Prisma Client Python
Type-safe database access for Python



What is Prisma Client Python?
Prisma Client Python is an unofficial implementation of Prisma which is a next-generation ORM that comes bundled with tools, such as Prisma Migrate, which make working with databases as easy as possible.
Prisma Client Python can be used in any Python backend application. This can be a REST API, a GraphQL API or anything else that needs a database.
Why should you use Prisma Client Python?
Unlike other Python ORMs, Prisma Client Python is fully type safe and offers native support for usage with and without async. All you have to do is specify the type of client you would like to use for your project in the Prisma schema file.
Core features:
- Full type safety
- With / without async
- Recursive and pseudo-recursive types
- Atomic updates
- Complex cross-relational queries
- Partial type generation
- Batching write queries
Supported database providers:
- PostgreSQL
- MySQL
- SQLite
- MongoDB (experimental)
- SQL Server (experimental)
How does Prisma work?
This section provides a high-level overview of how Prisma works and its most important technical components. For a more thorough introduction, visit the documentation.
The Prisma schema
Every project that uses a tool from the Prisma toolkit starts with a Prisma schema file. The Prisma schema allows developers to define their application models in an intuitive data modeling language. It also contains the connection to a database and defines a generator:
// database
datasource db {
provider = "sqlite"
url = "file:database.db"
}
// generator
generator client {
provider = "prisma-client-py"
}
// data models
model Post {
id Int @id @default(autoincrement())
title String
content String?
views Int @default(0)
published Boolean @default(false)
author User? @relation(fields: [author_id], references: [id])
author_id Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
In this schema, you configure three things:
- Data source: Specifies your database connection. In this case we use a local SQLite database however you can also use an environment variable.
- Generator: Indicates that you want to generate Prisma Client Python.
- Data models: Defines your application models.
On this page, the focus is on the generator as this is the only part of the schema that is specific to Prisma Client Python. You can learn more about Data sources and Data models on their respective documentation pages.
Prisma generator
A prisma schema can define one or more generators, defined by the generator block.
A generator determines what assets are created when you run the prisma generate command. The provider value defines which Prisma Client will be created. In this case, as we want to generate Prisma Client Python, we use the prisma-client-py value.
You can also define where the client will be generated to with the output option. By default Prisma Client Python will be generated to the same location it was installed to, whether thats inside a virtual environment, the global python installation or anywhere else that python packages can be imported from.
For more options see configuring Prisma Client Python.
Accessing your database with Prisma Client Python
Just want to play around with Prisma Client Python and not worry about any setup? You can try it out online on gitpod.
Installing Prisma Client Python
The first step with any python project should be to setup a virtual environment to isolate installed packages from your other python projects, however that is out of the scope for this page.
In this example we'll use an asynchronous client, if you would like to use a synchronous client see setting up a synchronous client.
pip install -U prisma
Generating Prisma Client Python
Now that we have Prisma Client Python installed we need to actually generate the client to be able to access the database.
Copy the Prisma schema file shown above to a schema.prisma file in the root directory of your project and run:
prisma db push
This command will add the data models to your database and generate the client, you should see something like this:
Prisma schema loaded from schema.prisma
Datasource "db": SQLite database "database.db" at "file:database.db"
SQLite database database.db created at file:database.db
🚀 Your database is now in sync with your schema. Done in 26ms
✔ Generated Prisma Client Python to ./.venv/lib/python3.9/site-packages/prisma in 265ms
It should be noted that whenever you make changes to your schema.prisma file you will have to re-generate the client, you can do this automatically by running prisma generate --watch.
The simplest asynchronous Prisma Client Python application looks something like this:
import asyncio
from prisma import Client
async def main() -> None:
client = Client()
await client.connect()
# write your queries here
await client.disconnect()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
Query examples
For a more complete list of queries you can perform with Prisma Client Python see the documentation.
All query methods return pydantic models.
