245 Repositories
Python word-error-rate Libraries

Automatic learning-rate scheduler
AutoLRS This is the PyTorch code implementation for the paper AutoLRS: Automatic Learning-Rate Schedule by Bayesian Optimization on the Fly published
 33 Nov 18, 2022
33 Nov 18, 2022
A Python script which randomly chooses and prints a file from a directory.
___ ____ ____ _ __ ___ / _ \ | _ \ | _ \ ___ _ __ | '__| / _ \ | |_| || | | || | | | / _ \| '__| | | | __/ | _ || |_| || |_| || __
 0 Aug 6, 2021
0 Aug 6, 2021
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022
Built on python (Mathematical straight fit line coordinates error predictor machine learning foundational model)
Sum-Square_Error-Business-Analytical-Tool- Built on python (Mathematical straight fit line coordinates error predictor machine learning foundational m
 1 Dec 3, 2021
1 Dec 3, 2021
Word and phrase lists in CSV
Word Lists Word and phrase lists in CSV, collected from different sources. Oxford Word Lists: oxford-5k.csv - Oxford 3000 and 5000 oxford-opal.csv - O
 14 Oct 14, 2022
14 Oct 14, 2022
Long Expressive Memory (LEM)
Long Expressive Memory for Sequence Modeling This repository contains the implementation to reproduce the numerical experiments of the paper Long Expr
 47 Dec 17, 2022
47 Dec 17, 2022

Prevent `CUDA error: out of memory` in just 1 line of code.
🐨 Koila Koila solves CUDA error: out of memory error painlessly. Fix it with just one line of code, and forget it. 🚀 Features 🙅 Prevents CUDA error
 1.7k Jan 2, 2023
1.7k Jan 2, 2023
AdamW optimizer and cosine learning rate annealing with restarts
AdamW optimizer and cosine learning rate annealing with restarts This repository contains an implementation of AdamW optimization algorithm and cosine
 133 Dec 20, 2022
133 Dec 20, 2022

Pytorch implementation of Learning Rate Dropout.
Learning-Rate-Dropout Pytorch implementation of Learning Rate Dropout. Paper Link: https://arxiv.org/pdf/1912.00144.pdf Train ResNet-34 for Cifar10: r
 42 Nov 25, 2022
42 Nov 25, 2022
Epidemiology analysis package
zEpid zEpid is an epidemiology analysis package, providing easy to use tools for epidemiologists coding in Python 3.5+. The purpose of this library is
 111 Jan 8, 2023
111 Jan 8, 2023
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
A Powerful Serverless Analysis Toolkit That Takes Trial And Error Out of Machine Learning Projects
KXY: A Seemless API to 10x The Productivity of Machine Learning Engineers Documentation https://www.kxy.ai/reference/ Installation From PyPi: pip inst
 35 Jan 2, 2023
35 Jan 2, 2023
Get informed when your DeFI Earn CRO Validator is jailed or changes the commission rate.
CRO-DeFi-Warner Intro CRO-DeFi-Warner can be used to notify you when a validator changes the commission rate or gets jailed. It can also notify you wh
 5 May 16, 2022
5 May 16, 2022

The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
 2 Nov 20, 2021
2 Nov 20, 2021

A TensorFlow Implementation of "Deep Multi-Scale Video Prediction Beyond Mean Square Error" by Mathieu, Couprie & LeCun.
Adversarial Video Generation This project implements a generative adversarial network to predict future frames of video, as detailed in "Deep Multi-Sc
 704 Nov 26, 2022
704 Nov 26, 2022
Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide
ssg-vale-rules-gen Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide. These rules are use
 1 Jan 13, 2022
1 Jan 13, 2022
A socket script to obtain chinese phones-sequence for any english word
Foreign Pronunciation Generator (English-Chinese) We provide a simple socket script for acquiring Chinese pronunciation of English words (phones in ai
 5 Jul 25, 2022
5 Jul 25, 2022
Hamming code generation, error detection & correction.
Hamming code generation, error detection & correction.
 2 Jun 30, 2022
2 Jun 30, 2022
RATE: Overcoming Noise and Sparsity of Textual Features in Real-Time Location Estimation (CIKM'17)
RATE: Overcoming Noise and Sparsity of Textual Features in Real-Time Location Estimation This is the implementation of RATE: Overcoming Noise and Spar
 5 Feb 10, 2022
5 Feb 10, 2022
This Project is based on NLTK It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
This Project is based on NLTK(Natural Language Toolkit) It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
 2 Nov 17, 2021
2 Nov 17, 2021
This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text.
Text Summarizer This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text. Team Members This mini-project was
 1 Nov 16, 2021
1 Nov 16, 2021
This repo is the code release of EMNLP 2021 conference paper "Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories".
Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories This repo is the code release of EMNLP 2021 con
 12 Nov 22, 2022
12 Nov 22, 2022

