2441 Repositories
Python video-to-image-converter Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Temporally Efficient Vision Transformer for Video Instance Segmentation, CVPR 2022, Oral
Temporally Efficient Vision Transformer for Video Instance Segmentation Temporally Efficient Vision Transformer for Video Instance Segmentation (CVPR
 203 Dec 31, 2022
203 Dec 31, 2022

Official code for CVPR2022 paper: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
📖 Depth-Aware Generative Adversarial Network for Talking Head Video Generation (CVPR 2022) 🔥 If DaGAN is helpful in your photos/projects, please hel
 503 Jan 4, 2023
503 Jan 4, 2023

"MST++: Multi-stage Spectral-wise Transformer for Efficient Spectral Reconstruction" (CVPRW 2022) & (Winner of NTIRE 2022 Challenge on Spectral Reconstruction from RGB)
MST++: Multi-stage Spectral-wise Transformer for Efficient Spectral Reconstruction (CVPRW 2022) Yuanhao Cai, Jing Lin, Zudi Lin, Haoqian Wang, Yulun Z
 274 Jan 5, 2023
274 Jan 5, 2023

The official repo for OC-SORT: Observation-Centric SORT on video Multi-Object Tracking. OC-SORT is simple, online and robust to occlusion/non-linear motion.
OC-SORT Observation-Centric SORT (OC-SORT) is a pure motion-model-based multi-object tracker. It aims to improve tracking robustness in crowded scenes
 325 Jan 5, 2023
325 Jan 5, 2023

Official Pytorch and JAX implementation of "Efficient-VDVAE: Less is more"
The Official Pytorch and JAX implementation of "Efficient-VDVAE: Less is more" Arxiv preprint Louay Hazami · Rayhane Mama · Ragavan Thurairatn
 144 Dec 23, 2022
144 Dec 23, 2022

"SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image", Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Humphrey Shi, Zhangyang Wang
SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image [Paper] [Website] Pipeline Code Environment pip install -r requirements
 250 Jan 5, 2023
250 Jan 5, 2023

Official code for "Towards An End-to-End Framework for Flow-Guided Video Inpainting" (CVPR2022)
E2FGVI (CVPR 2022) English | 简体中文 This repository contains the official implementation of the following paper: Towards An End-to-End Framework for Flo
 537 Jan 7, 2023
537 Jan 7, 2023
Official repository of "BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment"
BasicVSR_PlusPlus (CVPR 2022) [Paper] [Project Page] [Code] This is the official repository for BasicVSR++. Please feel free to raise issue related to
 227 Jan 1, 2023
227 Jan 1, 2023

Pytorch implementation of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Make-A-Scene - PyTorch Pytorch implementation (inofficial) of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors (https://arxiv.org/
 259 Dec 28, 2022
259 Dec 28, 2022

Pop-Out Motion: 3D-Aware Image Deformation via Learning the Shape Laplacian (CVPR 2022)
Pop-Out Motion Pop-Out Motion: 3D-Aware Image Deformation via Learning the Shape Laplacian (CVPR 2022) Jihyun Lee*, Minhyuk Sung*, Hyunjin Kim, Tae-Ky
 88 Nov 22, 2022
88 Nov 22, 2022

Official implementation for "Style Transformer for Image Inversion and Editing" (CVPR 2022)
Style Transformer for Image Inversion and Editing (CVPR2022) https://arxiv.org/abs/2203.07932 Existing GAN inversion methods fail to provide latent co
 153 Dec 2, 2022
153 Dec 2, 2022
![[CVPR 2022] Thin-Plate Spline Motion Model for Image Animation.](https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model/raw/main/assets/vox.gif)
[CVPR 2022] Thin-Plate Spline Motion Model for Image Animation.
[CVPR2022] Thin-Plate Spline Motion Model for Image Animation Source code of the CVPR'2022 paper "Thin-Plate Spline Motion Model for Image Animation"
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

Unofficial implementation (replicates paper results!) of MINER: Multiscale Implicit Neural Representations in pytorch-lightning
MINER_pl Unofficial implementation of MINER: Multiscale Implicit Neural Representations in pytorch-lightning. 📖 Ref readings Laplacian pyramid explan
 51 Nov 28, 2022
51 Nov 28, 2022

FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection
FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection arXi
 59 Nov 29, 2022
59 Nov 29, 2022

PyTorch implementation of U-TAE and PaPs for satellite image time series panoptic segmentation.
Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks (ICCV 2021) This repository is the official implem
 71 Jan 4, 2023
71 Jan 4, 2023
I will implement Fastai in each projects present in this repository.
DEEP LEARNING FOR CODERS WITH FASTAI AND PYTORCH The repository contains a list of the projects which I have worked on while reading the book Deep Lea
 43 Dec 20, 2022
43 Dec 20, 2022

