PeeledHuman: Robust Shape Representation for Textured 3D Human Body Reconstruction
International Conference on 3D Vision, 2020
1Center for Visual Information Technology, IIIT Hyderabad
Abstract
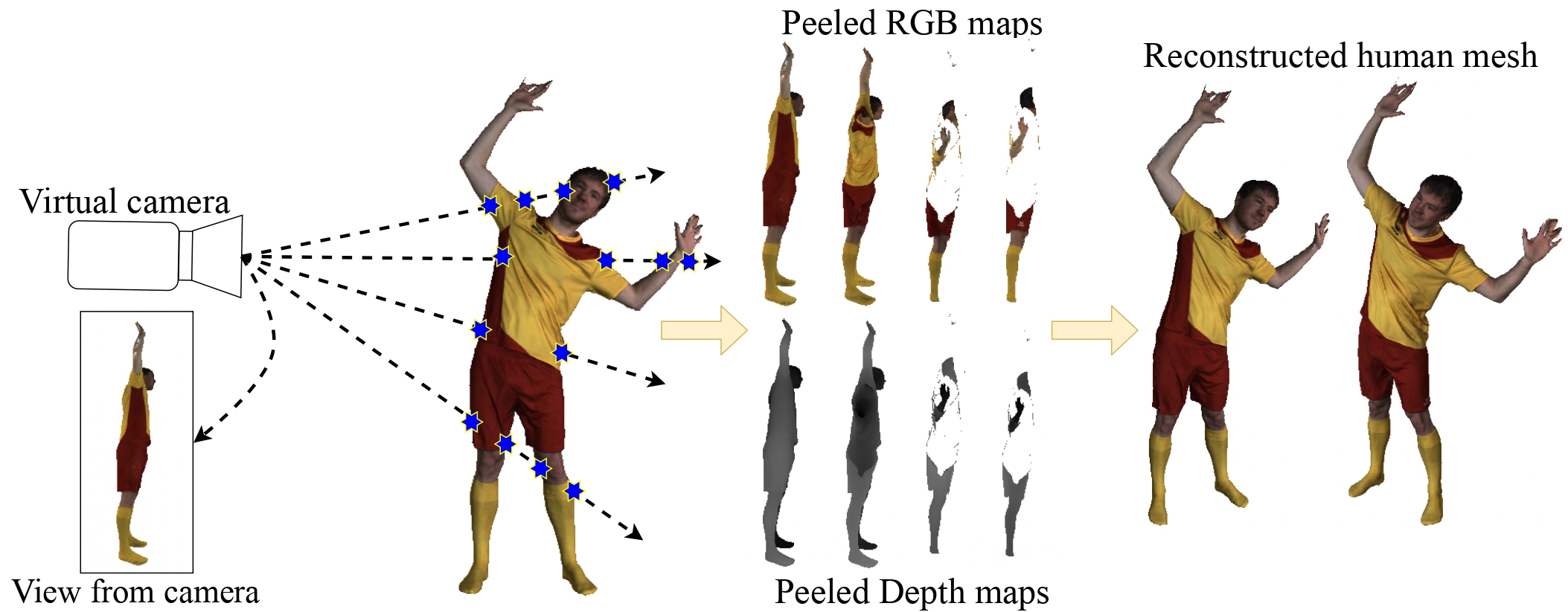
We introduce PeeledHuman - a novel shape representation of the human body that is robust to self-occlusions. PeeledHuman encodes the human body as a set of Peeled Depth and RGB maps in 2D, obtained by performing raytracing on the 3D body model and extending each ray beyond its first intersection. This formulation allows us to handle self-occlusions efficiently compared to other representations. Given a monocular RGB image, we learn these Peeled maps in an end-to-end generative adversarial fashion using our novel framework - PeelGAN. We train PeelGAN using a 3D Chamfer loss and other 2D losses to generate multiple depth values per-pixel and a corresponding RGB field per-vertex in a dual-branch setup. In our simple non-parametric solution, the generated Peeled Depth maps are back-projected to 3D space to obtain a complete textured 3D shape. The corresponding RGB maps provide vertex-level texture details. We compare our method with current parametric and non-parametric methods in 3D reconstruction and find that we achieve state-of-theart-results. We demonstrate the effectiveness of our representation on publicly available BUFF and MonoPerfCap datasets as well as loose clothing data collected by our calibrated multi-Kinect setup.
Testing
Install environment
$ conda env create -f environment.yml
Download the checkpoint from here and store it in ./checkpoints/test/. The provided checkpoint was trained on the MonoPerfCap dataset.
Run the inference script
python test.py \
--test_folder_path <path/to/images/dir> \
--results_dir <path/to/results/dir> \
--name test \
--direction AtoB \
--model pix2pix \
--netG resnet_18blocks \
--output_nc 4 \
--load_size 512 \
--eval
The script looks for the checkpoint file in checkpoints/<checkpoint/name>
Citation
@inproceedings {jinka2020peeledhuman,
author = {S. Jinka and R. Chacko and A. Sharma and P. Narayanan},
booktitle = {2020 International Conference on 3D Vision (3DV)},
title = {PeeledHuman: Robust Shape Representation for Textured 3D Human Body Reconstruction},
year = {2020},
pages = {879-888},
doi = {10.1109/3DV50981.2020.00098},
publisher = {IEEE Computer Society},
}
Acknowledgements
Our network derives from the pix2pix work and hence builds on the official PyTorch implementation of pix2pix. This README template was borrowed from Aakash Kt. Please open an issue in case of any bugs/queries.
 53 Dec 4, 2022
53 Dec 4, 2022

 223 Dec 27, 2022
223 Dec 27, 2022

 1k Jan 9, 2023
1k Jan 9, 2023

 38 Oct 21, 2022
38 Oct 21, 2022
 117 Dec 28, 2022
117 Dec 28, 2022

 274 Jan 5, 2023
274 Jan 5, 2023
 15 Dec 22, 2022
15 Dec 22, 2022

 4 May 26, 2022
4 May 26, 2022
 450 Dec 28, 2022
450 Dec 28, 2022




 115 Jan 7, 2023
115 Jan 7, 2023
 66 Dec 21, 2022
66 Dec 21, 2022
 1.3k Jan 7, 2023
1.3k Jan 7, 2023
 30 Nov 18, 2022
30 Nov 18, 2022
 1 Aug 9, 2022
1 Aug 9, 2022
 166 Dec 28, 2022
166 Dec 28, 2022
 38 Nov 1, 2022
38 Nov 1, 2022
 42 Nov 24, 2022
42 Nov 24, 2022
 157 Dec 26, 2022
157 Dec 26, 2022
 59 Nov 25, 2022
59 Nov 25, 2022