Filter By
1361 Repositories
Python Text Data & NLP
VoiceFixer VoiceFixer is a framework for general speech restoration.
VoiceFixer VoiceFixer is a framework for general speech restoration. We aim at the restoration of severly degraded speech and historical speech. Paper
 174 Jan 6, 2023
174 Jan 6, 2023
Compute distance between sequences. 30+ algorithms, pure python implementation, common interface, optional external libs usage.
TextDistance TextDistance -- python library for comparing distance between two or more sequences by many algorithms. Features: 30+ algorithms Pure pyt
 3k Jan 6, 2023
3k Jan 6, 2023
jel - Japanese Entity Linker - is Bi-encoder based entity linker for japanese.
jel: Japanese Entity Linker jel - Japanese Entity Linker - is Bi-encoder based entity linker for japanese. Usage Currently, link and question methods
 10 Jan 6, 2023
10 Jan 6, 2023

Trankit is a Light-Weight Transformer-based Python Toolkit for Multilingual Natural Language Processing
Trankit: A Light-Weight Transformer-based Python Toolkit for Multilingual Natural Language Processing Trankit is a light-weight Transformer-based Pyth
 652 Jan 6, 2023
652 Jan 6, 2023

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
 142 Jan 6, 2023
142 Jan 6, 2023

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
 1.9k Jan 6, 2023
1.9k Jan 6, 2023

ChainKnowledgeGraph, 产业链知识图谱包括A股上市公司、行业和产品共3类实体
ChainKnowledgeGraph, 产业链知识图谱包括A股上市公司、行业和产品共3类实体,包括上市公司所属行业关系、行业上级关系、产品上游原材料关系、产品下游产品关系、公司主营产品、产品小类共6大类。 上市公司4,654家,行业511个,产品95,559条、上游材料56,824条,上级行业480条,下游产品390条,产品小类52,937条,所属行业3,946条。
 415 Jan 6, 2023
415 Jan 6, 2023

Generate text line images for training deep learning OCR model (e.g. CRNN)
Generate text line images for training deep learning OCR model (e.g. CRNN)
 532 Jan 6, 2023
532 Jan 6, 2023

Clone a voice in 5 seconds to generate arbitrary speech in real-time
This repository is forked from Real-Time-Voice-Cloning which only support English. English | 中文 Features 🌍 Chinese supported mandarin and tested with
 25.6k Jan 6, 2023
25.6k Jan 6, 2023
Easy to use, state-of-the-art Neural Machine Translation for 100+ languages
EasyNMT - Easy to use, state-of-the-art Neural Machine Translation This package provides easy to use, state-of-the-art machine translation for more th
 748 Jan 6, 2023
748 Jan 6, 2023

iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
 435 Jan 6, 2023
435 Jan 6, 2023
Guide: Finetune GPT2-XL (1.5 Billion Parameters) and GPT-NEO (2.7 B) on a single 16 GB VRAM V100 Google Cloud instance with Huggingface Transformers using DeepSpeed
Guide: Finetune GPT2-XL (1.5 Billion Parameters) and GPT-NEO (2.7 Billion Parameters) on a single 16 GB VRAM V100 Google Cloud instance with Huggingfa
 289 Jan 6, 2023
289 Jan 6, 2023

A library for Multilingual Unsupervised or Supervised word Embeddings
MUSE: Multilingual Unsupervised and Supervised Embeddings MUSE is a Python library for multilingual word embeddings, whose goal is to provide the comm
 3k Jan 6, 2023
3k Jan 6, 2023
NeuTex: Neural Texture Mapping for Volumetric Neural Rendering
NeuTex: Neural Texture Mapping for Volumetric Neural Rendering Paper: https://arxiv.org/abs/2103.00762 Running Run on the provided DTU scene cd run ba
 68 Jan 6, 2023
68 Jan 6, 2023