Official repository accompanying a CVPR 2022 paper EMOCA: Emotion Driven Monocular Face Capture And Animation. EMOCA takes a single image of a face as input and produces a 3D reconstruction. EMOCA sets the new standard on reconstructing highly emotional images in-the-wild
EMOCA: Emotion Driven Monocular Face Capture and Animation Radek Daněček · Michael J. Black · Timo Bolkart CVPR 2022 This repository is the official i
 339 Dec 30, 2022
339 Dec 30, 2022

Official implementation of the paper 'Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution' in CVPR 2022
LDL Paper | Supplementary Material Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution Jie Liang*, Hu
 150 Dec 26, 2022
150 Dec 26, 2022

One line to host them all. Bootstrap your image search case in minutes.
One line to host them all. Bootstrap your image search case in minutes. Survey NOW gives the world access to customized neural image search in just on
 403 Dec 30, 2022
403 Dec 30, 2022
Official code for ROCA: Robust CAD Model Retrieval and Alignment from a Single Image (CVPR 2022)
ROCA: Robust CAD Model Alignment and Retrieval from a Single Image (CVPR 2022) Code release of our paper ROCA. Check out our video, paper, and website
 123 Dec 25, 2022
123 Dec 25, 2022

MAT: Mask-Aware Transformer for Large Hole Image Inpainting
MAT: Mask-Aware Transformer for Large Hole Image Inpainting (CVPR2022, Oral) Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, Jiaya Jia [Paper] News This
 254 Dec 29, 2022
254 Dec 29, 2022

Official implementation of the paper 'Efficient and Degradation-Adaptive Network for Real-World Image Super-Resolution'
DASR Paper Efficient and Degradation-Adaptive Network for Real-World Image Super-Resolution Jie Liang, Hui Zeng, and Lei Zhang. In arxiv preprint. Abs
81 Dec 28, 2022

A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution (CVPR2022)
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution (CVPR2022) https://arxiv.org/abs/2203.09388 Jianqi Ma, Zheto
 104 Jan 5, 2023
104 Jan 5, 2023

Python package to generate image embeddings with CLIP without PyTorch/TensorFlow
imgbeddings A Python package to generate embedding vectors from images, using OpenAI's robust CLIP model via Hugging Face transformers. These image em
 81 Jan 4, 2023
81 Jan 4, 2023

Generate images from texts. In Russian
ruDALL-E Generate images from texts pip install rudalle==1.1.0rc0 🤗 HF Models: ruDALL-E Malevich (XL) ruDALL-E Emojich (XL) (readme here) ruDALL-E S
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

The official implementation of Autoregressive Image Generation using Residual Quantization (CVPR '22)
Autoregressive Image Generation using Residual Quantization (CVPR 2022) The official implementation of "Autoregressive Image Generation using Residual
 529 Dec 30, 2022
529 Dec 30, 2022
HugsVision is a easy to use huggingface wrapper for state-of-the-art computer vision
HugsVision is an open-source and easy to use all-in-one huggingface wrapper for computer vision. The goal is to create a fast, flexible and user-frien
 166 Nov 27, 2022
166 Nov 27, 2022

