31 Repositories
Python wikipedia Libraries

Wik is use to get information about anything on the shell using Wikipedia.
WIK wik is a tool to view wikipedia pages from your terminal. It also let you search for any wikipedia up to date article on one query from your termi
 340 Dec 18, 2022
340 Dec 18, 2022

Official codebase for Can Wikipedia Help Offline Reinforcement Learning?
Official codebase for Can Wikipedia Help Offline Reinforcement Learning?
 82 Dec 19, 2022
82 Dec 19, 2022
Downloads state flags from wikipedia for states/regions from all countries
world-state-flags Downloads state flags from wikipedia for states/regions from all countries This data is NOT curated Uses https://github.com/dr5hn/co
 2 Dec 15, 2022
2 Dec 15, 2022
Wikipedia-Utils: Preprocessing Wikipedia Texts for NLP
Wikipedia-Utils: Preprocessing Wikipedia Texts for NLP This repository maintains some utility scripts for retrieving and preprocessing Wikipedia text
 44 Oct 19, 2022
44 Oct 19, 2022
Cities bot - A simple example of using aiogram and the wikipedia package
Cities game A simple example of using aiogram and the wikipedia package. The bot
 2 Jan 29, 2022
2 Jan 29, 2022

Implementation of Memory-Compressed Attention, from the paper "Generating Wikipedia By Summarizing Long Sequences"
Memory Compressed Attention Implementation of the Self-Attention layer of the proposed Memory-Compressed Attention, in Pytorch. This repository offers
 47 Dec 23, 2022
47 Dec 23, 2022
A streaming animation of all the edits to a given Wikipedia page.
WikiFilms! What is it? A streaming animation of all the edits to a given Wikipedia page. How it works. It works by creating a "virtual camera," which
 2 Jan 18, 2022
2 Jan 18, 2022

A calibre plugin that generates Word Wise and X-Ray files then sends them to Kindle. Supports KFX, AZW3 and MOBI eBooks. X-Ray supports 18 languages.
WordDumb A calibre plugin that generates Word Wise and X-Ray files then sends them to Kindle. Supports KFX, AZW3 and MOBI eBooks. Languages X-Ray supp
 172 Dec 29, 2022
172 Dec 29, 2022
Voice Assistant inspired by Google Assistant, Cortana, Alexa, Siri, ...
author: @shival_gupta VoiceAI This program is an example of a simple virtual assitant It will listen to you and do accordingly It will begin with wish
 1 Jan 6, 2022
1 Jan 6, 2022
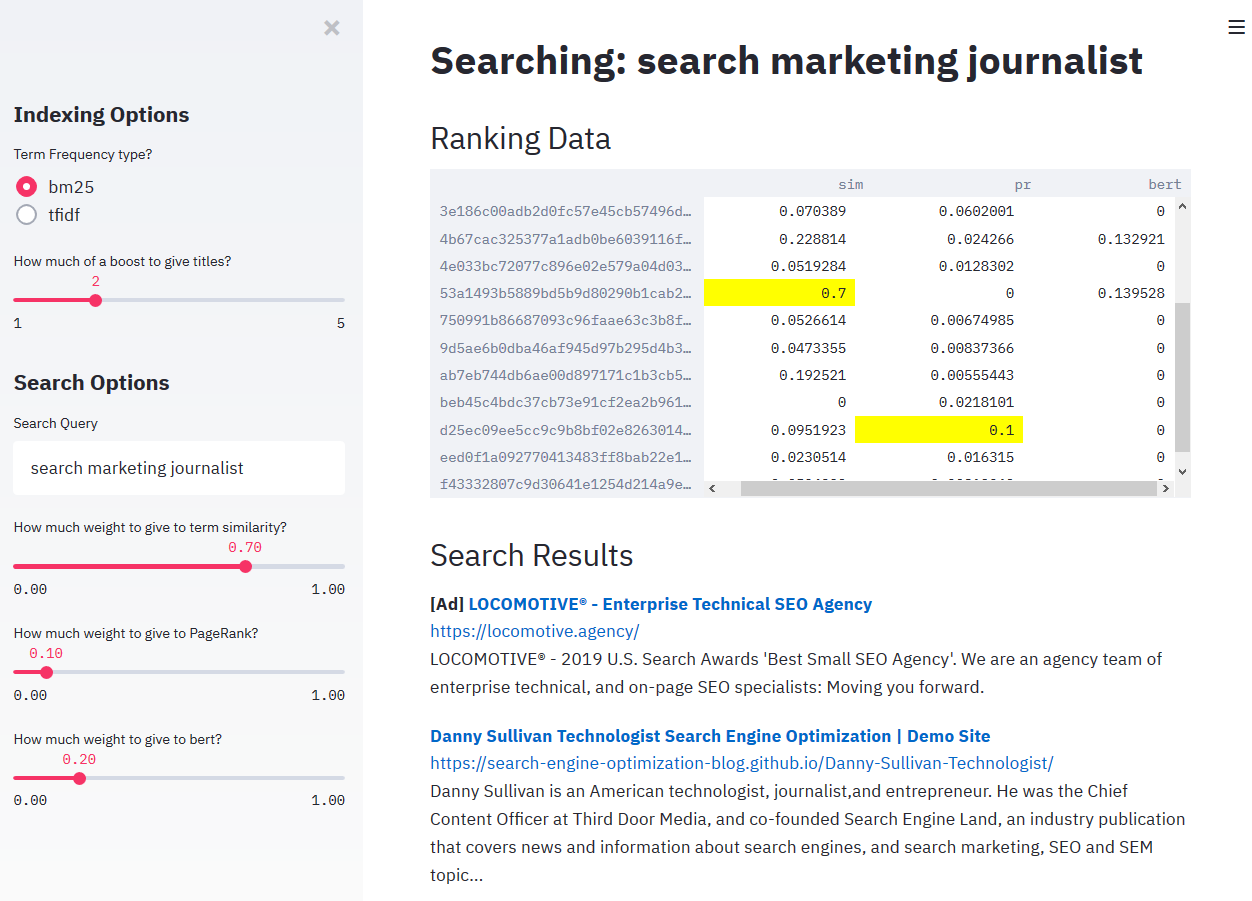
Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index.
TechSEO Crawler Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index. Play with the r
 57 Nov 24, 2022
57 Nov 24, 2022
Semantic search through a vectorized Wikipedia (SentenceBERT) with the Weaviate vector search engine
Semantic search through Wikipedia with the Weaviate vector search engine Weaviate is an open source vector search engine with build-in vectorization a
 191 Dec 26, 2022
191 Dec 26, 2022
Inverted index creation and query search mechanism on Wikipedia pages.
WikiPedia Search Engine Step 1 : Installing Requirements Install "stemming" module for python using pip. Step 2 : Parsing the Data To parse the data,
 1 Nov 27, 2021
1 Nov 27, 2021

Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data.
Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data. Then used Yahoo Finance to get the related stock data and displayed them in the form of charts.
 3 Sep 9, 2022
3 Sep 9, 2022
Wikipedia Extractive Text Summarizer + Keywords Identification (entropy-based)
Wikipedia Extractive Text Summarizer + Keywords Identification (entropy-based)Wikipedia Extractive Text Summarizer + Keywords Identification (entropy-based)
 1 Nov 8, 2021
1 Nov 8, 2021
wikirepo is a Python package that provides a framework to easily source and leverage standardized Wikidata information
Python based Wikidata framework for easy dataframe extraction wikirepo is a Python package that provides a framework to easily source and leverage sta
 35 Jan 4, 2023
35 Jan 4, 2023

Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordcloud packages
Wikipedia WordCloud App Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordclou
 5 Jan 2, 2022
5 Jan 2, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
Ross Virtual Assistant is a programme which can play Music, search Wikipedia, open Websites and much more.
Ross-Virtual-Assistant Ross Virtual Assistant is a programme which can play Music, search Wikipedia, open Websites and much more. Installation Downloa
 4 Nov 8, 2021
4 Nov 8, 2021

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022

Esse script procura qualquer, dados que você queira na wikipedia! Em breve traremos um com dados em toda a internet.
Buscador de dados simples Dependências necessárias Para você poder começar a utilizar esta ferramenta, você vai precisar da dependência "wikipedia", p
 4 Feb 24, 2022
4 Feb 24, 2022
A pytorch implementation of Reading Wikipedia to Answer Open-Domain Questions.
DrQA A pytorch implementation of the ACL 2017 paper Reading Wikipedia to Answer Open-Domain Questions (DrQA). Reading comprehension is a task to produ
 394 Nov 8, 2022
394 Nov 8, 2022

Fetch is use to get information about anything on the shell using Wikipedia.
Fetch Search wikipedia article on command line [Why This?] [Support the Project] [Installation] [Configuration] Why this? Fetch helps you to quickly l
340 Dec 18, 2022

✨ Un chois aléatoire d'un article sur Wikipedia totalement fait en Python par moi, et en français.
Wikipedia Random Article ❗ Un chois aléatoire d'un article sur Wikipedia totalement fait en Python par moi, et en français. 🔮 Grâce a une requète a w
 4 Jul 18, 2021
4 Jul 18, 2021
SpikeX - SpaCy Pipes for Knowledge Extraction
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline. It aims to help in building knowledge extraction tools with almost-zero effort.
 384 Dec 12, 2022
384 Dec 12, 2022

Wikipedia Reader for the GNOME Desktop
Wike Wike is a Wikipedia reader for the GNOME Desktop. Provides access to all the content of this online encyclopedia in a native application, with a
 126 Dec 24, 2022
126 Dec 24, 2022
Text language identification using Wikipedia data
Text language identification using Wikipedia data The aim of this project is to provide high-quality language detection over all the web's languages.
 28 Jul 9, 2022
28 Jul 9, 2022

DensePhrases provides answers to your natural language questions from the entire Wikipedia in real-time
DensePhrases provides answers to your natural language questions from the entire Wikipedia in real-time. While it efficiently searches the answers out of 60 billion phrases in Wikipedia, it is also very accurate having competitive accuracy with state-of-the-art open-domain QA models
 543 Jan 8, 2023
543 Jan 8, 2023
A tool for extracting plain text from Wikipedia dumps
WikiExtractor WikiExtractor.py is a Python script that extracts and cleans text from a Wikipedia database dump. The tool is written in Python and requ
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
A Pythonic wrapper for the Wikipedia API
Wikipedia Wikipedia is a Python library that makes it easy to access and parse data from Wikipedia. Search Wikipedia, get article summaries, get data
 2.5k Dec 28, 2022
2.5k Dec 28, 2022
Python wrapper for Wikipedia
Wikipedia API Wikipedia-API is easy to use Python wrapper for Wikipedias' API. It supports extracting texts, sections, links, categories, translations
 369 Dec 30, 2022
369 Dec 30, 2022

Reading Wikipedia to Answer Open-Domain Questions
DrQA This is a PyTorch implementation of the DrQA system described in the ACL 2017 paper Reading Wikipedia to Answer Open-Domain Questions. Quick Link
 4.3k Jan 1, 2023
4.3k Jan 1, 2023