An open-source online reverse dictionary.
An open-source online reverse dictionary.
 6.3k Jan 9, 2023
6.3k Jan 9, 2023
Rates how pog a word or user is. Not random and does have *some* kind of algorithm to it.
PogRater :D Rates how pogchamp a word is :D A fun project coded by JBYT27 using Python3 Have you ever wondered how pog a word is? Well, congrats, you
 2 Jun 25, 2022
2 Jun 25, 2022
Simple Reddit bot that replies to comments containing a certain word.
reddit-replier-bot Small comment reply bot based on PRAW. This script will scan the comments of a subreddit as they come in and look for a trigger wor
 0 Jun 4, 2022
0 Jun 4, 2022
🌸 fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
floret: fastText + Bloom embeddings for compact, full-coverage vectors with spaCy floret is an extended version of fastText that can produce word repr
 222 Dec 16, 2022
222 Dec 16, 2022

WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region. This repository provides the codebase and dataset for our work WORD: Revisiting Or
 71 Jan 7, 2023
71 Jan 7, 2023
Interpretable-contrastive-word-mover-s-embedding
Interpretable-contrastive-word-mover-s-embedding Paper Datasets Here is a Dropbox link to the datasets used in the paper: https://www.dropbox.com/sh/n
 0 Nov 2, 2021
0 Nov 2, 2021
System Combination for Grammatical Error Correction Based on Integer Programming
System Combination for Grammatical Error Correction Based on Integer Programming This repository contains the code and scripts that implement the syst
 0 Mar 29, 2022
0 Mar 29, 2022

Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch
Next Word Prediction Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch 🎬 Project Demo ✔ Application is hosted on Streamlit. You can see t
 3 Aug 26, 2022
3 Aug 26, 2022
This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user
max_tweeted_word This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user The program uses twe
 1 Nov 29, 2021
1 Nov 29, 2021
Japanese Long-Unit-Word Tokenizer with RemBertTokenizerFast of Transformers
Japanese-LUW-Tokenizer Japanese Long-Unit-Word (国語研長単位) Tokenizer for Transformers based on 青空文庫 Basic Usage from transformers import RemBertToken
 3 Dec 22, 2021
3 Dec 22, 2021
The codes of paper 'Active-LATHE: An Active Learning Algorithm for Boosting the Error exponent for Learning Homogeneous Ising Trees'
Active-LATHE: An Active Learning Algorithm for Boosting the Error exponent for Learning Homogeneous Ising Trees This project contains the codes of pap
 0 Apr 20, 2022
0 Apr 20, 2022

A Pytorch Implementation of a continuously rate adjustable learned image compression framework.
GainedVAE A Pytorch Implementation of a continuously rate adjustable learned image compression framework, Gained Variational Autoencoder(GainedVAE). N
 39 Dec 24, 2022
39 Dec 24, 2022
Count the frequency of letters or words in a text file and show a graph.
Word Counter By EBUS Coding Club Count the frequency of letters or words in a text file and show a graph. Requirements Python 3.9 or higher matplotlib
 0 Apr 9, 2022
0 Apr 9, 2022
Chinese Grammatical Error Diagnosis
nlp-CGED Chinese Grammatical Error Diagnosis 中文语法纠错研究 基于序列标注的方法 所需环境 Python==3.6 tensorflow==1.14.0 keras==2.3.1 bert4keras==0.10.6 笔者使用了开源的bert4keras
 12 Nov 25, 2022
12 Nov 25, 2022
CBREN: Convolutional Neural Networks for Constant Bit Rate Video Quality Enhancement
CBREN This is the Pytorch implementation for our IEEE TCSVT paper : CBREN: Convolutional Neural Networks for Constant Bit Rate Video Quality Enhanceme
 3 Nov 4, 2022
3 Nov 4, 2022
Implicit hierarchical a posteriori error estimates in FEniCSx
FEniCSx Error Estimation (FEniCSx-EE) Description FEniCSx-EE is an open source library showing how various error estimation strategies can be implemen
 1 Dec 8, 2021
1 Dec 8, 2021
Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR
Speech_38_ru_commands Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR Программа умеет распознавать 38 ключевы
 9 May 5, 2022
9 May 5, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022
On-device wake word detection powered by deep learning.
Porcupine Made in Vancouver, Canada by Picovoice Porcupine is a highly-accurate and lightweight wake word engine. It enables building always-listening
 2.8k Dec 29, 2022
2.8k Dec 29, 2022