Seaborn is one of the go-to tools for statistical data visualization in python. It has been actively developed since 2012 and in July 2018, the author released version 0.9. This version of Seaborn has several new plotting features, API changes and documentation updates which combine to enhance an already great library. This article will walk through a few of the highlights and show how to use the new scatter and line plot functions for quickly creating very useful visualizations of data.
12_Python_Seaborn_Module Introduction 👋 From the website, “Seaborn is a Python data visualization library based on matplotlib. It provides a high-lev
 192 Dec 16, 2022
192 Dec 16, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022
![[CVPR 2022] Unsupervised Image-to-Image Translation with Generative Prior](https://raw.githubusercontent.com/williamyang1991/GP-UNIT/main/doc_images/results.jpg)
[CVPR 2022] Unsupervised Image-to-Image Translation with Generative Prior
GP-UNIT - Official PyTorch Implementation This repository provides the official PyTorch implementation for the following paper: Unsupervised Image-to-
 125 Jan 3, 2023
125 Jan 3, 2023
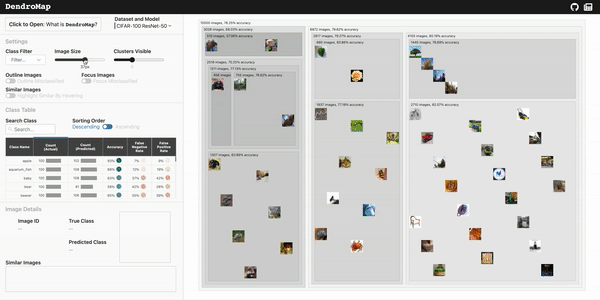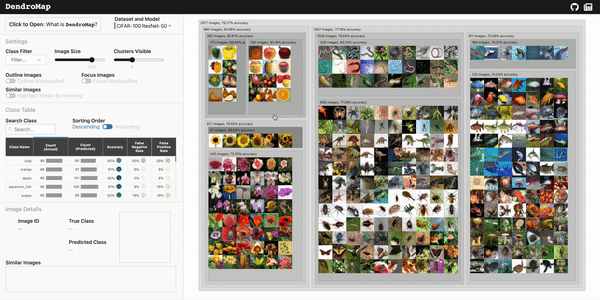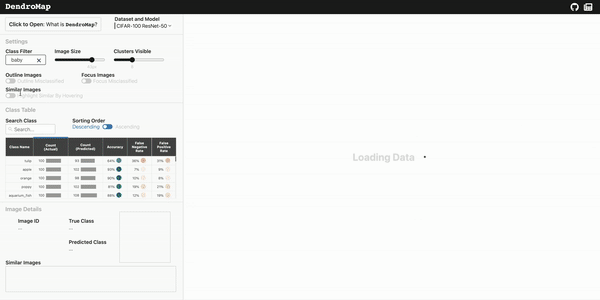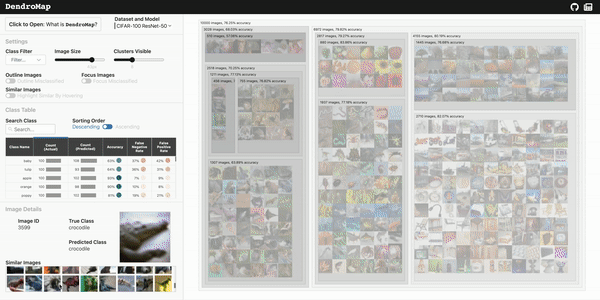
This repository contains the DendroMap implementation for scalable and interactive exploration of image datasets in machine learning.
DendroMap DendroMap is an interactive tool to explore large-scale image datasets used for machine learning. A deep understanding of your data can be v
 33 Dec 30, 2022
33 Dec 30, 2022
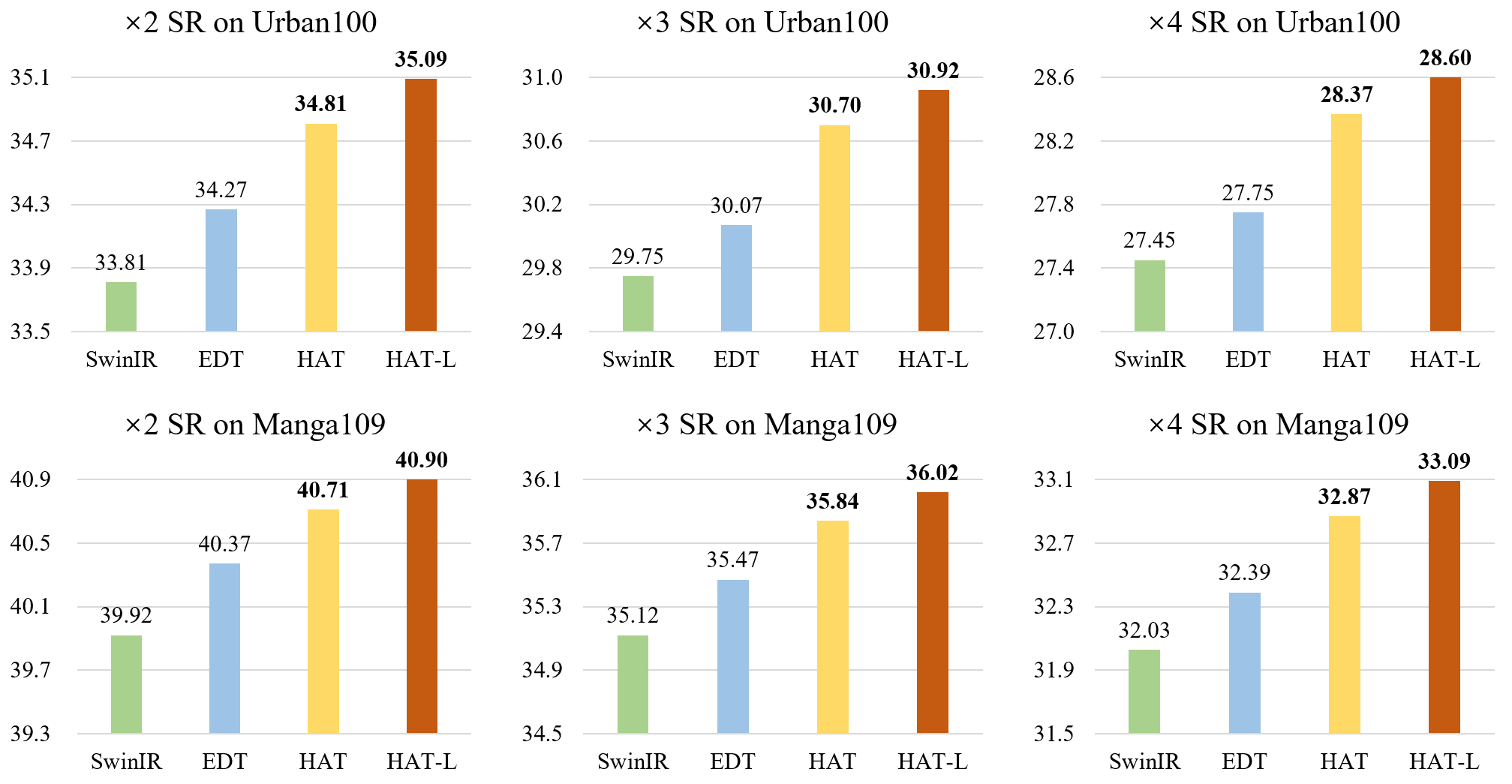
Activating More Pixels in Image Super-Resolution Transformer
HAT [Paper Link] Activating More Pixels in Image Super-Resolution Transformer Xiangyu Chen, Xintao Wang, Jiantao Zhou and Chao Dong BibTeX @article{ch
 270 Dec 27, 2022
270 Dec 27, 2022