Implementation of Memorizing Transformers (ICLR 2022), attention net augmented with indexing and retrieval of memories using approximate nearest neighbors, in Pytorch
Memorizing Transformers - Pytorch Implementation of Memorizing Transformers (ICLR 2022), attention net augmented with indexing and retrieval of memori
 364 Jan 6, 2023
364 Jan 6, 2023
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 44 Jan 6, 2023
44 Jan 6, 2023

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization
 99 Jan 6, 2023
99 Jan 6, 2023
Signature remover is a NLP based solution which removes email signatures from the rest of the text.
Signature Remover Signature remover is a NLP based solution which removes email signatures from the rest of the text. It helps to enchance data conten
 8 Jan 6, 2023
8 Jan 6, 2023

A modular Karton Framework service that unpacks common packers like UPX and others using the Qiling Framework.
Unpacker Karton Service A modular Karton Framework service that unpacks common packers like UPX and others using the Qiling Framework. This project is
 45 Jan 5, 2023
45 Jan 5, 2023
Library for fast text representation and classification.
fastText fastText is a library for efficient learning of word representations and sentence classification. Table of contents Resources Models Suppleme
24.1k Jan 5, 2023
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 3k Jan 5, 2023
3k Jan 5, 2023

⚡ boost inference speed of T5 models by 5x & reduce the model size by 3x using fastT5.
Reduce T5 model size by 3X and increase the inference speed up to 5X. Install Usage Details Functionalities Benchmarks Onnx model Quantized onnx model
 399 Jan 5, 2023
399 Jan 5, 2023
A Japanese tokenizer based on recurrent neural networks
Nagisa is a python module for Japanese word segmentation/POS-tagging. It is designed to be a simple and easy-to-use tool. This tool has the following
 325 Jan 5, 2023
325 Jan 5, 2023

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023
Yet Another Neural Machine Translation Toolkit
YANMTT YANMTT is short for Yet Another Neural Machine Translation Toolkit. For a backstory how I ended up creating this toolkit scroll to the bottom o
 121 Jan 5, 2023
121 Jan 5, 2023
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
 13.6k Jan 5, 2023
13.6k Jan 5, 2023
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023

Local cross-platform machine translation GUI, based on CTranslate2
DesktopTranslator Local cross-platform machine translation GUI, based on CTranslate2 Download Windows Installer You can either download a ready-made W
 29 Jan 5, 2023
29 Jan 5, 2023
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023

GrammarTagger — A Neural Multilingual Grammar Profiler for Language Learning
GrammarTagger — A Neural Multilingual Grammar Profiler for Language Learning GrammarTagger is an open-source toolkit for grammatical profiling for lan
 27 Jan 5, 2023
27 Jan 5, 2023
Code release for NeX: Real-time View Synthesis with Neural Basis Expansion
NeX: Real-time View Synthesis with Neural Basis Expansion Project Page | Video | Paper | COLAB | Shiny Dataset We present NeX, a new approach to novel
 537 Jan 5, 2023
537 Jan 5, 2023
Russian GPT3 models.
Russian GPT-3 models (ruGPT3XL, ruGPT3Large, ruGPT3Medium, ruGPT3Small) trained with 2048 sequence length with sparse and dense attention blocks. We also provide Russian GPT-2 large model (ruGPT2Large) trained with 1024 sequence length.
 1.6k Jan 5, 2023
1.6k Jan 5, 2023

The RWKV Language Model
RWKV-LM We propose the RWKV language model, with alternating time-mix and channel-mix layers: The R, K, V are generated by linear transforms of input,
 877 Jan 5, 2023
877 Jan 5, 2023
A program that uses real statistics to choose the best times to bet on BloxFlip's crash gamemode
Bloxflip Smart Bet A program that uses real statistics to choose the best times to bet on BloxFlip's crash gamemode. https://bloxflip.com/crash. THIS
 43 Jan 5, 2023
43 Jan 5, 2023

⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
Translations 🇩🇪 DE 🇫🇷 FR 🇭🇺 HU 🇮🇩 ID 🇮🇹 IT 🇳🇱 NL 🇧🇷 PT-BR 🇷🇺 RU 🇨🇳 ZH ➡️ Documentation | Discord | Installation Guide ⬅️ Fully autom
 11.2k Jan 5, 2023
11.2k Jan 5, 2023
NLP made easy
GluonNLP: Your Choice of Deep Learning for NLP GluonNLP is a toolkit that helps you solve NLP problems. It provides easy-to-use tools that helps you l
 2.5k Jan 4, 2023
2.5k Jan 4, 2023

Py65 65816 - Add support for the 65C816 to py65
Add support for the 65C816 to py65 Py65 (https://github.com/mnaberez/py65) is a
 4 Jan 4, 2023
4 Jan 4, 2023
Open Source Neural Machine Translation in PyTorch
OpenNMT-py: Open-Source Neural Machine Translation OpenNMT-py is the PyTorch version of the OpenNMT project, an open-source (MIT) neural machine trans
 5.8k Jan 4, 2023
5.8k Jan 4, 2023

A Python/Pytorch app for easily synthesising human voices
Voice Cloning App A Python/Pytorch app for easily synthesising human voices Documentation Discord Server Video guide Voice Sharing Hub FAQ's System Re
 840 Jan 4, 2023
840 Jan 4, 2023

A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
 335 Jan 4, 2023
335 Jan 4, 2023
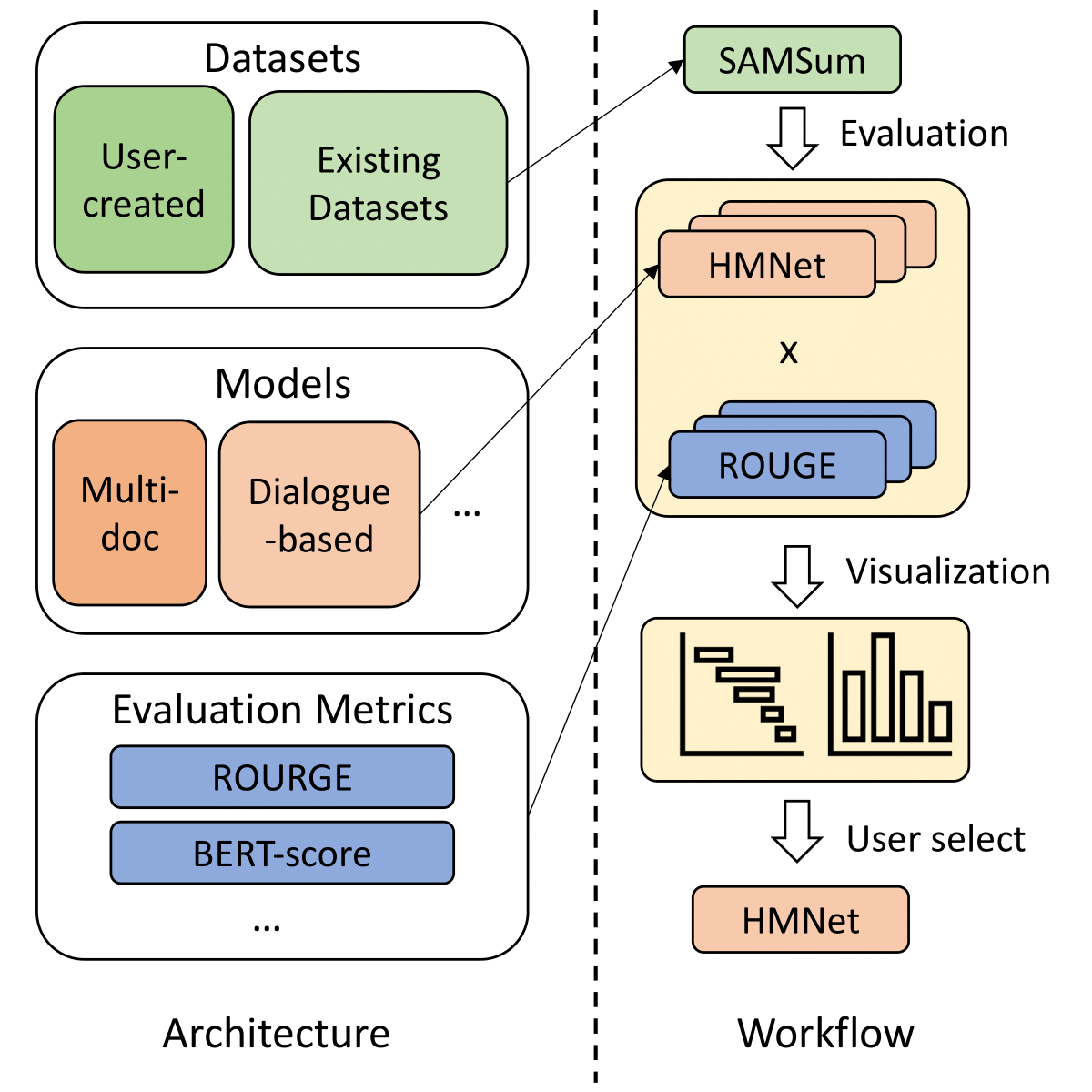
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