The implementation of the submitted paper "Deep Multi-Behaviors Graph Network for Voucher Redemption Rate Prediction" in SIGKDD 2021 Applied Data Science Track.
DMBGN: Deep Multi-Behaviors Graph Networks for Voucher Redemption Rate Prediction The implementation of the accepted paper "Deep Multi-Behaviors Graph
 10 Jul 12, 2022
10 Jul 12, 2022
Official implementation of "Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform", ICCV 2021
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform This repository is the implementation of "Variable-Rate Deep Image C
 47 Dec 13, 2022
47 Dec 13, 2022
 2 Jan 28, 2022
2 Jan 28, 2022
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
 79 Dec 27, 2022
79 Dec 27, 2022

Propose a principled and practically effective framework for unsupervised accuracy estimation and error detection tasks with theoretical analysis and state-of-the-art performance.
Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles This project is for the paper: Detecting Errors and Estimating
 13 Nov 21, 2022
13 Nov 21, 2022

Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordcloud packages
Wikipedia WordCloud App Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordclou
 5 Jan 2, 2022
5 Jan 2, 2022

Disease Informed Neural Networks (DINNs) — neural networks capable of learning how diseases spread, forecasting their progression, and finding their unique parameters (e.g. death rate).
DINN We introduce Disease Informed Neural Networks (DINNs) — neural networks capable of learning how diseases spread, forecasting their progression, a
 19 Dec 10, 2022
19 Dec 10, 2022
MEDS: Enhancing Memory Error Detection for Large-Scale Applications
MEDS: Enhancing Memory Error Detection for Large-Scale Applications Prerequisites cmake and clang Build MEDS supporting compiler $ make Build Using Do
 34 Dec 14, 2022
34 Dec 14, 2022
Alarmer is a tool focus on error reporting for your application.
alarmer Alarmer is a tool focus on error reporting for your application. Installation pip install alarmer Usage It's simple to integrate alarmer in yo
 20 Jul 3, 2022
20 Jul 3, 2022
Telegram Group Management Bot based on phython !!!
How to setup/deploy. For easiest way to deploy this Bot click on the below button Mᴀᴅᴇ Bʏ Sᴜᴘᴘᴏʀᴛ Sᴏᴜʀᴄᴇ Find This Bot on Telegram A modular Telegram
 5 Nov 17, 2021
5 Nov 17, 2021
split Word file by chapter
split Word file by chapter we use the mircosoft word api to code this tool api url:https://docs.microsoft.com/zh-cn/dotnet/api/ if this tool is good f
 5 Nov 6, 2021
5 Nov 6, 2021

On the Variance of the Adaptive Learning Rate and Beyond
RAdam On the Variance of the Adaptive Learning Rate and Beyond We are in an early-release beta. Expect some adventures and rough edges. Table of Conte
 2.5k Dec 27, 2022
2.5k Dec 27, 2022
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming. Outperforming `GPT-3` on SuperGLUE Few-Shot text classification.
 75 Nov 6, 2022
75 Nov 6, 2022

A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
 201 Nov 9, 2022
201 Nov 9, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
A meme error handler for python
Pwython OwO what's this? Pwython is project aiming to fill in one of the biggest problems with python, which is that it is slow lacks owoified text. N
 23 Jan 15, 2022
23 Jan 15, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022
Sentry is cross-platform application monitoring, with a focus on error reporting.
Users and logs provide clues. Sentry provides answers. What's Sentry? Sentry is a service that helps you monitor and fix crashes in realtime. The serv
 32.9k Dec 31, 2022
32.9k Dec 31, 2022
![[EMNLP 2021] LM-Critic: Language Models for Unsupervised Grammatical Error Correction](https://github.com/michiyasunaga/LM-Critic/raw/main/figs/local_optimality.png)
[EMNLP 2021] LM-Critic: Language Models for Unsupervised Grammatical Error Correction
LM-Critic: Language Models for Unsupervised Grammatical Error Correction This repo provides the source code & data of our paper: LM-Critic: Language M
 98 Nov 24, 2022
98 Nov 24, 2022
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
79 Dec 27, 2022

MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving.
MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving. It is a comprehensive framework for research purpose that integrates popular MWP benchmark datasets and typical deep learning-based MWP algorithms.
 119 Jan 4, 2023
119 Jan 4, 2023
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022