GPU-accelerated Image Processing library using OpenCL
pyclesperanto pyclesperanto is a python package for clEsperanto - a multi-language framework for GPU-accelerated image processing. clEsperanto uses Op
 17 Dec 25, 2022
17 Dec 25, 2022
This project shows how to serve an TF based image classification model as a web service with TFServing, Docker, and Kubernetes(GKE).
Deploying ML models with CPU based TFServing, Docker, and Kubernetes By: Chansung Park and Sayak Paul This project shows how to serve a TensorFlow ima
 104 Dec 28, 2022
104 Dec 28, 2022

A lightweight yet powerful audio-to-MIDI converter with pitch bend detection
Basic Pitch is a Python library for Automatic Music Transcription (AMT), using lightweight neural network developed by Spotify's Audio Intelligence La
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
Video Frame Interpolation with Transformer (CVPR2022)
VFIformer Official PyTorch implementation of our CVPR2022 paper Video Frame Interpolation with Transformer Dependencies python = 3.8 pytorch = 1.8.0
 63 Dec 16, 2022
63 Dec 16, 2022

A fast poisson image editing implementation that can utilize multi-core CPU or GPU to handle a high-resolution image input.
Poisson Image Editing - A Parallel Implementation Jiayi Weng (jiayiwen), Zixu Chen (zixuc) Poisson Image Editing is a technique that can fuse two imag
 110 Dec 27, 2022
110 Dec 27, 2022

Python library for tracking human heads with FLAME (a 3D morphable head model)
Video Head Tracker 3D tracking library for human heads based on FLAME (a 3D morphable head model). The tracking algorithm is inspired by face2face. It
 61 Dec 25, 2022
61 Dec 25, 2022

A python-image-classification web application project, written in Python and served through the Flask Microframework. This Project implements the VGG16 covolutional neural network, through Keras and Tensorflow wrappers, to make predictions on uploaded images.
Image Classification in Python Implementing image classification in Flask using Keras. The VGG16 is a convolution neural network model architecture th
 19 Dec 12, 2022
19 Dec 12, 2022

The repository contains reproducible PyTorch source code of our paper Generative Modeling with Optimal Transport Maps, ICLR 2022.
Generative Modeling with Optimal Transport Maps The repository contains reproducible PyTorch source code of our paper Generative Modeling with Optimal
 30 Dec 22, 2022
30 Dec 22, 2022
H&M Fashion Image similarity search with Weaviate and DocArray
H&M Fashion Image similarity search with Weaviate and DocArray This example shows how to do image similarity search using DocArray and Weaviate as Doc
 18 Aug 11, 2022
18 Aug 11, 2022

Arabic Car License Recognition. A solution to the kaggle competition Machathon 3.0.
Transformers Arabic licence plate recognition 🚗 Solution to the kaggle competition Machathon 3.0. Ranked in the top 6️⃣ at the final evaluation phase
 17 Dec 4, 2022
17 Dec 4, 2022

