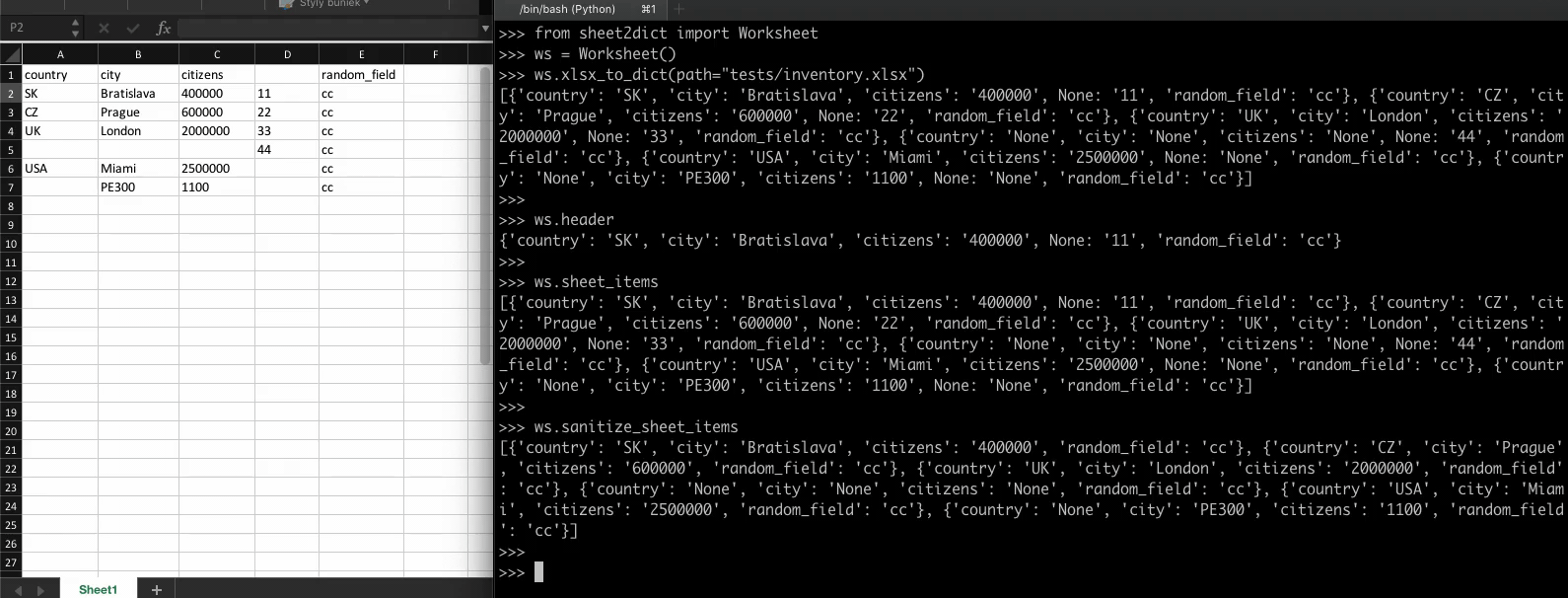
A simple XLSX/CSV reader - to dictionary converter
sheet2dict A simple XLSX/CSV reader - to dictionary converter Installing To install the package from pip, first run: python3 -m pip install --no-cache
 216 Nov 25, 2022
216 Nov 25, 2022

👻🟡 Download all Snapchat video & photo memories from a data export.
Snapchat "Memories" Fetcher In compliance with the California Consumer Privacy Act of 2018 (“CCPA”), businesses which collect and store user data must
 18 Dec 26, 2022
18 Dec 26, 2022
Whole-day timezone comparison
Timezone Converter Compare a full day of your local timezone with foreign ones $ timezone-converter tijuana --zone $ timezone-converter tijuana new_yo
 12 Nov 24, 2022
12 Nov 24, 2022
Utilizes Pose Estimation to offer sprinters cues based on an image of their running form.
Running-Form-Correction Utilizes Pose Estimation to offer sprinters cues based on an image of their running form. How to Run Dependencies You will nee
 3 Nov 8, 2022
3 Nov 8, 2022
Dynamic View Synthesis from Dynamic Monocular Video
Dynamic View Synthesis from Dynamic Monocular Video Project Website | Video | Paper Dynamic View Synthesis from Dynamic Monocular Video Chen Gao, Ayus
 139 Dec 28, 2022
139 Dec 28, 2022