Graph-based community clustering approach to extract protein domains from a predicted aligned error matrix
Using a predicted aligned error matrix corresponding to an AlphaFold2 model , returns a series of lists of residue indices, where each list corresponds to a set of residues clustering together into a pseudo-rigid domain.
 24 Nov 23, 2022
24 Nov 23, 2022
从flomo导出的笔记中生成词云
flomo-word-cloud 从flomo导出的笔记中生成词云 如何使用? 将本项目克隆到你的电脑上,使用如下的命令,安装所需python库 pip install -r requirements.txt 在项目里新建一个file文件夹,把所有从flomo导出的html文件放入其中 运行main
 9 Dec 30, 2022
9 Dec 30, 2022
pydantic-i18n is an extension to support an i18n for the pydantic error messages.
pydantic-i18n is an extension to support an i18n for the pydantic error messages
 48 Dec 21, 2022
48 Dec 21, 2022
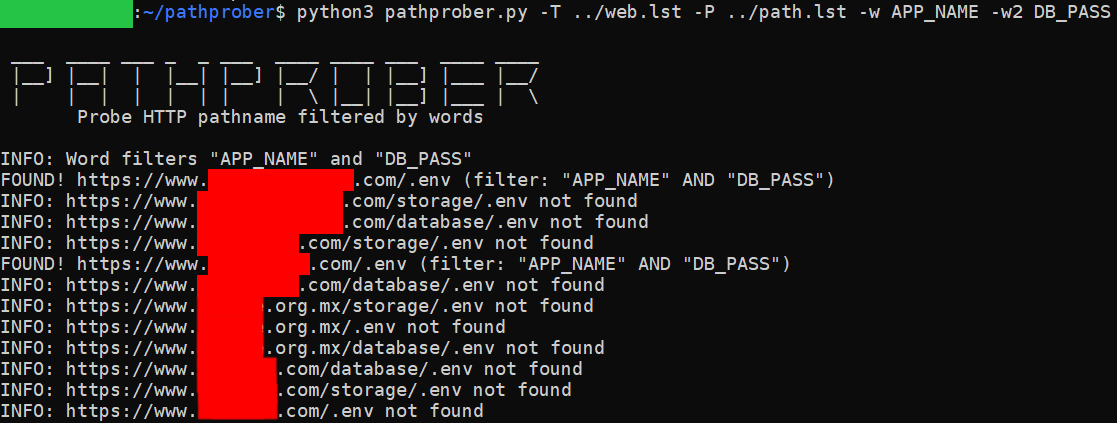
Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once
pathprober Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once. Purpose Brute-forcing webs
 41 Jul 6, 2022
41 Jul 6, 2022

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
114 Nov 4, 2022
A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
201 Nov 9, 2022

Automatically find solutions when your Python code encounters an issue.
What The Python?! Helping you find answers to the errors Python spits out. Installation You can find the source code on GitHub at: https://github.com/
 139 Dec 14, 2022
139 Dec 14, 2022

Pandas and Dask test helper methods with beautiful error messages.
beavis Pandas and Dask test helper methods with beautiful error messages. test helpers These test helper methods are meant to be used in test suites.
 18 Nov 28, 2022
18 Nov 28, 2022
A FastAPI Framework for things like Database, Redis, Logging, JWT Authentication and Rate Limits
A FastAPI Framework for things like Database, Redis, Logging, JWT Authentication and Rate Limits Install You can install this Library with: pip instal
 33 Nov 28, 2022
33 Nov 28, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022
PyTorch impelementations of BERT-based Spelling Error Correction Models
PyTorch impelementations of BERT-based Spelling Error Correction Models
 59 Jun 29, 2021
59 Jun 29, 2021
PyTorch impelementations of BERT-based Spelling Error Correction Models.
PyTorch impelementations of BERT-based Spelling Error Correction Models. 基于BERT的文本纠错模型,使用PyTorch实现。
209 Dec 30, 2022
ToR[e]cSys is a PyTorch Framework to implement recommendation system algorithms
ToR[e]cSys is a PyTorch Framework to implement recommendation system algorithms, including but not limited to click-through-rate (CTR) prediction, learning-to-ranking (LTR), and Matrix/Tensor Embedding. The project objective is to develop a ecosystem to experiment, share, reproduce, and deploy in real world in a smooth and easy way (Hope it can be done).
 90 Oct 8, 2022
90 Oct 8, 2022