ConvMAE: Masked Convolution Meets Masked Autoencoders
ConvMAE ConvMAE: Masked Convolution Meets Masked Autoencoders Peng Gao1, Teli Ma1, Hongsheng Li2, Jifeng Dai3, Yu Qiao1, 1 Shanghai AI Laboratory, 2 M
 345 Jan 8, 2023
345 Jan 8, 2023

Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch
CoCa - Pytorch Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch. They were able to elegantly fit in contras
 565 Dec 30, 2022
565 Dec 30, 2022
Awesome Remote Sensing Toolkit based on PaddlePaddle.
基于飞桨框架开发的高性能遥感图像处理开发套件,端到端地完成从训练到部署的全流程遥感深度学习应用。 最新动态 PaddleRS 即将发布alpha版本!欢迎大家试用 简介 PaddleRS是遥感科研院所、相关高校共同基于飞桨开发的遥感处理平台,支持遥感图像分类,目标检测,图像分割,以及变化检测等常用遥
 146 Dec 11, 2022
146 Dec 11, 2022
[CVPR 2022] Official PyTorch Implementation for "Reference-based Video Super-Resolution Using Multi-Camera Video Triplets"
Reference-based Video Super-Resolution (RefVSR) Official PyTorch Implementation of the CVPR 2022 Paper Project | arXiv | RealMCVSR Dataset This repo c
 151 Dec 30, 2022
151 Dec 30, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022
![[Arxiv preprint] Causality-inspired Single-source Domain Generalization for Medical Image Segmentation (code&data-processing pipeline)](https://github.com/cheng-01037/Causality-Medical-Image-Domain-Generalization/raw/main/intro.png)
[Arxiv preprint] Causality-inspired Single-source Domain Generalization for Medical Image Segmentation (code&data-processing pipeline)
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation Arxiv preprint Repository under construction. Might still be bug
 31 Dec 27, 2022
31 Dec 27, 2022
This project shows how to serve an ONNX-optimized image classification model as a web service with FastAPI, Docker, and Kubernetes.
Deploying ML models with FastAPI, Docker, and Kubernetes By: Sayak Paul and Chansung Park This project shows how to serve an ONNX-optimized image clas
 104 Dec 23, 2022
104 Dec 23, 2022

Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (CVPR2022)
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding by Qiaole Dong*, Chenjie Cao*, Yanwei Fu Paper and Supple
 190 Dec 27, 2022
190 Dec 27, 2022

dyld_shared_cache processing / Single-Image loading for BinaryNinja
Dyld Shared Cache Parser Author: cynder (kat) Dyld Shared Cache Support for BinaryNinja Without any of the fuss of requiring manually loading several
 76 Dec 28, 2022
76 Dec 28, 2022
![ISNAS-DIP: Image Specific Neural Architecture Search for Deep Image Prior [CVPR 2022]](https://github.com/ozgurkara99/ISNAS-DIP/raw/main/docs/method.jpg)
ISNAS-DIP: Image Specific Neural Architecture Search for Deep Image Prior [CVPR 2022]
ISNAS-DIP: Image-Specific Neural Architecture Search for Deep Image Prior (CVPR 2022) Metin Ersin Arican*, Ozgur Kara*, Gustav Bredell, Ender Konukogl
 24 Dec 18, 2022
24 Dec 18, 2022

Implementation of CaiT models in TensorFlow and ImageNet-1k checkpoints. Includes code for inference and fine-tuning.
CaiT-TF (Going deeper with Image Transformers) This repository provides TensorFlow / Keras implementations of different CaiT [1] variants from Touvron
9 Jun 26, 2022
Scalable Optical Flow-based Image Montaging and Alignment
SOFIMA SOFIMA (Scalable Optical Flow-based Image Montaging and Alignment) is a tool for stitching, aligning and warping large 2d, 3d and 4d microscopy
 16 Dec 21, 2022
16 Dec 21, 2022
Codes for "Efficient Long-Range Attention Network for Image Super-resolution"
ELAN Codes for "Efficient Long-Range Attention Network for Image Super-resolution", arxiv link. Dependencies & Installation Please refer to the follow
 124 Dec 22, 2022
124 Dec 22, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022
🥇 LG-AI-Challenge 2022 1위 솔루션 입니다.
LG-AI-Challenge-for-Plant-Classification Dacon에서 진행된 농업 환경 변화에 따른 작물 병해 진단 AI 경진대회 에 대한 코드입니다. (colab directory에 코드가 잘 정리 되어있습니다.) Requirements python
 10 Jun 30, 2022
10 Jun 30, 2022

level1-image-classification-level1-recsys-09 created by GitHub Classroom
level1-image-classification-level1-recsys-09 ❗ 주제 설명 COVID-19 Pandemic 상황 속 마스크 착용 유무 판단 시스템 구축 마스크 착용 여부, 성별, 나이 총 세가지 기준에 따라 총 18개의 class로 구분하는 모델 ?
 6 Mar 17, 2022
6 Mar 17, 2022

