Streaming Data Pipeline - Kafka + ELK Stack
Streaming weather data using Apache Kafka and Elastic Stack.
Data source: https://openweathermap.org/api
Objectives: Develop a streaming data pipeline to extract weather data from OpenWeather API using Apache Kafka, Logstash, Elasticserach and Kibana (Kafka + ELK Stack).
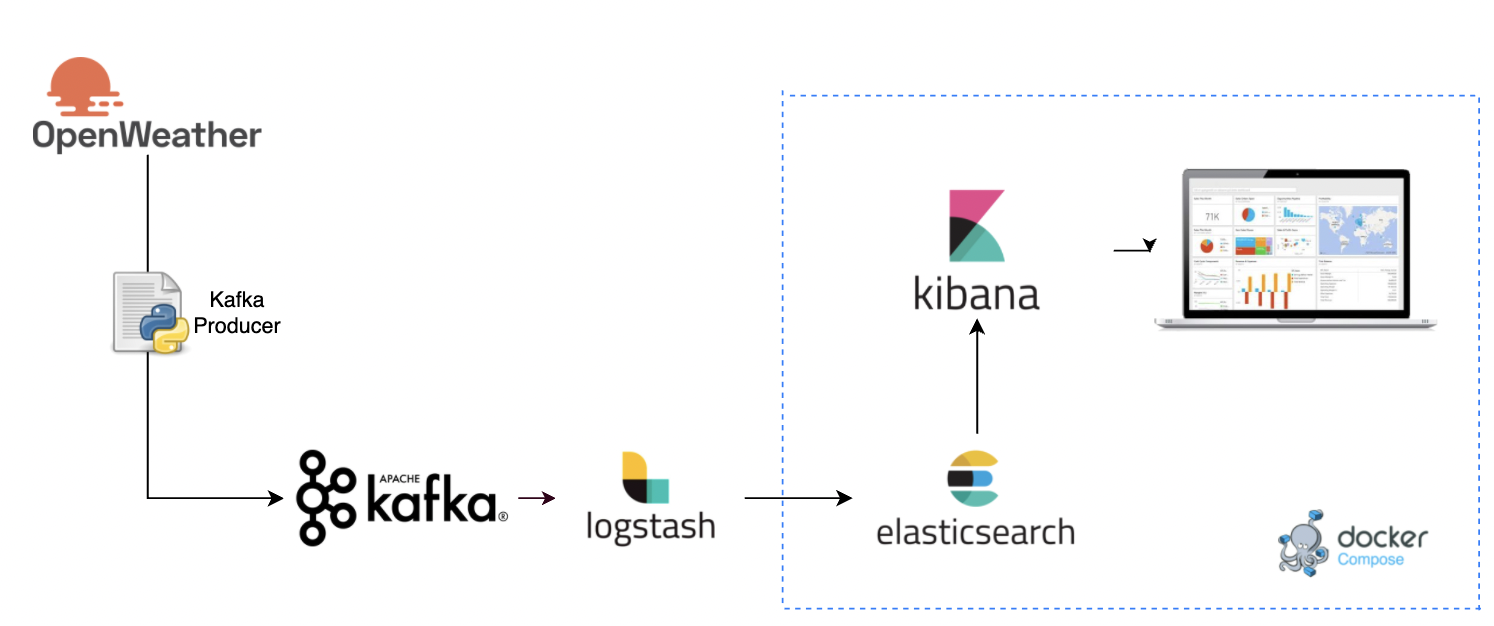
To summarize, Python was used to develop a Kakfa producer that requests weather data from OpenWeather API every minute and sends it as a message to Apache Kafka. Logstash, as a Kafka consumer, consumes the data and stores it into Elasticsearch. Kibana uses the data from Elasticsearch to display the dashboard.
Kibana Weather Dashboard

Steps:
bash elk/start_elastic_docker.shbash kafka/start_kafka_docker.sh- Create a topic using kafka manager:
localhost:9000
Logstash installed locally*
$LOGSTASH_HOME/bin/logstash -f $LOGSTASH_HOME/config/pipeline.conf
Before running Kafka Producer, is needed to set the API key inside the weather_api_key.ini file*
python3 weather_kfk_producer.py- Access Kibana:
localhost:5601 - Create an index pattern: must match with your index name inside
pipeline.conf - Develop your dashboard.
 1 Feb 11, 2022
1 Feb 11, 2022

 1 Dec 29, 2021
1 Dec 29, 2021

 1 Sep 5, 2021
1 Sep 5, 2021
 23 Dec 14, 2022
23 Dec 14, 2022

 25 Dec 14, 2022
25 Dec 14, 2022
 1 Nov 16, 2021
1 Nov 16, 2021

 97 Dec 8, 2022
97 Dec 8, 2022

 3.7k Jan 3, 2023
3.7k Jan 3, 2023

 898 Jan 9, 2023
898 Jan 9, 2023

 6 Sep 7, 2022
6 Sep 7, 2022
 5 Sep 28, 2022
5 Sep 28, 2022
 2 Dec 4, 2021
2 Dec 4, 2021
 1 Feb 4, 2022
1 Feb 4, 2022
 5 Nov 13, 2022
5 Nov 13, 2022
 2 Nov 20, 2021
2 Nov 20, 2021
 102 Nov 10, 2022
102 Nov 10, 2022
 1 Nov 22, 2021
1 Nov 22, 2021
 971 Dec 25, 2022
971 Dec 25, 2022
 1 Jan 6, 2022
1 Jan 6, 2022