Official NumPy Implementation of Deep Networks from the Principle of Rate Reduction (2021)
Deep Networks from the Principle of Rate Reduction This repository is the official NumPy implementation of the paper Deep Networks from the Principle
 49 Dec 16, 2022
49 Dec 16, 2022
Code for the ACL2021 paper "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction"
CSCBLI Code for our ACL Findings 2021 paper, "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction". Require
 12 Oct 8, 2022
12 Oct 8, 2022
Code for Graph-to-Tree Learning for Solving Math Word Problems (ACL 2020)
Graph-to-Tree Learning for Solving Math Word Problems PyTorch implementation of Graph based Math Word Problem solver described in our ACL 2020 paper G
 66 Nov 23, 2022
66 Nov 23, 2022

Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
 78 Aug 23, 2022
78 Aug 23, 2022
Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021)
L1-Refinement Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021) 🙈 A more detailed readme is co
 4 Jun 9, 2021
4 Jun 9, 2021

A framework for detecting, highlighting and correcting grammatical errors on natural language text.
Gramformer Human and machine generated text often suffer from grammatical and/or typographical errors. It can be spelling, punctuation, grammatical or
 1.3k Jan 8, 2023
1.3k Jan 8, 2023
Package pyVHR is a comprehensive framework for studying methods of pulse rate estimation relying on remote photoplethysmography (rPPG)
Package pyVHR (short for Python framework for Virtual Heart Rate) is a comprehensive framework for studying methods of pulse rate estimation relying on remote photoplethysmography (rPPG)
 261 Jan 3, 2023
261 Jan 3, 2023

PyTorch implementation of some learning rate schedulers for deep learning researcher.
pytorch-lr-scheduler PyTorch implementation of some learning rate schedulers for deep learning researcher. Usage WarmupReduceLROnPlateauScheduler Visu
 59 Dec 8, 2022
59 Dec 8, 2022

Code for our paper "Mask-Align: Self-Supervised Neural Word Alignment" in ACL 2021
Mask-Align: Self-Supervised Neural Word Alignment This is the implementation of our work Mask-Align: Self-Supervised Neural Word Alignment. @inproceed
 46 Dec 15, 2022
46 Dec 15, 2022

PyTorch implementation of the paper Deep Networks from the Principle of Rate Reduction
Deep Networks from the Principle of Rate Reduction This repository is the official PyTorch implementation of the paper Deep Networks from the Principl
 459 Dec 27, 2022
459 Dec 27, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022

A library for Multilingual Unsupervised or Supervised word Embeddings
MUSE: Multilingual Unsupervised and Supervised Embeddings MUSE is a Python library for multilingual word embeddings, whose goal is to provide the comm
 3k Jan 6, 2023
3k Jan 6, 2023
Official repository for Jia, Raghunathan, Göksel, and Liang, "Certified Robustness to Adversarial Word Substitutions" (EMNLP 2019)
Certified Robustness to Adversarial Word Substitutions This is the official GitHub repository for the following paper: Certified Robustness to Adversa
 38 Oct 16, 2022
38 Oct 16, 2022

Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation This is the official repository for our paper Neural Reprojection Error
 78 Dec 1, 2022
78 Dec 1, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
Code for paper "A Critical Assessment of State-of-the-Art in Entity Alignment" (https://arxiv.org/abs/2010.16314)
A Critical Assessment of State-of-the-Art in Entity Alignment This repository contains the source code for the paper A Critical Assessment of State-of
 16 Oct 14, 2022
16 Oct 14, 2022
API Rate Limit Decorator
ratelimit APIs are a very common way to interact with web services. As the need to consume data grows, so does the number of API calls necessary to re
 575 Jan 5, 2023
575 Jan 5, 2023

Implementation of "Meta-rPPG: Remote Heart Rate Estimation Using a Transductive Meta-Learner"
Meta-rPPG: Remote Heart Rate Estimation Using a Transductive Meta-Learner This repository is the official implementation of Meta-rPPG: Remote Heart Ra
 137 Dec 13, 2022
137 Dec 13, 2022

This is a c++ project deploying a deep scene text reading pipeline with tensorflow. It reads text from natural scene images. It uses frozen tensorflow graphs. The detector detect scene text locations. The recognizer reads word from each detected bounding box.
DeepSceneTextReader This is a c++ project deploying a deep scene text reading pipeline. It reads text from natural scene images. Prerequsites The proj
 49 Sep 10, 2022
49 Sep 10, 2022

Deep Learning Chinese Word Segment
引用 本项目模型BiLSTM+CRF参考论文:http://www.aclweb.org/anthology/N16-1030 ,IDCNN+CRF参考论文:https://arxiv.org/abs/1702.02098 构建 安装好bazel代码构建工具,安装好tensorflow(目前本项目需
 2.1k Dec 23, 2022
2.1k Dec 23, 2022