Sequencer: Deep LSTM for Image Classification
Sequencer: Deep LSTM for Image Classification Created by Yuki Tatsunami Masato Taki This repository contains implementation for Sequencer. Abstract In
 111 Dec 16, 2022
111 Dec 16, 2022

Multi-View Consistent Generative Adversarial Networks for 3D-aware Image Synthesis (CVPR2022)
Multi-View Consistent Generative Adversarial Networks for 3D-aware Image Synthesis Multi-View Consistent Generative Adversarial Networks for 3D-aware
 78 Dec 10, 2022
78 Dec 10, 2022

This is the open source implementation of the ICLR2022 paper "StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis"
StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image
 840 Dec 26, 2022
840 Dec 26, 2022
Telegram Group Calls Streaming bot with some useful features, written in Python with Pyrogram and Py-Tgcalls. Supporting platforms like Youtube, Spotify, Resso, AppleMusic, Soundcloud and M3u8 Links.
Yukki Music Bot Yukki Music Bot is a Powerful Telegram Music+Video Bot written in Python using Pyrogram and Py-Tgcalls by which you can stream songs,
 996 Dec 28, 2022
996 Dec 28, 2022
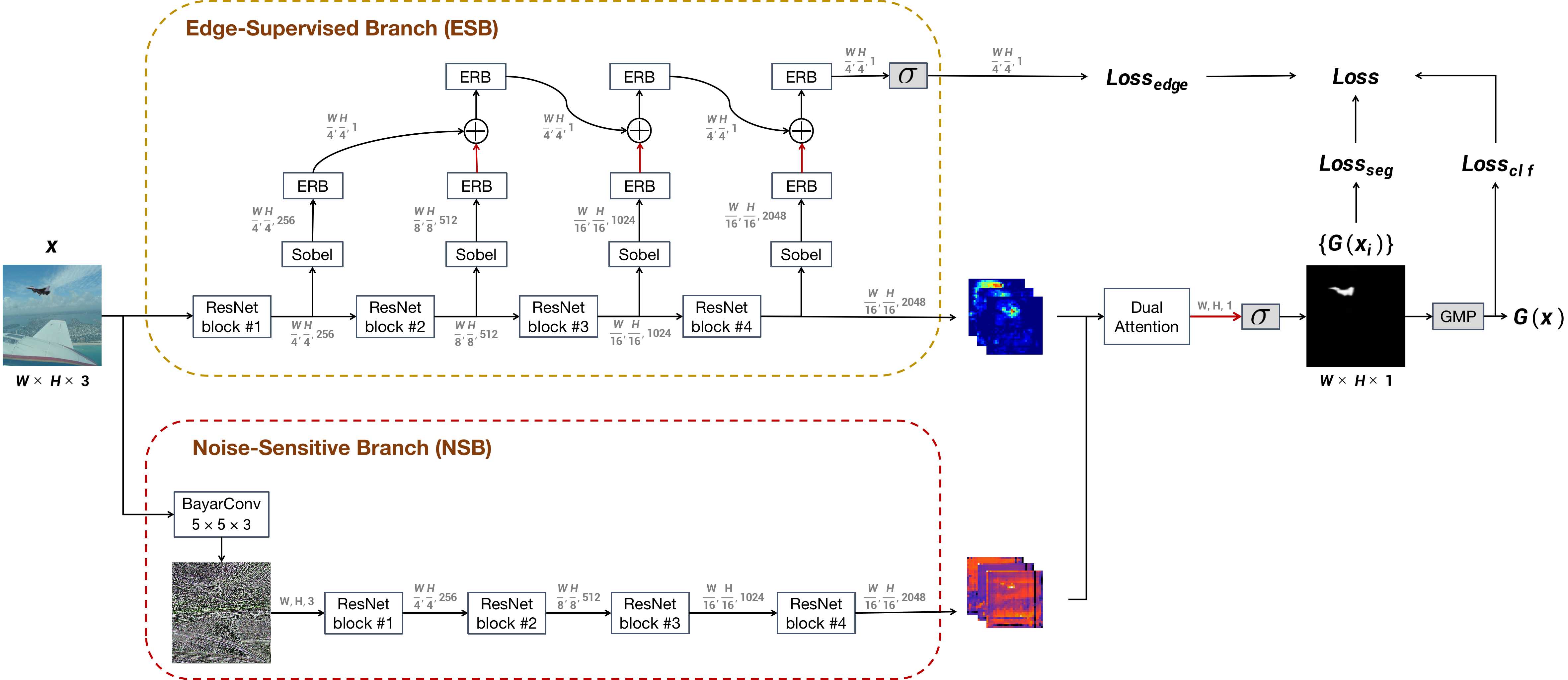
code for Image Manipulation Detection by Multi-View Multi-Scale Supervision
MVSS-Net Code and models for ICCV 2021 paper: Image Manipulation Detection by Multi-View Multi-Scale Supervision Update 22.02.17, Pretrained model for
 131 Dec 30, 2022
131 Dec 30, 2022