Retrieve all User records from the database
users = await client.user.find_many()
Include the posts relation on each returned User object
users = await client.user.find_many(
include={
'posts': True,
},
)
Retrieve all Post records that contain "prisma"
posts = await client.post.find_many(
where={
'OR': [
{'title': {'contains': 'prisma'}},
{'content': {'contains': 'prisma'}},
]
}
)
Create a new User and a new Post record in the same query
user = await client.user.create(
data={
'name': 'Robert',
'email': '[email protected]',
'posts': {
'create': {
'title': 'My first post from Prisma!',
},
},
},
)
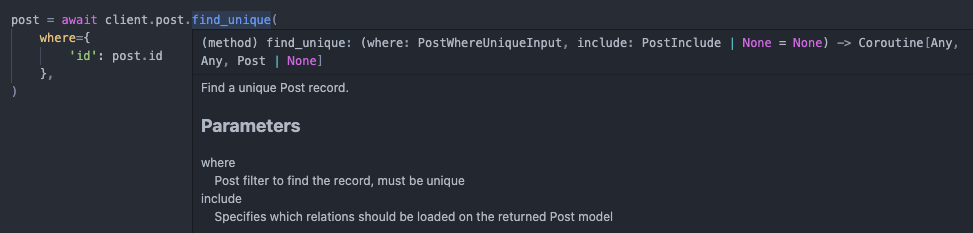
Update an existing Post record
post = await client.post.update(
where={
'id': 42,
},
data={
'views': {
'increment': 1,
},
},
)
Usage with static type checkers
All Prisma Client Python methods are fully statically typed, this means you can easily catch bugs in your code without having to run it!
For more details see the documentation.
Room for improvement
Prisma Client Python is a new project and as such there are some features that are missing or incomplete.
Auto completion for query arguments
Prisma Client Python query arguments make use of TypedDict types. While there is very limited support for completion of these types within the Python ecosystem some editors do support it.
Supported editors / extensions:
- VSCode with pylance v2021.9.4 or higher
- Sublime Text with LSP-Pyright v1.1.96 or higher
user = await client.user.find_first(
where={
'|'
}
)
Given the cursor is where the | is, an IDE should suggest the following completions:
- id
- name
- posts
Performance
There has currently not been any work done on improving the performance of Prisma Client Python queries, this is something that will be worked on in the future and there is room for massive improvements.
Supported platforms
Only MacOS and Linux are officially supported.
Windows is unofficially supported as tests are not currently ran on windows.
Version guarantees
Prisma Client Python is not stable.
Breaking changes will be documented and released under a new MINOR version following this format.
MAJOR.MINOR.PATCH
Contributing
We use conventional commits (also known as semantic commits) to ensure consistent and descriptive commit messages.
See the contributing documentation for more information.
Attributions
This project would not be possible without the work of the amazing folks over at prisma.
Massive h/t to @steebchen for his work on prisma-client-go which was incredibly helpful in the creation of this project.
This README is also heavily inspired by the README in the prisma/prisma repository.














 9.1k Dec 31, 2022
9.1k Dec 31, 2022
 436 Nov 10, 2022
436 Nov 10, 2022
 1.2k Jan 5, 2023
1.2k Jan 5, 2023
 67 Sep 1, 2022
67 Sep 1, 2022
 281 Nov 10, 2022
281 Nov 10, 2022
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
 993 Jan 3, 2023
993 Jan 3, 2023
 1 Nov 21, 2021
1 Nov 21, 2021
 18 Dec 1, 2022
18 Dec 1, 2022
 3 Apr 13, 2022
3 Apr 13, 2022
 4.2k Dec 26, 2022
4.2k Dec 26, 2022
 9.7k Jan 8, 2023
9.7k Jan 8, 2023
 919 Jan 4, 2023
919 Jan 4, 2023
 13 Oct 14, 2022
13 Oct 14, 2022
 32 Dec 28, 2022
32 Dec 28, 2022
 6 Apr 6, 2022
6 Apr 6, 2022
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
 6 Mar 31, 2022
6 Mar 31, 2022
 68 Oct 19, 2022
68 Oct 19, 2022