voice2json is a collection of command-line tools for offline speech/intent recognition on Linux
Command-line tools for speech and intent recognition on Linux
 988 Jan 4, 2023
988 Jan 4, 2023

PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI
data2vec-pytorch PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI (F
 105 Jan 4, 2023
105 Jan 4, 2023
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset.
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset. Through its Python API, the pretrained model can be fine-tuned on any protein-related task in a matter of minutes. Based on our experiments with a wide range of benchmarks, ProteinBERT usually achieves state-of-the-art performance. ProteinBERT is built on TenforFlow/Keras.
 241 Jan 4, 2023
241 Jan 4, 2023

🚀 RocketQA, dense retrieval for information retrieval and question answering, including both Chinese and English state-of-the-art models.
In recent years, the dense retrievers based on pre-trained language models have achieved remarkable progress. To facilitate more developers using cutt
 475 Jan 4, 2023
475 Jan 4, 2023

Plugin repository for Macast
Macast-plugins Plugin repository for Macast. How to use third-party player plugin Download Macast from GitHub Release. Download the plugin you want fr
 109 Jan 4, 2023
109 Jan 4, 2023
NeMo: a toolkit for conversational AI
NVIDIA NeMo Introduction NeMo is a toolkit for creating Conversational AI applications. NeMo product page. Introductory video. The toolkit comes with
 5.3k Jan 4, 2023
5.3k Jan 4, 2023
FireFlyer Record file format, writer and reader for DL training samples.
FFRecord The FFRecord format is a simple format for storing a sequence of binary records developed by HFAiLab, which supports random access and Linux
 77 Jan 4, 2023
77 Jan 4, 2023

A multi-lingual approach to AllenNLP CoReference Resolution along with a wrapper for spaCy.
Crosslingual Coreference Coreference is amazing but the data required for training a model is very scarce. In our case, the available training for non
 71 Jan 4, 2023
71 Jan 4, 2023

 387 Jan 4, 2023
387 Jan 4, 2023

NLP project that works with news (NER, context generation, news trend analytics)
СоАвтор СоАвтор – платформа и открытый набор инструментов для редакций и журналистов-фрилансеров, который призван сделать процесс создания контента ма
 38 Jan 4, 2023
38 Jan 4, 2023
Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models.
Tevatron Tevatron is a simple and efficient toolkit for training and running dense retrievers with deep language models. The toolkit has a modularized
 193 Jan 4, 2023
193 Jan 4, 2023