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Implements VQGAN+CLIP for image and video generation, and style transfers, based on text and image prompts. Emphasis on ease-of-use, documentation, and smooth video creation.
VQGAN-CLIP-GENERATOR Overview This is a package (with available notebook) for running VQGAN+CLIP locally, with a focus on ease of use, good documentat
 98 Dec 30, 2022
98 Dec 30, 2022

Official Implementation of "Third Time's the Charm? Image and Video Editing with StyleGAN3" https://arxiv.org/abs/2201.13433
Third Time's the Charm? Image and Video Editing with StyleGAN3 Yuval Alaluf*, Or Patashnik*, Zongze Wu, Asif Zamir, Eli Shechtman, Dani Lischinski, Da
 531 Dec 20, 2022
531 Dec 20, 2022

CLIPfa: Connecting Farsi Text and Images
CLIPfa: Connecting Farsi Text and Images OpenAI released the paper Learning Transferable Visual Models From Natural Language Supervision in which they
 66 Dec 14, 2022
66 Dec 14, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
118 Jan 7, 2023
Implementation of the famous Image Manipulation\Forgery Detector "ManTraNet" in Pytorch
Who has never met a forged picture on the web ? No one ! Everyday we are constantly facing fake pictures touched up in Photoshop but it is not always
 77 Dec 16, 2022
77 Dec 16, 2022
.png)
Contextual Attention Network: Transformer Meets U-Net
Contextual Attention Network: Transformer Meets U-Net Contexual attention network for medical image segmentation with state of the art results on skin
 67 Nov 28, 2022
67 Nov 28, 2022

Official PyTorch implementation of the paper "Deep Constrained Least Squares for Blind Image Super-Resolution", CVPR 2022.
Deep Constrained Least Squares for Blind Image Super-Resolution [Paper] This is the official implementation of 'Deep Constrained Least Squares for Bli
 141 Dec 30, 2022
141 Dec 30, 2022

Open source implementation of "A Self-Supervised Descriptor for Image Copy Detection" (SSCD).
A Self-Supervised Descriptor for Image Copy Detection (SSCD) This is the open-source codebase for "A Self-Supervised Descriptor for Image Copy Detecti
68 Jan 4, 2023
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

The PyTorch implementation for paper "Neural Texture Extraction and Distribution for Controllable Person Image Synthesis" (CVPR2022 Oral)
ArXiv | Get Start Neural-Texture-Extraction-Distribution The PyTorch implementation for our paper "Neural Texture Extraction and Distribution for Cont
 111 Dec 10, 2022
111 Dec 10, 2022

PromptDet: Expand Your Detector Vocabulary with Uncurated Images
PromptDet: Expand Your Detector Vocabulary with Uncurated Images Paper Website Introduction The goal of this work is to establish a scalable pipeline
 103 Dec 20, 2022
103 Dec 20, 2022

Code for CVPR'2022 paper ✨ "Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model"
PPE ✨ Repository for our CVPR'2022 paper: Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-
 34 Nov 28, 2022
34 Nov 28, 2022

Official implementation for "QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation" (CVPR 2022)
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation (CVPR2022) https://arxiv.org/abs/2203.08483 Unpaired image-to-image (I2I
50 Dec 16, 2022
Implementation of Retrieval-Augmented Denoising Diffusion Probabilistic Models in Pytorch
Retrieval-Augmented Denoising Diffusion Probabilistic Models (wip) Implementation of Retrieval-Augmented Denoising Diffusion Probabilistic Models in P
55 Jan 1, 2023

PyTorch implementations of the paper: "DR.VIC: Decomposition and Reasoning for Video Individual Counting, CVPR, 2022"
DRNet for Video Indvidual Counting (CVPR 2022) Introduction This is the official PyTorch implementation of paper: DR.VIC: Decomposition and Reasoning
 35 Nov 22, 2022
35 Nov 22, 2022

Contrastive learning of Class-agnostic Activation Map for Weakly Supervised Object Localization and Semantic Segmentation (CVPR 2022)
CCAM (Unsupervised) Code repository for our paper "CCAM: Contrastive learning of Class-agnostic Activation Map for Weakly Supervised Object Localizati
 113 Dec 27, 2022
113 Dec 27, 2022

Hyperbolic Image Segmentation, CVPR 2022
Hyperbolic Image Segmentation, CVPR 2022 This is the implementation of paper Hyperbolic Image Segmentation (CVPR 2022). Repository structure assets :
 46 Dec 29, 2022
46 Dec 29, 2022

Official code for "Bridging Video-text Retrieval with Multiple Choice Questions", CVPR 2022 (Oral).
Bridging Video-text Retrieval with Multiple Choice Questions, CVPR 2022 (Oral) Paper | Project Page | Pre-trained Model | CLIP-Initialized Pre-trained
 99 Jan 6, 2023
99 Jan 6, 2023

Maximum Spatial Perturbation for Image-to-Image Translation (Official Implementation)
MSPC for I2I This repository is by Yanwu Xu and contains the PyTorch source code to reproduce the experiments in our CVPR2022 paper Maximum Spatial Pe
 51 Dec 14, 2022
51 Dec 14, 2022

The official codes of our CVPR2022 paper: A Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift
TwoStageAlign The official codes of our CVPR2022 paper: A Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift Pa
 32 Dec 15, 2022
32 Dec 15, 2022
UMT is a unified and flexible framework which can handle different input modality combinations, and output video moment retrieval and/or highlight detection results.
Unified Multi-modal Transformers This repository maintains the official implementation of the paper UMT: Unified Multi-modal Transformers for Joint Vi
84 Jan 4, 2023
An example to implement a new backbone with OpenMMLab framework.
Backbone example on OpenMMLab framework English | 简体中文 Introduction This is an template repo about how to use OpenMMLab framework to develop a new bac
 22 Dec 29, 2022
22 Dec 29, 2022
Library for converting from RGB / GrayScale image to base64 and back.
Library for converting RGB / Grayscale numpy images from to base64 and back. Installation pip install -U image_to_base_64 Conversion RGB to base 64 b
 16 Aug 28, 2022
16 Aug 28, 2022
Lowest memory consumption and second shortest runtime in NTIRE 2022 challenge on Efficient Super-Resolution
FMEN Lowest memory consumption and second shortest runtime in NTIRE 2022 on Efficient Super-Resolution. Our paper: Fast and Memory-Efficient Network T
 33 Dec 1, 2022
33 Dec 1, 2022

Very simple NCHW and NHWC conversion tool for ONNX. Change to the specified input order for each and every input OP. Also, change the channel order of RGB and BGR. Simple Channel Converter for ONNX.
scc4onnx Very simple NCHW and NHWC conversion tool for ONNX. Change to the specified input order for each and every input OP. Also, change the channel
 16 Dec 22, 2022
16 Dec 22, 2022
Direct application of DALLE-2 to video synthesis, using factored space-time Unet and Transformers
DALLE2 Video (wip) ** only to be built after DALLE2 image is done and replicated, and the importance of the prior network is validated ** Direct appli
105 May 15, 2022

CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP
CLIP-GEN [简体中文][English] 本项目在萤火二号集群上用 PyTorch 实现了论文 《CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP》。 CLIP-GEN 是一个 Language-F
 75 Dec 29, 2022
75 Dec 29, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
![[CVPRW 2022] Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network](https://github.com/IIGROUP/AHIQ/raw/main/Figures/architecture.png)
[CVPRW 2022] Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
Attention Helps CNN See Better: Hybrid Image Quality Assessment Network [CVPRW 2022] Code for Hybrid Image Quality Assessment Network [paper] [code] T
 49 Dec 11, 2022
49 Dec 11, 2022
An open souce video/music streamer based on MPV and piped.
🎶 Harmony Music An easy way to stream videos or music from Youtube from the command line while regaining your privacy. 📖 Table Of Contents ❔ What's
 16 Nov 15, 2022
16 Nov 15, 2022
Sound-guided Semantic Image Manipulation - Official Pytorch Code (CVPR 2022)
🔉 Sound-guided Semantic Image Manipulation (CVPR2022) Official Pytorch Implementation Sound-guided Semantic Image Manipulation IEEE/CVF Conference on
 58 Dec 28, 2022
58 Dec 28, 2022
Optimizes image files by converting them to webp while also updating all references.
About Optimizes images by (re-)saving them as webp. For every file it replaced it automatically updates all references. Works on single files as well
 18 Dec 23, 2022
18 Dec 23, 2022
Fast TikTok NO Watermark Video Downloader (username or url)
💎 TD [ TikDown v4 ] Star ⭐ if you want more Discord Server * discord.gg/onlp | Waxor#9999 Why not open source anymore ? * BECAUSE PEOPLE SKID, STEA
 26 Dec 1, 2022
26 Dec 1, 2022